
Top Microservices Patterns
The ones that are most common

Building microservices isn’t easy.
Even in the best of times, you might end up in a mess.
But if you’ve to build microservices for some reason, it’s better to know some patterns that can make your life easy.
Here are 4 must-know patterns for building microservices:
Database Per Service
As the name suggests, this pattern proposes that each microservice manages its own data.
This implies that no other microservice can directly access or manipulate the data managed by another microservice.
Any exchange or manipulation of data can be done only by using a set of well-defined APIs.
The figure below shows an example of a database-per-service pattern.
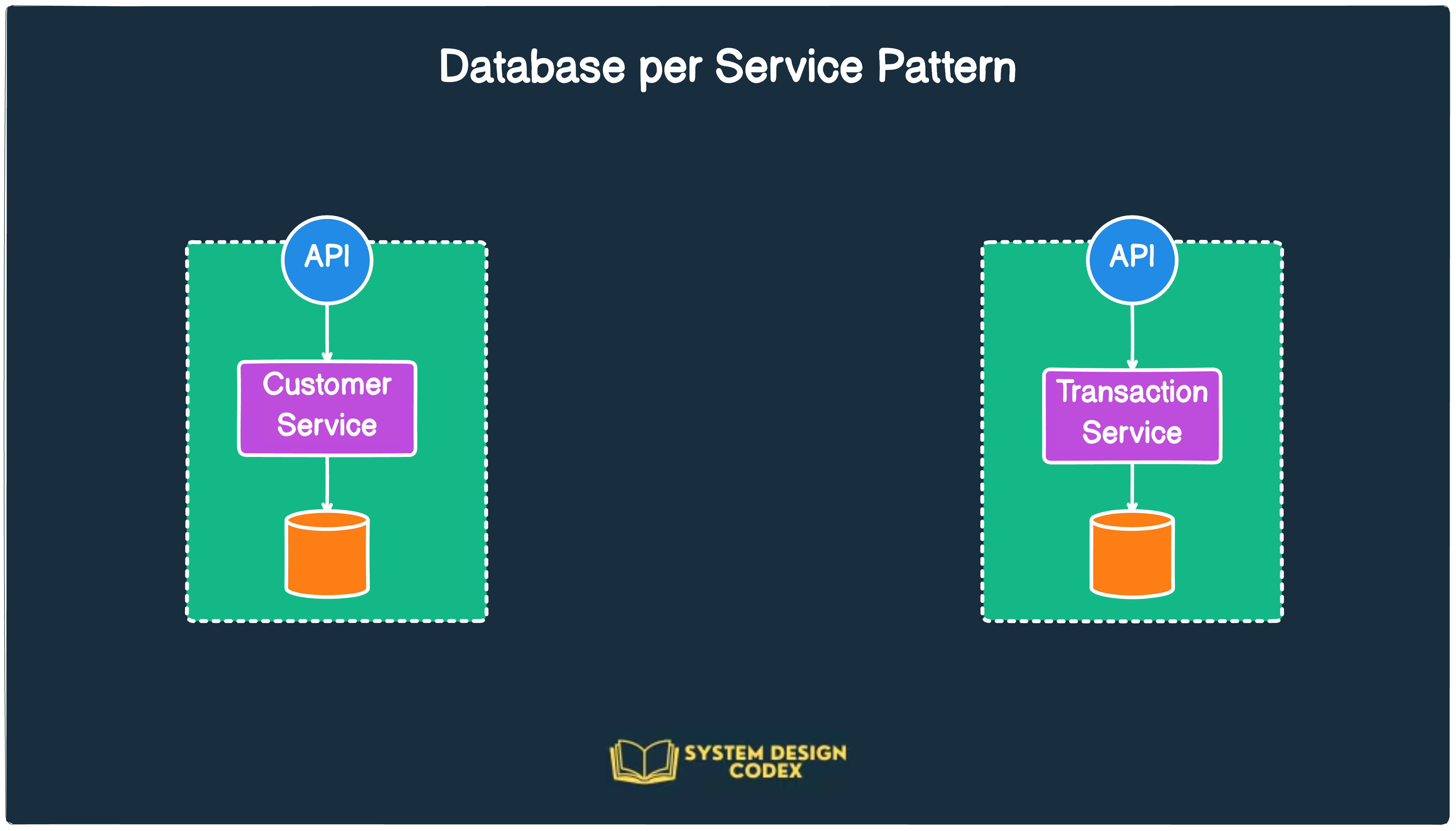
At face value, this pattern seems quite simple. You can implement it relatively easily when you are starting a brand-new application.
However, when you are trying to migrate an existing monolithic application to a microservices architecture, the demarcation between services is not so clear.
Most of the functionality is written in a way where different parts of the system access data from other parts informally.
