
SDC#25 - Practical Intro to Kubernetes
The Architecture, Most Important Services and More...

Hello, this is Saurabh…👋
Welcome to the 826 new subscribers who have joined us since last week. This has been an incredible week for the newsletter in terms of growth. Thanks for all the love and support!
If you aren’t subscribed yet, join 4700+ curious Software Developers looking to expand their system design knowledge by subscribing to this newsletter.
In this edition, I cover the below topics
🖥 System Design Concept → Practical Intro to Kubernetes
🍔 Food For Thought → Dealing with the Bus Factor
So, let’s dive in.
🖥 What is Kubernetes?
When containerization became quite popular, everyone started to adopt it for deploying their application.
Soon, the idea of containerizing applications was projected as a solution to all your developer-life problems.
Local development issues? Containerize the application.
Deployment problems? Just deploy your app as a container
Can’t test your application? Use a container.
However, containers are only one part of the puzzle.
Once you have too many containers in a large application, managing them becomes a nightmare.
And that’s where Kubernetes steps into the picture.
Kubernetes is a piece of software that lets you orchestrate a bunch of containers.
But what does orchestration really mean?
It covers everything in the life cycle of containers - starting, managing, and stopping them when needed.
Here are a few quick points to consider:
A Kubernetes cluster can easily manage thousands of containers.
It abstracts the infrastructure details from the developers. In other words, fewer things to think about for developers.
It simplifies deployments as developers can simply declare what they want and Kubernetes does the rest.
In case you are still doubtful about the abilities of Kubernetes, here’s a quote from Kelsey Hightower (author of Kubernetes Up and Running)
Kubernetes does the things that the very best system administrator would do: automation, failover, centralized logging, and monitoring. It takes what we’ve learned in the DevOps community and makes it the default, out of the box.
That’s a very strong value proposition and one of the reasons why Kubernetes became so popular within the industry.
How do Developers see Kubernetes?
For application developers working with Kubernetes, it’s typically a 3-step process:
STEP 1 - The developers create manifest files for their applications and submit those files to Kubernetes.
STEP 2 - Kubernetes checks those files and deploys the necessary applications to its cluster of worker nodes.
STEP 3 - Kubernetes manages the complete lifecycle of the applications based on the manifest files.
Here’s what it looks like from a pictorial point of view:

For developers, this abstraction is great news because they don’t have to worry about the deployment environments.
All they have to do is create those manifest files for their applications.
For example, if you want two instances of Application A, four instances of B, and so on, you can simply mention it in the manifest files. Kubernetes will make sure that the desired state is achieved and maintained.
Kubernetes - Behind the Scenes
While an application developer doesn’t often need to get into the bells and whistles of Kubernetes internals, you can still be tested on this in an interview scenario.
Therefore, having a basic understanding of the Kubernetes architecture helps set you apart from other candidates.
Kubernetes is deployed as a cluster. It has two main parts:
The Master Node
Worker Nodes
The below diagram shows the high-level architecture of a Kubernetes cluster.

