
SDC#19 - Paypal's JunoDB Breakdown
Avoid oversharing in an interview and more...

Hello, this is Saurabh…👋
Welcome to the 425 new subscribers who have joined us since last week.
If you aren’t subscribed yet, join 2400+ curious Software Engineers looking to expand their System Design knowledge by subscribing to this newsletter.
📣 Announcement
The Progressive Coder newsletter is now called System Design Codex.
While I really loved Progressive Coder as a name, it didn’t fully reflect the goal and mission of the newsletter.
Over the last week, I’ve also migrated the newsletter to Substack to provide a better user experience and sense of community. It will help the newsletter grow and add more value to your journey.
To have the emails from delivered to your mailbox without any hiccups, request you to whitelist the same (one-time activity):
Gmail Users: Drag this message to your ‘Primary’ inbox.
Apple Mail Users: Add my email address to your “Contacts or VIPs”
Outlook Users: Add my email address to your “Safe Senders” list
With that out of the way, let’s move on to today’s topic.
In this edition, I cover the following topics:
🧰 Case Study → Paypal JunoDB Breakdown
🍔 Food For Thought → Avoid Oversharing in an Interview
So, let’s dive in.
🧰 PayPal’s JunoDB Breakdown
PayPal recently open-sourced their internal key-value store called JunoDB.
As per PayPal’s claims, JunoDB is capable of running at 6 nines of availability (99.9999%).
This amounts to just 86.40 milliseconds of downtime per day.
Your average eye blink takes 100 milliseconds, which means you can theoretically miss JunoDB going down in the blink of an eye.
That’s quite crazy when you think about it!