Two main areas that you must focus on when using a database-per-service pattern are:
Defining bounded contexts for each service.
Managing business transactions spanning multiple microservices.
Shared Database
The next important pattern is the shared database pattern.
Depending on how you are looking at things, this might also sound like an anti-pattern.
That’s because this pattern adopts a much more lenient approach by using a shared database accessible to multiple microservices.
Here’s what it looks like in practice:
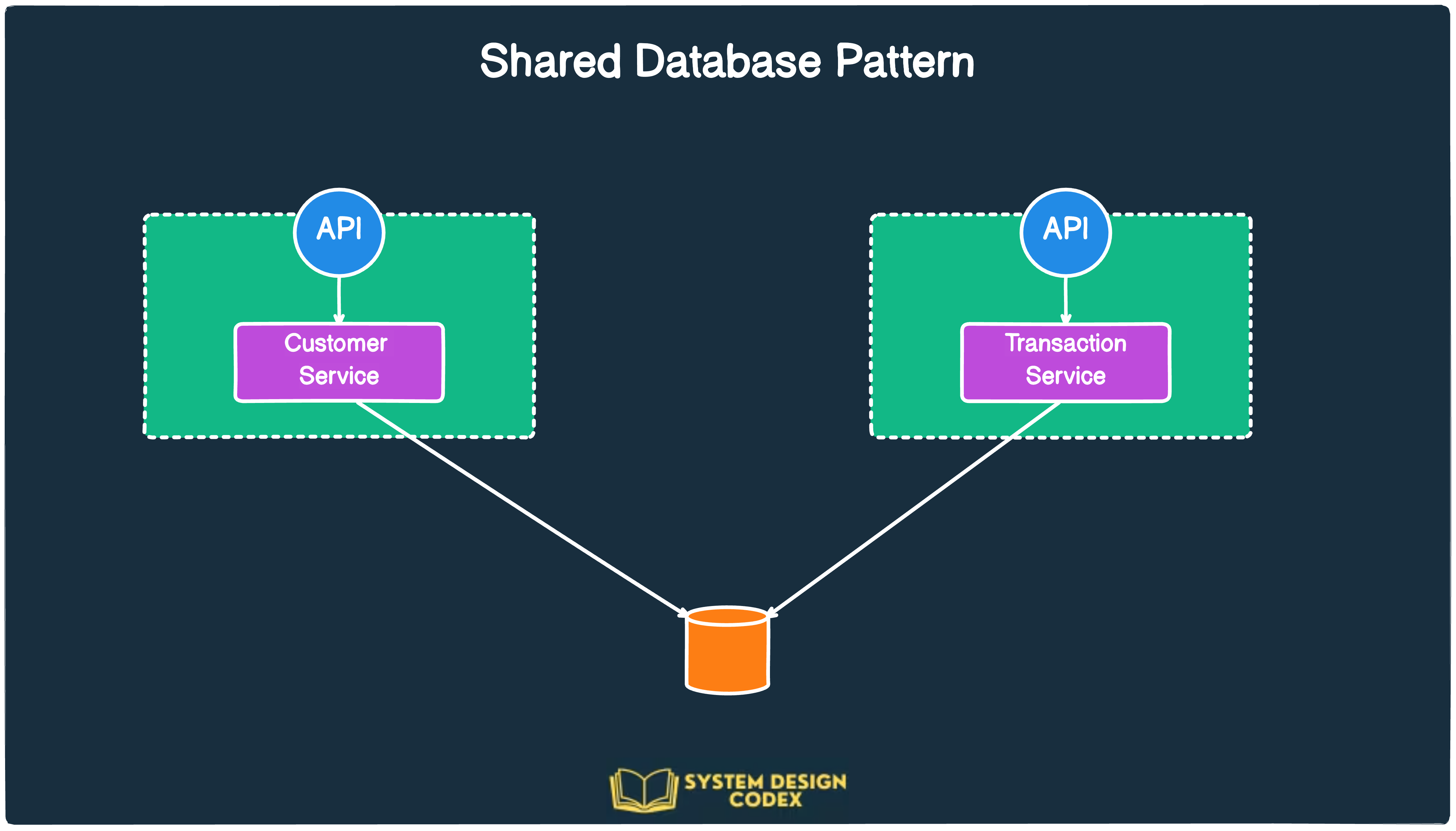
For existing applications transitioning to a microservices architecture, this is a much safer pattern as we can slowly evolve the application layer without changing the database design.
However, this approach takes away some key benefits of microservices.
Developers across teams need to coordinate schema changes to tables
Runtime conflicts may arise when multiple services are trying to access the same database resources.
Thanks for reading System Design Codex! Subscribe for free to receive new posts and support my work.
