
How LinkedIn Uses Caching to Serve 5M Profile Reads/Sec?
Couchbase Cache, Espresso and Brooklin

5000000 profile reads per second!
That’s what LinkedIn managed to handle at its peak.
As remarkable as that number may sound, they also did it with style:
The cache hit rate was over 99%. That means 4950000 of those profile reads were served from the cache.
Tail latency (the latency that can have a big impact) was reduced by more than 60%
Costs were down by 10%
All of this was made possible by a neat combination of Couchbase cache, Espresso (not the coffee) data store, and Brooklin CDC.
Let’s find out how.
The Architecture
Here’s how profile reads used to work at LinkedIn once upon a time—before the whole business of introducing the Couchbase cache:

What’s going on over here?
When someone tried to view a profile on LinkedIn, the Profile frontend application sent a read request to the Profile backend.
The Profile backend fetched the data from Espresso (LinkedIn’s in-house NoSQL database) and returned it to the frontend application. It also performed some deserialization stuff but let’s ignore that for now.
This solution also had a cache. Yes, the off-heap cache (OHC) on the Espresso Router.
The OHC is quite efficient for hot keys but limited in scope. It had a low cache hit rate because it was local to the router instance and could only see read requests for that instance.
Anyway, this solution worked fine till a certain point. But once they had scaled it to the limit, adding more Espresso nodes gave diminishing returns.
That’s the thing with horizontal scalability. It can take you far but no strategy can scale infinitely. Ultimately, the strategy becomes cost-ineffective and you’ve to look for other ways to go further.
So, what did LinkedIn do?
They built a new architecture for profile reads. Here’s how it looked:
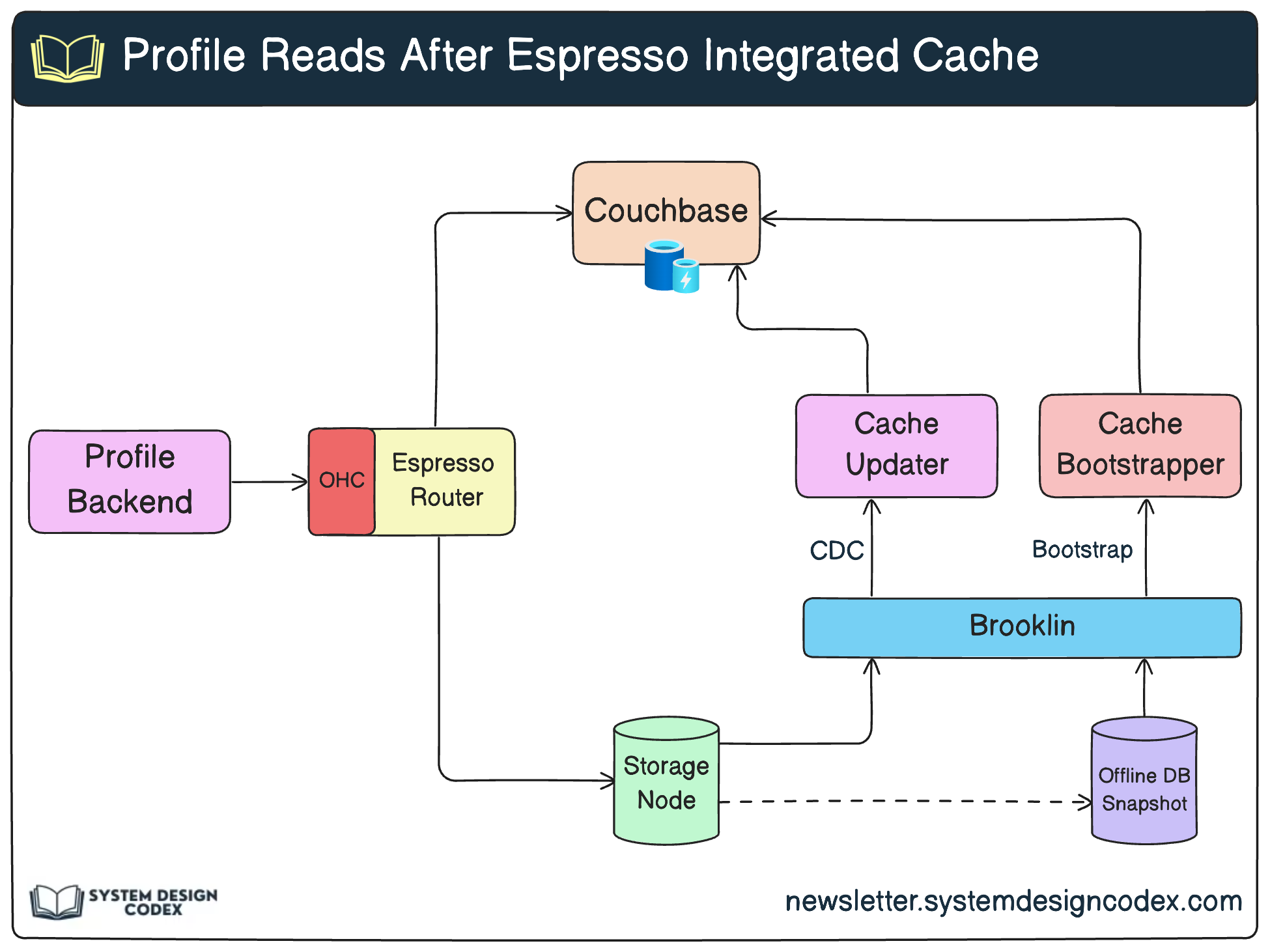
What changed?
The first thing to note is the Couchbase cache. It sits aside from the Espresso storage node.
There is a Cache Updater and a Cache Bootstrapper.
Lastly, there is Brooklin which is LinkedIn’s in-house data streaming platform.
One major advantage of this setup is that Espresso abstracts all the caching internals and frees the developers to focus on the business logic. Hence the name Integrated Cache.
A point to note was that LinkedIn initially tried to adopt memcached but the solution didn’t work well for them. Interestingly, Facebook was able to achieve massive success with memcached as we saw in an earlier post.