For us, it indicates there’s a lot we can learn from JunoDB’s design and architecture.
JunoDB Facts
Before we take a deeper look, I’d like to mention some facts about JunoDB and its use at PayPal:
JunoDB is a distributed key-value store and is written in Go.
It handles 350 billion requests daily at PayPal.
JunoDB is used in virtually every core back-end service at PayPal. This includes super-critical stuff like login, risk management and transaction processing.
The main use of JunoDB is caching. So, it’s not used as the source-of-truth DB for PayPal. Instead, the goal of JunoDB is to reduce the load on the main relational database.
Here’s an illustration that shows where JunoDB fits in the overall scheme of things:
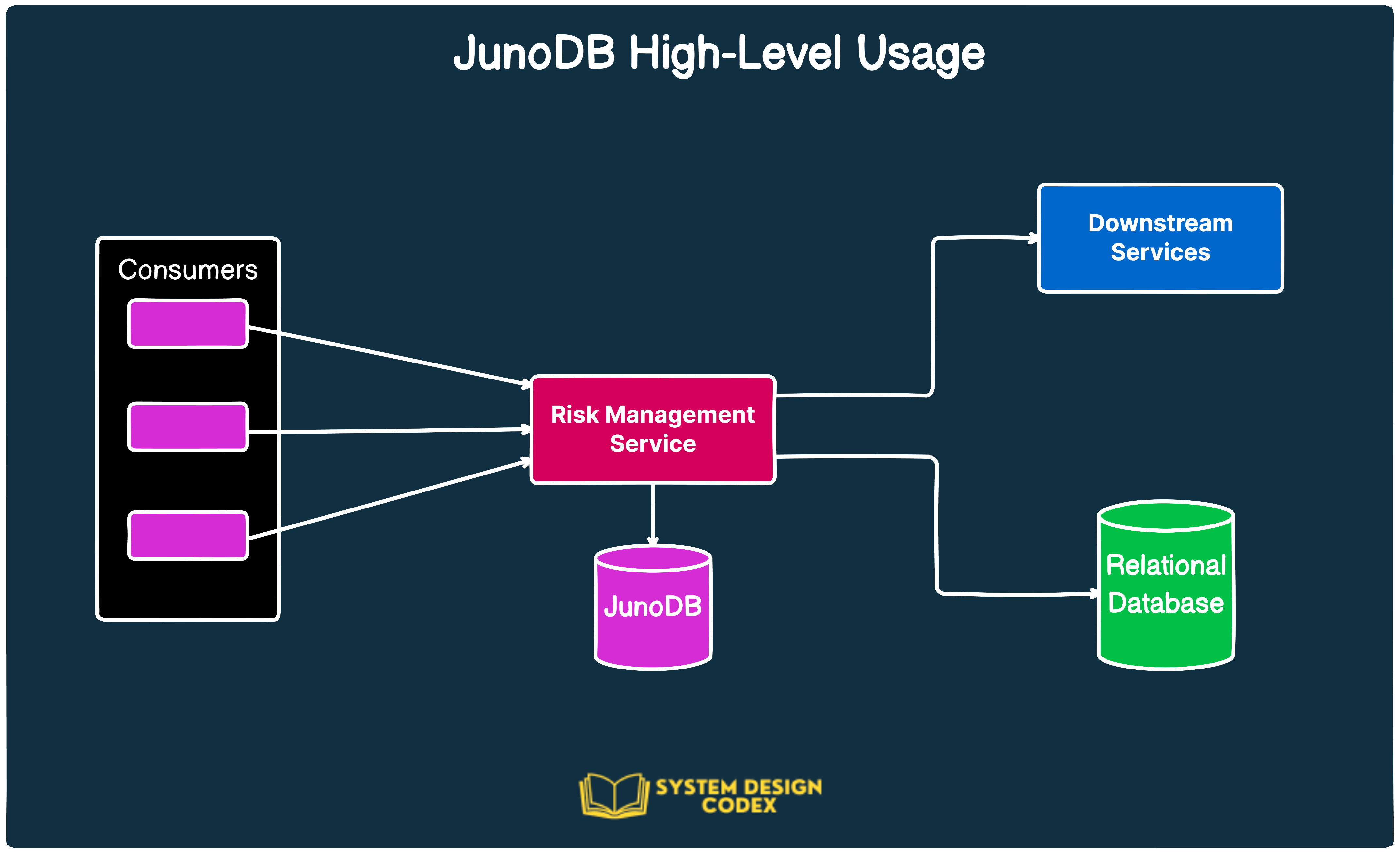
All of this may sound quite exciting.
But the first question I had when learning about JunoDB was this:
“Why didn’t PayPal just use something like Redis? Why bother re-inventing the wheel?”
Why not Redis?
The reason was PayPal’s need for multi-core support.
Redis is not designed to benefit from multiple CPU cores.
It is single-threaded in nature and utilizes only one core no matter how many cores may be available. You need to launch several Redis instances to scale out on several cores if needed.
This isn’t a problem for Redis as such because the performance of Redis is memory-bound instead of CPU-bound.
But what do we really mean by memory-bound vs CPU-bound?
The terms "memory-bound" and "CPU-bound" refer to different types of performance bottlenecks in computer programs.
The performance of memory-bound programs is limited by the amount of available memory.
On the other hand, CPU-bound programs are constrained by the processing power of the CPU.