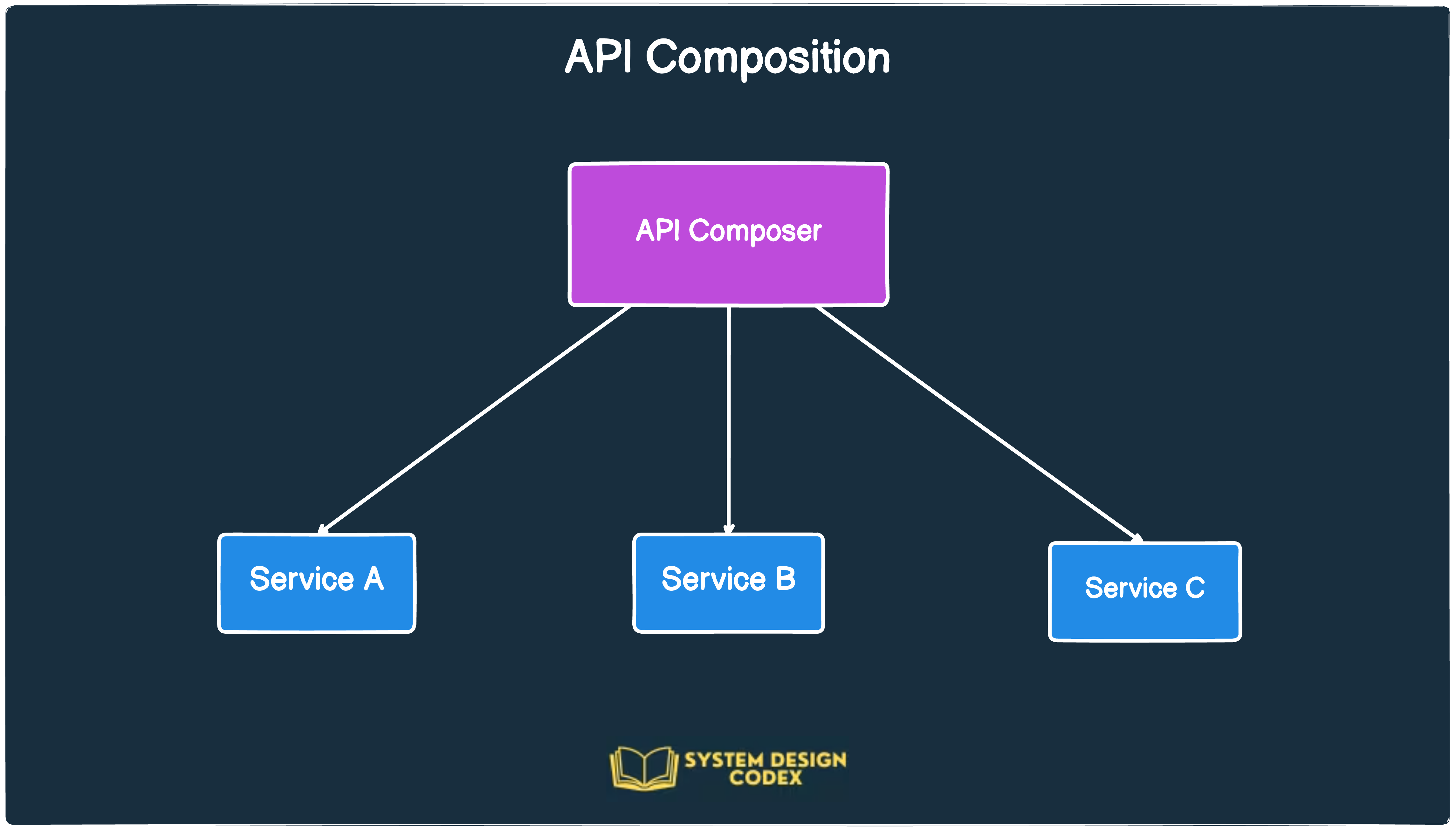
API Composition
The API Composition pattern attempts to solve the problem of implementing complex queries in a microservices architecture.
An API composer invokes other services in the required order. After fetching the results, it performs an in-memory join of the data before returning it to the caller.
However, this is an inefficient approach due to in-memory joins on potentially large datasets.
