
SDC#28 - Intro to Cell-based Architecture
Helm Chart with Kubernetes and Rate Limiter Design...

Hello, this is Saurabh…👋
Welcome to the 334 new subscribers who have joined us since last week.
If you aren’t subscribed yet, join 6300+ curious Software Developers looking to expand their system design knowledge by subscribing to this newsletter.
In this edition, I cover the following topics:
🖥 Cell-based Architecture
🎯 Helm Chart with Kubernetes
⏰ Rate Limiter Design
So, let’s dive in.
🖥 Cell-based Architecture
Would you like to board a ship that risks getting sunk from just one crack in its hull?
I guess not!
Ships mitigate this risk using the bulkhead approach, where vertical partition walls divide the interior of a ship into self-contained, watertight compartments. The idea is to ensure that a hull breach is contained within a section of the ship.
Turns out, you can borrow this concept while designing your application.
It’s known as cell-based architecture.
A cell-based architecture uses multiple isolated instances of a workload, where each instance is known as a cell. Each cell is independent, meaning that it doesn’t share the state with the other cells.
If there are 1000 requests to a workload and 10 cells to deal with those requests, each cell takes care of 100 requests. In case a cell goes down due to a failure, only 10% of the requests will be affected.
The below diagram demonstrates the concept of Cell-based architecture.
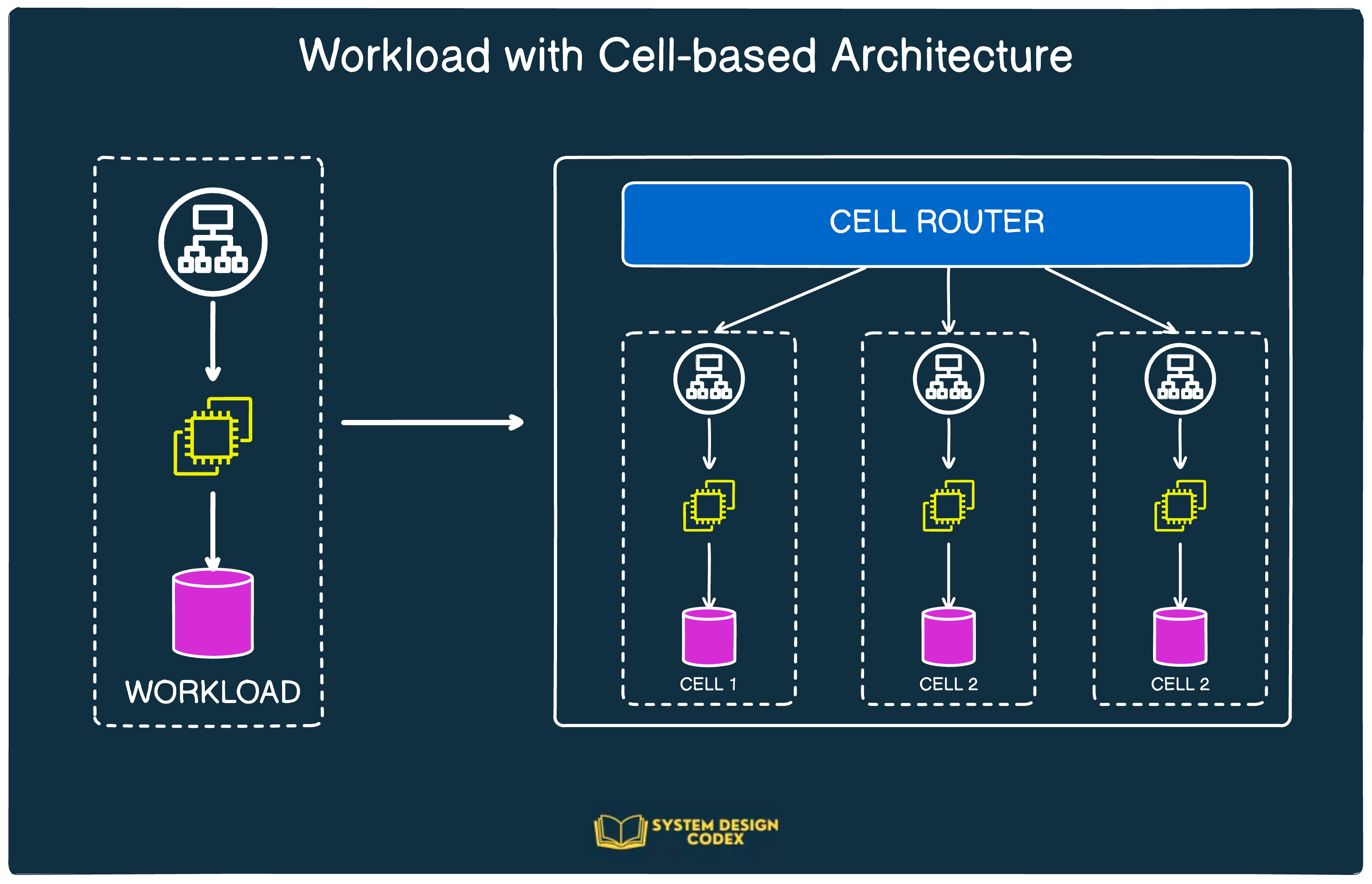
There are two main components in a cell-based architecture:
Cell - This is the complete workload that can operate independently
Cell router - A layer responsible for the task of routing requests to the right cell.