As you might be aware, Redis stores its data primarily in RAM, and everything about it is optimized for quick in-memory access.
If there’s more data than what can be stuffed into the RAM, there’s increased swapping to the disk. And increased swapping can degrade performance.
That’s why the limiting factor for Redis performance is the system memory rather than the CPU.
Incidentally, JunoDB also started as a single-threaded C++ program and its initial goal was to act as an in-memory short TTL data store.
TTL stands for Time to Live. It specifies the maximum duration a piece of data should be retained or the maximum time it is considered valid.
But somewhere down the line, the goals for JunoDB evolved.
First, it transformed into a persistent data store supporting long TTLs.
Second, it was also supposed to provide improved data security via on-disk encryption and TLS in transit by default.
Now, things like encryption are generally CPU-intensive because many cryptographic algorithms require raw processing power to carry out complex mathematical calculations.
In other words, they needed JunoDB to be CPU-bound rather than memory-bound.
As a result, it was rewritten in Go to support high concurrency and make it multi-core friendly.
JunoDB Architecture
Here’s the high-level overview of JunoDB’s architecture:

Let’s look at the main components of the overall JunoDB architecture
1 - JunoDB Client Library
This is part of the client application and provides an API for storing and retrieving of data via the JunoDB proxy.
The client library is implemented in several programming languages such as Java, C++, Python and Golang.
For developers, it’s just a matter of choosing the library for their programming language and including it in the application.
2 - Load Balancer and JunoDB Proxy
JunoDB uses a proxy-based design that has a few obvious advantages:
The complexity of determining where to route the queries is kept out of the client libraries. Since JunoDB is a distributed data store, the data is spread across multiple servers. The proxy handles the job of directing the requests to the correct server.
The proxy is also aware of the JunoDB cluster configuration (such as shard mappings) stored in etcd.
But what about the JunoDB Proxy turning into a single point of failure?
To avoid this, the proxy runs on multiple instances downstream to a load balancer.
The load balancer receives incoming requests from the client applications and routes the requests to the appropriate proxy instance.
3 - JunoDB Storage Servers
Lastly, we have the JunoDB storage servers.
These are instances that accept operation requests from the proxy and store data in memory or persistent storage using RocksDB.
RocksDB is an embedded key-value storage engine that is optimized for high read and write throughput.
Internally, JunoDB makes use of RocksDB to store the data. Using a storage engine such as RocksDB is pretty common in the database world to avoid building everything from the ground up.
Each storage server has a group of shards (or partitions) for efficient distribution and management of data.
Where can you use JunoDB?
Now that PayPal has made JunoDB open-source, it’s possible that we can use it within our projects.
But what are the various use cases where JunoDB shines?
1 - Caching
JunoDB can be used as a temporary cache to store data that doesn’t change frequently.
Since JunoDB supports both short and long-lived TTLs, you can store data for a few seconds for a few days. For example, why go to the database for short-lived tokens when you can store them in JunoDB?
Other things you can cache in JunoDB are user preferences, account details, and API responses.
I discussed a bunch of useful database caching strategies in an earlier post. Do check it out:

2 - Idempotency
You can also use JunoDB to implement idempotency.
Idempotency is a property in which a specific operation produces the same result even if it is applied multiple times. With idempotency, repeating the operation is safe and you don’t need to be worried about things like duplicate payments getting applied.
For example, PayPal uses JunoDB to ensure they don’t process a payment multiple times due to retries.
Since JunoDB is highly available, it is an ideal data store to keep track of processing details without overloading the main database.
3 - Counters
Let’s say you’ve certain resources that are not available for some reason.
Or they have an access limit that you want to impose.
These resources could be things like database connections, API rate limits, or user authentication attempts.
You can use JunoDB to store counters for these resources and track if their usage is going above the allowed limit.
4 - Latency Bridging
JunoDB provides really fast inter-cluster replication.
This can help you deal with slow replication in more traditional setups.
For example, in PayPal’s case, they run Oracle in Active-Active mode, but the replication isn’t as fast as they would like.
It means there are chances of inconsistent reads if records written in one data center are not replicated to the second data center.
JunoDB can help bridge the latency where you can write to Data Center A (both Oracle and JunoDB) and even if it goes down, you can read the updates consistently from the JunoDB instance in Data Center B.
Check the below illustration for a clearer understanding:

P.S. This post is inspired by the explanation provided on the PayPal’s engineering blog. Some things have been inferred based on the details provided. Also, the diagrams have been drawn or re-drawn based on the information shared to make things clearer. You can find the original article over here.
🍔 Food For Thought
👉 Oversharing in an Interview
How much sharing is enough in an interview?
This is a question that always makes me think.
On the one hand, you want to be as transparent as possible.
But on the flip side, oversharing can also go against you if you are too open with details that are not necessary to your next role but can go against you if mentioned.
I wrote a post about it on X (Twitter) sharing my thoughts. It also got a bunch of interesting responses.

Here’s the link if you want to check it out:
https://x.com/ProgressiveCod2/status/1730912073763426549?s=20
👉 How to get better at Code Reviews?
Code reviews an integral part of a developer’s life.
And yet, little attention is given to the code review process that can actually improve the experience.
Recently, Fernando wrote a wonderful post addressing this exact issue with some great tips.

Here’s the link to the post:
https://x.com/Franc0Fernand0/status/1733042763099181175?s=20
That’s it for today! ☀️
Enjoyed this issue of the newsletter?
Share with your friends and colleagues
See you later with another value-packed edition — Saurabh
Thanks Sourabh. I see you have mentioned that JunoDB is created to tackle CPU Bound tasks. You also mentioned about encryption - that is CPU bound. But what workload related to encryption that JunoDB supports? I cannot quite relate to that. This seems to be main reason why Redis could not quite fit for their needs.