Check the illustration below:
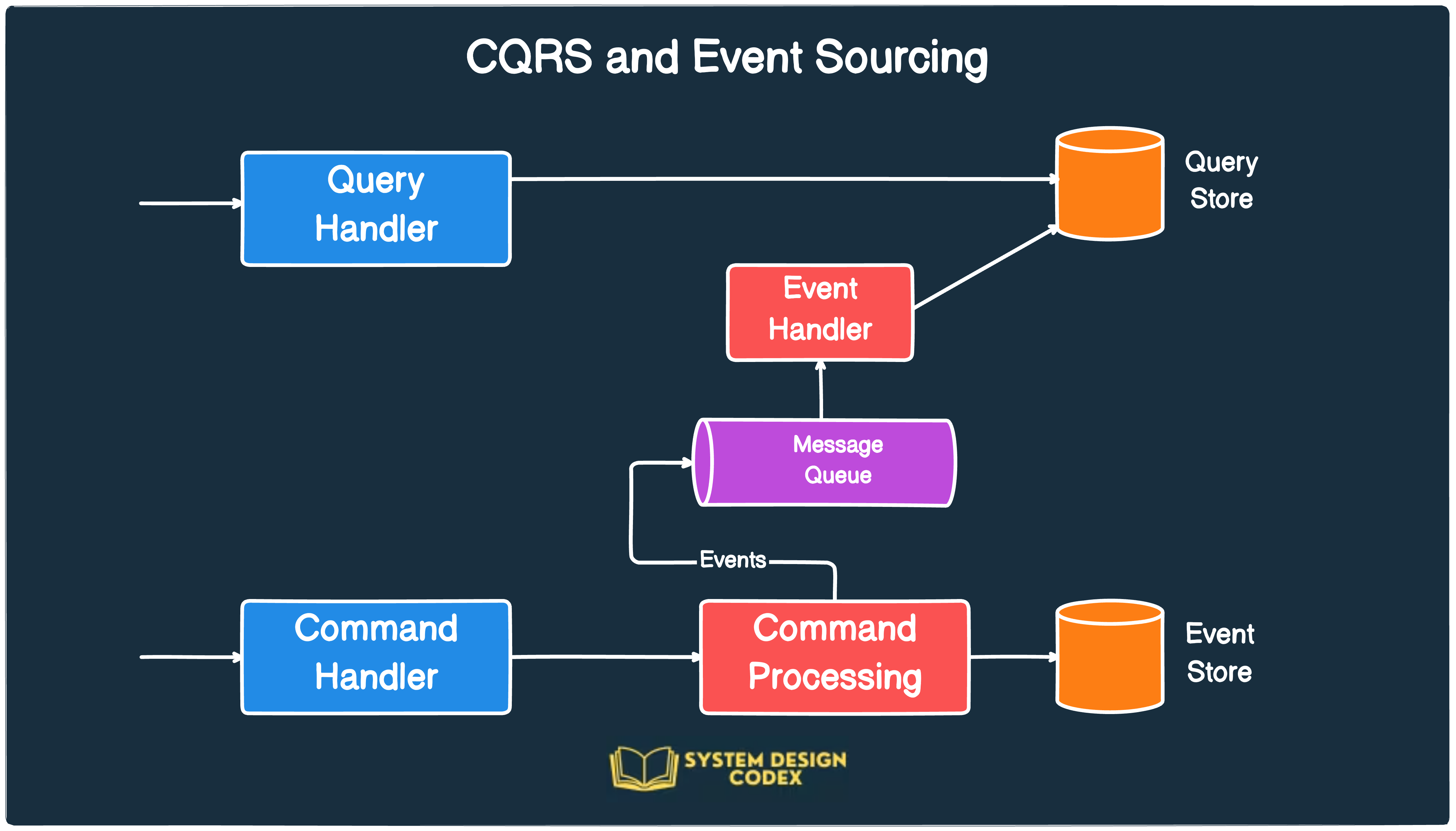
CQRS and Event Sourcing
CQRS stands for Command Query Responsibility Segregation.
In the CQRS pattern, an application listens to domain events from other microservices and updates a separate database for supporting queries and views.
You can then serve complex aggregation queries from this separate database while optimizing the performance and scaling it out as needed.
Event Sourcing takes it a bit further by storing the state of the entity or the aggregate as a sequence of events.
Whenever there is an update or an insert on an object, a new event is created and stored in the event store.
You can use CQRS and Event Sourcing together to solve a lot of challenges around event handling and maintaining separate query data. This way, you can scale the read and writes separately based on specific requirements.
On the downside, this is an unfamiliar style of building applications for many developers and there are also multiple moving parts to manage.
Check out the illustration below that shows CQRS and Event Sourcing together.
So - have you used any of these patterns?
Shoutout
Here are some interesting articles I read this week:
2-Tier to 3-Tier Architecture: Migration Journey With Modular Monolith and GraphQL by Petar Ivanov
Essential Skills for Engineers to Thrive in the AI Era by Gregor Ojstersek
That’s it for today! ☀️
Enjoyed this issue of the newsletter?
Share with your friends and colleagues.
yes i have used shared database system
Shared database, almost always.
I don't know if it's the size of the project I've worked on, or that usually they were monoliths and we started extracting services, but the shared DB approach always seemed simple.
It was relatively small overhead and code as well. And it didn't give us extra maintenance.