
Pessimistic vs Optimistic Locking
Choosing the right approach...

In multi-user applications, where multiple processes or users might attempt to read or update the same data simultaneously, ensuring data consistency and integrity becomes crucial. This is where locking mechanisms come into play.
Locks help prevent conflicting updates that can lead to issues like lost updates, dirty reads, or phantom reads. However, not all locking strategies are created equal. Two of the most common approaches—Pessimistic Locking and Optimistic Locking—offer different trade-offs between safety and performance.
Let’s dive into what these strategies are, how they differ, and when you should use one over the other.
What Is Pessimistic Locking?
Pessimistic locking takes a "better safe than sorry" approach. It assumes that conflicts are likely to happen, so it locks the data preemptively before any updates are made.
How It Works:
When a user or process wants to read and update a piece of data:
It acquires a lock on the data.
Other users/processes are blocked from accessing or modifying that data until the lock is released.
Once the operation is complete, the lock is released.
This strategy is often enforced at the database level, using exclusive locks (e.g., SELECT ... FOR UPDATE in SQL).

Advantages:
✅ Guarantees data integrity—conflicts are prevented before they can happen.
✅ Ideal for critical updates, such as financial transactions or inventory management.
Disadvantages:
❌ Reduces concurrency—other users may be blocked, even if they want to read the data.
❌ Can lead to deadlocks if multiple processes wait on each other’s locks.
❌ Affects system performance under high contention.
Best Used For:
Systems with high contention on the same data.
Workloads that require strong consistency, like banking or booking systems.
What Is Optimistic Locking?
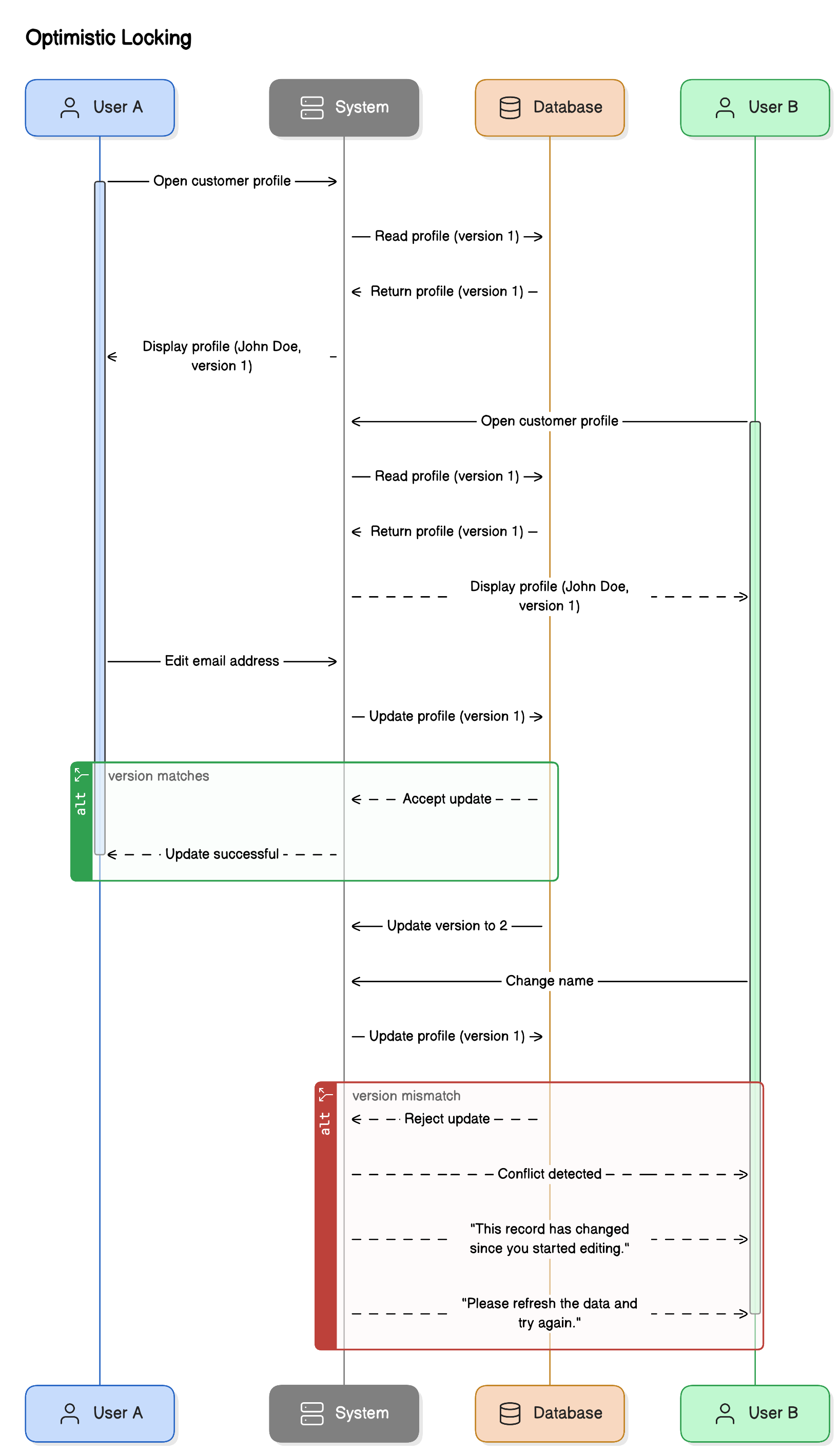
Optimistic locking takes a "conflicts are rare" approach. Instead of locking data up front, it allows multiple users to access and even modify the same data concurrently, and checks for conflicts only at commit time.
How It Works:
When data is read, its version number or timestamp is recorded.
The user modifies the data without acquiring a lock.
When trying to write the update back:
The system checks whether the version number or timestamp has changed since it was read.