It shows that different companies can get vastly different results from the same tool based on their environment.
So - how does the new architecture work?
The Read Path
When the Profile backend application receives a read request, it sends the request to an Espresso router instance.
The router checks if the key is present in the OHC.
If not, the request is sent to the Couchbase cache. In case of a cache hit, the data is returned.
In case of a cache miss, the request is served by the storage node. The router returns the profile information to the backend
Lastly, the router upserts the data asynchronously into the cache.

The Write Path
A cache becomes ineffective when the data in the database changes but it’s not synced with the cache.
To keep things in sync, they implemented a cache updater and cache bootstrapper.
Both of them consume Espresso change events from two Brooklin streams and upserts the data into the Couchbase cache:
The Brooklin change capture stream is populated with database rows committed to the database
The Brooklin bootstrap stream is populated with a periodically generated database snapshot.

Cache Design Requirements for Scalability
The architecture may look cool. But it wouldn’t have mattered much unless it scaled to the level LinkedIn wanted.
To achieve the necessary level of scalability, they had to fulfill three critical requirements:
Guaranteed resilience in case of Couchbase failure.
High-availability of cached data
A strict service level objective on data divergence between the SOT and the cache.
Resilience for Couchbase Failures
Resilience against Couchbase failures is critical because the alternative is to fall back to the database.
A few solutions they implemented to ensure this:
Every Espresso router instance tracks the health of all Couchbase buckets it has access to. A bucket’s health is evaluated by comparing the number of request exceptions against a threshold. If a bucket is unhealthy, the router stops dispatching new requests to the bucket.
They went with 3 replicas for profile data (a leader and two followers). Every request is fulfilled by the leader. However, if the leader goes down, the router fetches data from the follower replica.
Retrying failed Couchbase requests in case the reason for failure was a router issue or a network issue. The idea is that such issues may be temporary and a retry may be successful.
High-Availability of Cached Data
Cached data must be available all the time even in the case of a datacenter failover.
To achieve this, they cache the entire Profile dataset in every data center. It was easy for them because a typical profile payload just comes to around 24KB.
The TTL (Time-to-Live) for the cached data is set to a finite value to make sure any expired records get purged from the database.
Minimizing Data Divergence
Multiple systems write to the Couchbase cache.
You have the Espresso Router, the Cache Bootstrapper, and the Cache Updater. Race conditions between them could lead to data divergence between the Cache and the database.
To prevent this, the LinkedIn engineering team implemented several solutions:
1 - Ordering of Updates
Cache updates for a given key are ordered using a logical timestamp known as System Change Number (SCN).
For each database row committed, Espresso produces a SCN value and stores it in the binlog. The system follows the Last-Writer-Win (LWW) reconciliation based on the SCN value.
In other words, the record with the largest SCN replaces the existing one in Couchbase.
2 - Periodic Bootstrapping of Cache
They periodically bootstrap the Couchbase cache to prevent it from becoming cold.
As we saw earlier in the architecture section, this is done via the Brooklin bootstrap stream.
The bootstrapping period is kept less than the TTL to make sure that a record present in Espresso doesn’t expire from the cache before the next bootstrapping.
3 - Handling Concurrent Modifications
Concurrent modifications can occur when routers and cache updaters try to update a cache entry.
To handle this, they use Couchbase Compare-And-Swap (CAS) to detect concurrent updates and retry the update if necessary. Here’s how it works:
The CAS value is typically stored alongside the data within the Couchbase server.
When you read data from Couchbase, the CAS value is returned with the data.
Then, when you perform an update operation on that data, you include the CAS value in the request.
If the CAS value you provide is different from the one in Couchbase, it indicates that the data has been modified by another operation.
In this case, you can retry the update request or handle it accordingly.

Impact of the New Solution
The adoption of the Espresso-integrated Couchbase cache allowed LinkedIn to achieve its goals of supporting a growing member base.
Some stats revealed by LinkedIn to support this claim are as follows:
Reduction in the number of Espresso storage nodes by 90%.
Annual 10% cost savings on servicing member profile requests
99th percentile latency dropped by 60.73% from 31.6 ms to 12.41 ms.
99.9th percentile latency dropped by 63.66% from 66.87 ms to 24.3 ms.
So - what do you think about LinkedIn’s integrated cache solution?
The reference for this article comes from the LinkedIn engineering blog.
Shoutout
Run Meetings Like a Pro by Raviraj Achar: A cool post on how to prepare for different types of meetings most effectively.
The biggest obstacle stalling your career growth by Helen Sunshine: Lessons from Black Swans and the importance of continuous learning for a developer.
Why Amazon’s culture makes me a better engineer by Fran Soto: Applying Amazon’s leadership principles to become a better engineer.
Developers are on edge by DHH: A very realistic take on the whole recent development around AI Software Engineer (Devin)
That’s it for today! ☀️
Enjoyed this issue of the newsletter?
Share with your friends and colleagues.
See you later with another value-packed edition — Saurabh.
Thanks for the shoutout, Saurabh.
Interesting the CAS to ensure you can retry as a client starting from the very beginning
amazing post. thanks Saurabh!
For minimizing data divergence during concurrent updates, I really liked the idea of CAS (compare and swap). I had read about it in context of operating systems. It was nice to know how its used in distributed systems.