Based on how and where you deploy this type of architecture, you’ll have other components for provisioning cells and administering their lifecycle.
👉 This was just a brief intro to cell-based architecture.
Request you to answer the anonymous poll to show your interest in this topic and help improve System Design Codex.
🎯 Helm Charts with Kubernetes
If Kubernetes stands for Captain of a ship, then Helm is the wheel that steers the ship in the right direction.
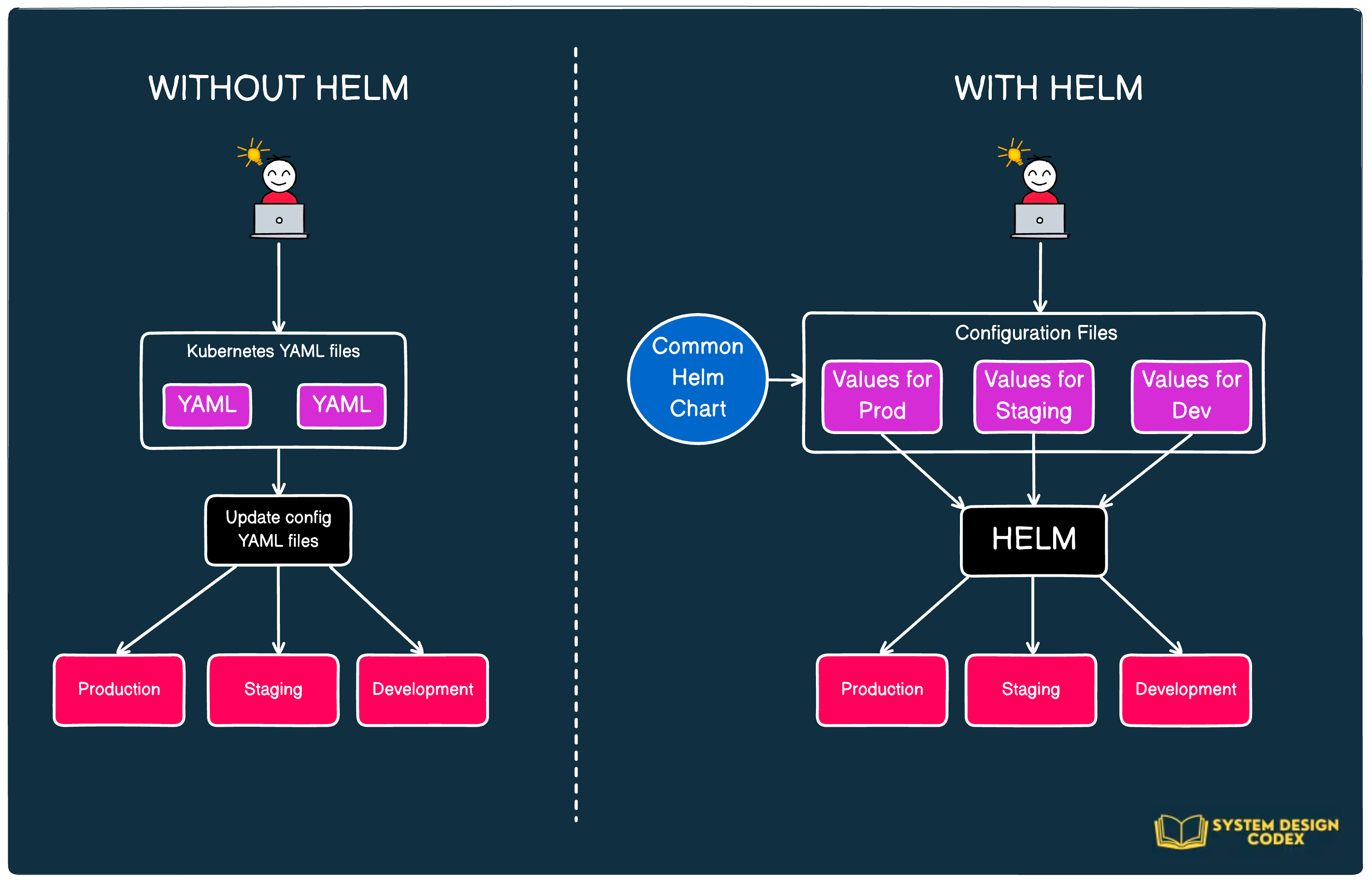
Helm automates the creation, packaging, configuration, and deployment of Kubernetes applications by combining the configuration files into a reusable package.