If unchanged → update is applied.
If changed → conflict is detected → operation is aborted or retried.
This is commonly implemented in application code or supported by ORM frameworks like Hibernate, Entity Framework, etc.
Advantages:
✅ Allows high concurrency and throughput, as there are no locks during read and modify phases.
✅ Avoids blocking and deadlock scenarios.
✅ Ideal for read-heavy applications with low conflict rates.
Disadvantages:
❌ Requires retry logic for failed transactions.
❌ May lead to wasted computation if conflicts are detected late.
❌ Not suitable for high-conflict scenarios.
Best Used For:
Applications with many reads and few writes (e.g., social media feeds, reporting dashboards).
Distributed systems where locking is expensive or impractical.
Best Practices for Using Locking Mechanisms
Whether you're using pessimistic or optimistic locking, here are some tips to ensure your locking strategy works effectively:
Hold Locks for the Minimum Time Possible
Long-held locks reduce concurrency and increase the risk of contention or deadlocks.
Use Fine-Grained Locking
Lock only what's necessary. For example, prefer row-level locks over table-level locks to reduce lock scope.
Implement Retry Logic (for Optimistic Locking)
Always anticipate that a commit may fail and prepare to retry the operation with the latest data.
Monitor and Tune Locking Behavior
Use database tools and logs to detect high lock wait times or deadlocks.
Choose Based on Your Data Patterns
If users are frequently updating the same records, pessimistic locking may be safer.
If updates are rare or distributed, optimistic locking will give you better performance.
So - which locking strategy have you used the most?
Here are some interesting articles I’ve read recently:
That’s it for today! ☀️
Enjoyed this issue of the newsletter?
Share with your friends and colleagues.
Hey Saurabh, thanks for the great read! I especially enjoyed reading your diagrams, which were both concise and aesthetically pleasing. After looking through a few of your posts, I saw that you regularly incorporate diagrams of this sort into your explanations.
Do you have any tips you could share on making good diagrams? I’ve read about UML in the past but it seemed overly formal to me; do you consider it (or similar languages) necessary for creating understandable diagrams?
Great summary and write up, thank you!