Master Node
This node hosts the Kubernetes Control Plane - the entity that controls the entire cluster.
Think of it as a manager in an organization.
The control plane consists of several important parts:
The Kube-apiserver acts as an entry point to the K8S cluster.
A scheduler that assigns a particular deployment to a worker node
Controller Manager for tracking the nodes and handling failures
etcd for storing the cluster’s configuration
Worker Nodes
There are multiple worker nodes controlled by a single master node. They are the infrastructure pieces that host the containerized applications.
Think of them as employees under a manager.
A worker node is made up of the following components:
A container runtime such as Docker or rkt.
Kubelet for talking to the API server and managing containers. Basically, the kubelet makes sure that the node is operating according to the configuration.
kube-proxy for communication of pods within the cluster and to the outside network.
Top Kubernetes Resources
If you are a developer looking to work with Kubernetes, you’d most likely have to deal with different types of resources.
While Kubernetes has a ton of resources, I’ve seen that these 4 resources are probably the most used and important.
Let’s look at them one by one.
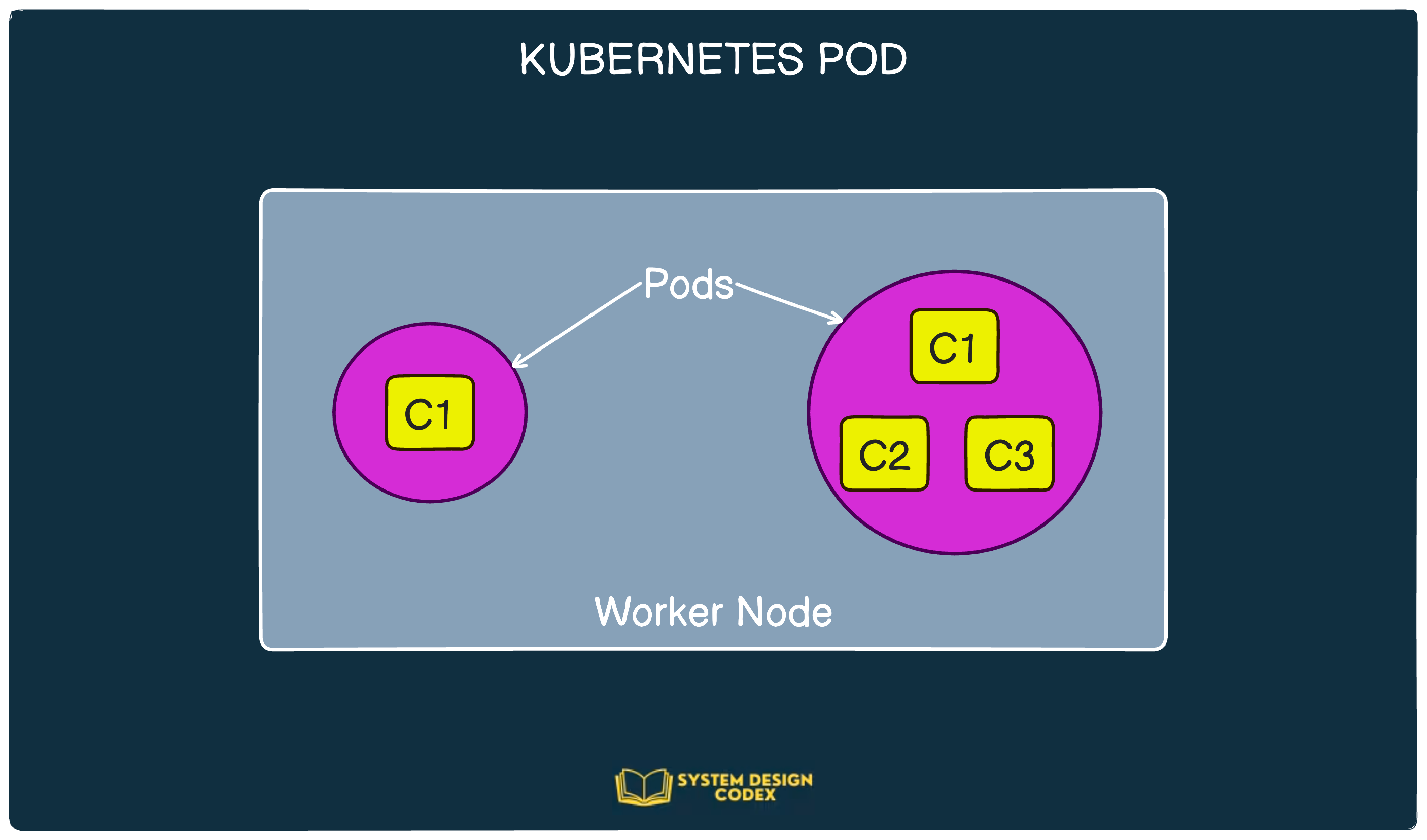
1 - Pods
Pods are the smallest atomic unit that you create in Kubernetes.
Aren’t pods the same as a container?
Not exactly.
Kubernetes groups multiple containers into a single unit known as a Pod. These pods are deployed on the worker nodes we talked about earlier.
In the animal kingdom, pods are meant to signify a group of whales. This gels nicely with the whole whale theme associated with Docker containers.
Basically, a Kubernetes pod represents a collection of containers and volumes running within the same execution environment.
This concept of “same execution environment” is very important. It means you can use pods to run closely related processes that need to share some resources, but also keep these processes isolated from each other.
Is this the best of both worlds?
Not so fast.
While multi-container pods have their uses, the common consensus is to have 1 container per pod unless needed otherwise.
This approach makes it easy to scale an application without worrying about multiple processes.
As I mentioned earlier, every Kubernetes resource is described using a manifest file.
Here’s a manifest file to declare a very simple pod.
apiVersion: v1
kind: Pod
metadata:
name: basic-pod-demo
spec:
containers:
- image: systemdesigncodex/nodejs-demo
name: hello-serviceSome important points to note over here:
The
kindis the type of resource.In the
metadatasection, thenamefield contains the name of the pod.Within the
specsection, you can provide details about the containers that are going to be part of the pod. In this example, there’s only one container using theimagenamedsystemdesigncodex/nodejs-demo.Lastly, we have the
nameof the container.
To create a Kubernetes resource in your cluster, you use the kubectl command. Once the resource (such as pod is applied), use kubectl to check the status.
$ kubectl apply -f <file-name>.yaml
$ kubectl get po2 - Services
Kubernetes is an ideal platform to deploy microservices.
One microservice per pod is the usual way to go when dealing with microservices.
However, microservices often need to talk to each other to carry out their functionalities. This means that the pods need a way to find other pods within the cluster.
This is where Kubernetes Services act as life savers.
Let’s take a typical example of an application that has a frontend web application and a backend database server.
You may deploy the frontend web application on multiple pods for horizontal scalability. However, the database server is deployed on a single pod.
There are two requirements for such a system:
External clients need to connect to the frontend pods without worrying about the pod IP addresses.
Frontend pods need to connect to the backend database. Though the database is deployed on a single pod, there are chances it may move around the cluster causing a change in its IP address. You don’t want to reconfigure the frontend pods every this happens.
Both of these requirements can be easily handled by using a Kubernetes service.
You create one Kubernetes service for the frontend pods that makes the application accessible from outside the cluster. It’s a constant IP address through which external clients connect to the pods. The service also acts as a load balancer to distribute traffic across multiple instances.
Similarly, a new service for the backend database pod that gives it a stable address that doesn’t change when the pod is moved around the cluster’s nodes (due to failures or restarts).
The below diagram shows the big picture view of Kubernetes Service:

Here’s the YAML file to create a simple Kubernetes Service resource:
apiVersion: v1
kind: Service
metadata:
name: basic-service
spec:
ports:
- port: 80
targetPort: 3000
selector:
app: hello-serviceThe port mapping is important over here:
The
portattribute is the service portThe
targetPortis the port exposed by your application container. For example, a webserver running on port 3000.
3 - Deployment
A Kubernetes Deployment is a higher-level resource you can use for deploying applications and updating them declaratively.
When you create a Deployment, a ReplicaSet resource is also created under the hood to control the pods.
What does a ReplicaSet do?
It lets you create multiple pods for the same application. Think about horizontally scaling your application.
A Deployment sits on top of the ReplicaSet, making sure that the latest version of your app is always running on the desired number of pods.
Check out the below diagram for reference.

Also, here’s an example for the Deployment YAML file.
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: progressivecoder/nginx
name: nginx
ports:
- containerPort: 80Notice the value of the replicas parameter in the spec section. It tells Kubernetes how many pods need to be created for the nginx container.
The rest of the YAML is quite similar to the pod YAML.
Note that if you deploy pods using a Deployment, you don’t need to create separate YAML files for pods. Neither do you need to create a separate ReplicaSet resource.
4 - Volume
Kubernetes volumes are a component of a pod and not a standalone object.
But what is the use of volumes?
Think of them as a form of storage.
In certain scenarios, you may want the application to persist some data to the disk.
However, applications run within containers on the pod. But if a container goes down, its file system also gets wiped out. The new container doesn’t see anything that was written by the previous container even though it might be running in the same pod.
Kubernetes volume solves this problem because the contents of a volume will persist across container restarts. Also, the volume can be accessed by all the containers running within a pod.
Check the below diagram that shows the concept of a Kubernetes Volume.

So - how to define a Kubernetes Volume?
You declare them as part of the Pod YAML or within the Deployment YAML.
See the below example where we add Volume to the Deployment YAML:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: systemdesigncodex/sidecar
name: sidecar
env:
- name: STATIC_SOURCE
value: https://raw.githubusercontent.com/dashsaurabh/sidecar-demo/master/index.html
volumeMounts:
- name: shared-data
mountPath: /usr/share/nginx/html
- image: systemdesigncodex/nginx
name: nginx
ports:
- containerPort: 80
volumeMounts:
- name: shared-data
mountPath: /usr/share/nginx/html/
volumes:
- name: shared-data
emptyDir: {}Some important points about the above YAML:
The
volumessection at the very bottom declares a volume of typeemptyDir. What it means is that volume starts as an empty directory. It is given the name “shared-data”The app running inside the pod can write any files it needs to the empty directory.
In the above example, the
emptyDirvolume is used for sharing files between the “sidecar” container and the “nginx” container.Within the containers section, the volume “shared-data” is mounted at
/usr/share/nginx/htmlusing thevolumeMountssection. The mounting is done for both the containers enabling them to share the data.When the pod is destroyed, the volume is also destroyed along with it.
Conclusion
That’s all for now!
This was a brief practical introduction to help you understand what Kubernetes is, how it works under the hood, and some of the most basic resources you can create using Kubernetes.
Give the post a like and share any comments if you’d like to learn more about Kubernetes in future editions.
🍔 Food For Thought
👉 Dealing with the Bus Factor
“How many people need to be hit by a bus before the project is in serious trouble?”
This is an extremely important point to consider for any project team.
But this factor can also impact your own career progression.
Want to know how?
Check out this wonderful insight by Helen Sunshine.

Here’s the link:
https://x.com/Sunshine_Layer/status/1746613632803242133?s=20
That’s it for today! ☀️
Enjoyed this issue of the newsletter?
Share with your friends and colleagues
See you next week with another value-packed edition — Saurabh
What an awesomely detailed post, great job, my friend! K8s is one of the most exciting tech out there! Together with Helm charts, it makes a really powerful combo, enabling for example zero downtime deployments.
An amazing post Saurabh. Haven't read such a detailed and no non-sense post on k8s for the first time. Keep up 👍