If you read an earlier deep dive into Kubernetes, you’d definitely be aware that we deploy applications to Kubernetes using YAML configuration files.

But what’s the use of Helm?
Let’s take a practical scenario.
Suppose you want to deploy your application in a prod environment with 5 replicas. With Kubernetes, you can specify this in the deployment YAML file and run the deployment using the kubectl command.
But what about other environments like staging, development and so on?
Maybe, in the staging environment, you only need 3 replicas to save costs. Or you have some different application properties. Also, you may be trying to deploy a different image tag.
In the Kubernetes way, you do this by updating the details in the YAML file and applying it in the staging or development cluster.
This might be fine for a small application. But as things get more complex, the number of YAML files can shoot up pretty fast. Also, you’ll likely have more configurable fields in the YAML files.
It’s not hard to see how managing and updating many YAML files can become a source of frustration.
With Helm, you can parameterize the fields depending on the environment.
Moreover, Helm charts allow you to manage Kubernetes manifests without using the Kubernetes CLI. These charts contain all the details about deploying an application on Kubernetes and you just have to update the configuration parameters. If you think about it, they are quite similar to using existing Docker images from Docker Hub.
The below diagram shows the scenario with and without Helm for easy comparison.
👉 This was just a brief intro to Helm and Kubernetes.
Request you to answer the anonymous poll to show your interest in this topic and help improve System Design Codex.
⏰ How Rate-Limiter Works?
Imagine trying to cook a delicate risotto, bake a perfect cake dripping with the right amount of chocolate and mix an intricately layered mojito at the same time.
You’ll likely fumble.
The same situation can happen with your application while trying to handle too many requests in a short amount of time.
How do you deal with this?
A rate limiter can help you out.
The basic premise of a rate limiter is quite simple. On a high level, you count the number of requests sent by a particular user, an IP address, or even a geographic location.
If the count exceeds the allowable limit, you disallow the request.
However, there are several questions to be answered if you try to design a rate limiter from scratch.
Where should you store the counters?
How to respond to disallowed requests?
Where should you store the rate-limiting rules?
How to ensure that changes in rules are applied?
How to ensure that rate limiting doesn’t degrade the performance?
To balance all these considerations, you need several pieces that work in combination.
The below diagram shows the various pieces:

So - what’s going on over here?
Incoming requests to the API server go to the rate limiter component.
The rate limiter fetches the rules from the rules engine.
Based on the rules, it checks the rate-limiting data stored within the cache. This data tells how many requests have already been served for a particular user or IP address (depending on the rule, of course)
The reason for using a cache is to achieve high throughput and low latency
If the request falls within the threshold, the rate limiter lets the request go through to the API server
If the request exceeds the limit, the rate limiter disallows the request and informs the client or user that they have been rate-limited. The HTTP status code 429 is ideal for this.
👉 This was just a brief intro to rate-limiting.
Request you to answer the anonymous poll to show your interest in this topic and help improve System Design Codex.
Round Up
To cap things off, here’s a roundup of some interesting articles I read recently:
Should you stay technical as an engineer manager by Nicola Ballotta: A very interesting article that talks about whether one should stay technical or hands-on as an engineer manager. It’s a valid question that pops up in every developer’s career sooner or later.
How to fix root issues by Tiger Abrodi: A super-quick read on the 5 WHYs that can help you identify the root of any issue.
How to Debug and Fix Software by Akos: Bugs in production! We’ve all been there at some point. But how should we debug and fix our code without making a mess? This article shows the path.
Richardson Maturity Model by Helen Sunshine: A complete roadmap for API development all the way from request to response to using HATEOAS.
That’s it for today! ☀️
Enjoyed this issue of the newsletter?
Share with your friends and colleagues.
See you later with another value-packed edition — Saurabh.
Thanks for the shoutout, Saurabh! 🙌 When I read Cell-based Architecture, I instantly thought of load balancing. How do the two compare? Would load balancing, like Elastic Load Balancing on AWS, be a type of cell-based architecture?
Helm chart with K8s, what a powerful combo, enabling zero-downtime deployments. Great post my friend!