
SDC#6 - Strategies to Share Code Between Services
Uber Eats versus Duplicate Images and More...

Hello, this is Saurabh…👋
Welcome to the 58 new subscribers who have joined us since the last edition.
If you aren’t subscribed yet, join 600+ curious developers looking to expand their knowledge by subscribing to this newsletter.
In this issue, I cover the following topics:
🖥 System Design Concept → Sharing Code Between Services
🧰 Case Study → Uber Eats vs Duplicate Images
🍔 Food For Thought → System Design is For Everyone
So, let’s dive in.
🖥 Sharing Code Between Services
Sharing code between multiple services is a hotly debated topic in software engineering.
You have some people fighting tooth and nail to prove that DRY (Don’t Repeat Yourself) is the way to go.
Then there are the proponents of the “share nothing” philosophy, ready to engage in mortal combat to prove their point.
Between this battle are normal developers wondering how they should go about reusing code.
What if I told you that you don’t need to participate in any battle?
Your job - as a developer - is to build maintainable software without engaging in flame wars about patterns and methodologies.
Here are 4 strategies for sharing code that can help you build better applications:
Strategy#1 - Code Replication
In this strategy, shared code is copied into each service.
Basically, you are completely avoiding code sharing.
Here’s what it looks like:

Though it might seem like an ugly hack now, this technique was quite popular in the initial days of the microservices architecture.
And you can even use it now in certain contexts. At worst, you might find it being used in your existing applications and have to deal with it.
For most new cases, however, I wouldn’t recommend using this technique.
Imagine finding a bug in the shared code. Or the need to make an important change to that code.
You will need to update all the services containing the replicated code.
No matter how hard you try, you’d probably miss updating some services resulting in issues.
Strategy#2 - Shared Library
A shared library is the most common technique for reusing code.
A shared library is an external artifact. Think of a JAR file, DLL or NPM package that contains the common source code.
You can just include this shared library in a particular service and make use of the packaged functionalities.
Here’s an illustration that shows this particular arrangement.

The main advantage of this approach is that the shared library gets bound to the service at compile-time.
This makes it easier to spot issues during development and testing.
Strategy#3 - Shared Service
The main alternative to the shared library approach is the shared service approach.
In this strategy, you extract all the common functionality into a shared service.
Here’s what it looks like:

With this technique, you basically avoid code reuse by placing the common functionality into a separate service with its own deployment path.
But there are a few important trade-offs with this approach such as:
Change Risk
Performance
Scalability
Strategy#4 - Sidecars
An application typically consists of two types of functionalities:
Domain
Operational
With domain functionalities, we want to go for loose coupling.
However, operational functionalities such as logging, monitoring, authentication, and circuit breakers do much better with a high-coupling implementation.
You don’t want each service team to reinvent the wheel for operational functionalities.
Also, there is often a need for standardized solutions across the organization.
To share operational functionalities across multiple services, you can use the Sidecar pattern.
See the below illustration:

In this setup, every service includes the sidecar component that takes care of the operational functionalities.
All of this is managed using some sort of infrastructure piece such as Kubernetes or a service mesh.
Of course, it is important to ensure that we don’t end up reusing domain functionalities with the sidecar.
Also, there is a risk that the sidecar component may grow too large or complex.
We already spoke about the Sidecar pattern in an earlier post. You can check it out for more details.
<link>
🧰 Uber Eats vs Duplicate Images
Uber Eats handles millions of product images every single hour.
That’s an insane scale when you think about it.
At this scale, duplicate images can burn a hole through your pocket in multiple ways:
Increased processing costs
Greater storage costs
Higher CDN costs
Not handling duplicate images is like not fixing the leak in your boat while traveling through the ocean. Sooner or later, the boat is going to sink.
So, how does Uber Eats deal with duplicate images?
The first solution was quite basic. It involved 3 simple steps:
downloading
processing
and storing the image URLs
Check out the below illustration:
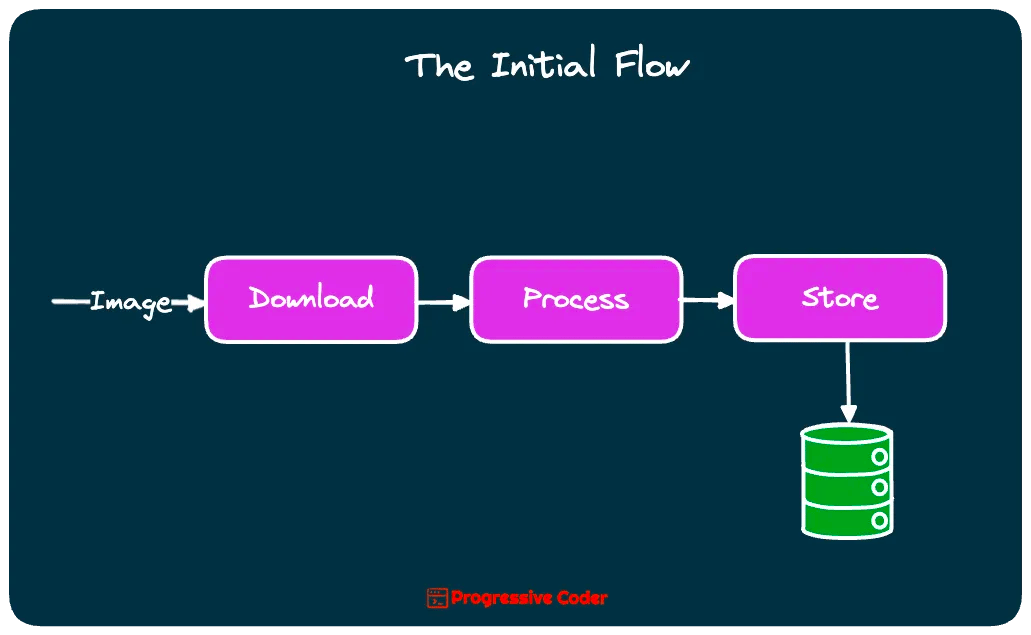
There was no de-duplication whatsoever. Also, no reuse of images.
To achieve de-duplication, the team at Uber decided to push more responsibility to the backend service.
Three main flows were identified:
Known and Processed Image
New and Unprocessed Image
Known but Not Processed Image
To implement these flows, they relied on 3 separate maps:
URL Map
Processed Image Map
Original Image Map
If you aren’t aware, maps are just key/value pairs that let you fetch data based on a key with constant time complexity.
The below table shows the structure of each map.

The images were stored in Uber’s blob storage system known as Terrablob (similar to Amazon S3). The metadata was stored in Docstore.
Let’s look at the 3 flows in more detail to gain a better understanding.
1 - Known and Processed Images
Input is the Image URL.
Get hash from the URL Map.
If found, check for the hash in the Processed Image Map.
If found, return the Processed Image URL.
That’s it. No new upload in this case.
This is the simplest flow and handles duplicate images like a boss!
Here’s an illustration for the same:
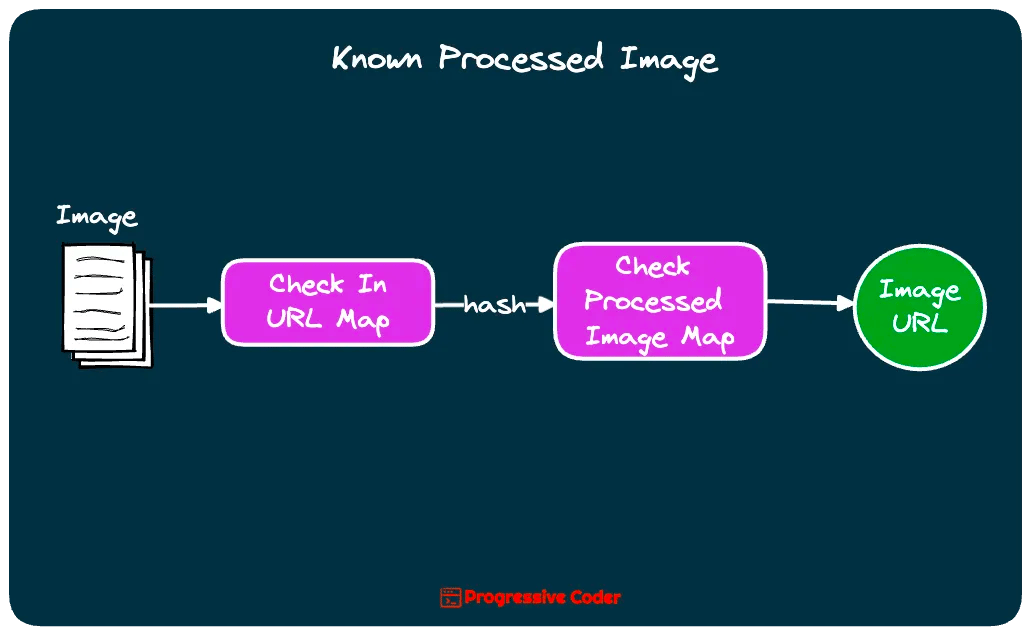
2 - New and Unprocessed Image
Input is once again the Image URL.
The steps are as follows:
Get hash from the URL Map.
If not found, download the image and get the hash.
Update the URL Map and Original Image Map with the data.
Process the image and update the Processed Image Map.
Return the Processed Image URL.
This is the longest flow and takes care of completely new images coming into the system.
The below illustration shows the process:

3 - Known But Not Processed Image
Input is the Image URL.
Get hash from the URL Map.
If found, check the Processed Image Map.
If not found, process the image and store it.
Return the processed image URL.
This is less complex than the previous flow. Kind of like the middle ground.
Here’s an illustration of the same.

Together, the 3 flows prevent duplicate images from entering the Uber Eats workflow and ultimately result in crucial cost savings.
P.S. This post is inspired by the explanation provided on the Uber Engineering Blog. You can find the original article over here.
🍔 Food For Thought
👉 Many times, developers say that they don’t care about how the system works. They just want to focus on the piece of functionality they are working on and that’s about it.
While this approach may work for junior developers coming out of internship, it quickly starts becoming a problem as you grow in your role.
As a developer, you get paid for solving business problems.
To build the best possible solution, you need to have a good understanding of how the overall system works.

Link to the tweet:
https://x.com/ProgressiveCod2/status/1698300101750350058?s=20
👉 While building a solution, it’s better to take an iterative approach rather than worrying about building the best solution in the first go.
The below post sums it up beautifully.

Link to the tweet:
https://x.com/mjovanovictech/status/1696844284752711963?s=20
That’s it for today! ☀️
Enjoyed this issue of the newsletter?
Share it with your friends and colleagues.
See you later with another value-packed edition — Saurabh.