
Must-Known Resiliency Patterns for Distributed Systems
Downstream and Upstream...

Distributed systems are great at providing scalability and high availability to meet user demands.
But with increased complexity comes greater risk.
If you are building distributed systems, you must invest in proactive strategies to ensure resiliency. These strategies can be divided into two categories:
Downstream Patterns
Upstream Patterns
Let’s look at both.
Downstream Resiliency Patterns
Downstream patterns are used by the service caller. They are implemented by a service when it communicates with another service, ensuring that a failure in the downstream system doesn’t cause a domino effect.
1 - Timeouts
A timeout is a mechanism that prevents a service from waiting indefinitely for a response from a downstream service. By setting a maximum wait time, you avoid tying up resources that could be used for other requests.

Why It’s Important:
Prevents resource exhaustion caused by requests stuck waiting indefinitely.
Improves overall system responsiveness by allowing failed requests to be handled quickly.
Implementation Tips:
Fine-tune timeouts based on the expected response times of downstream services. For example, a cache lookup might have a 50ms timeout, while a database query might have a 500ms timeout.
Combine timeouts with monitoring to identify latency patterns and adjust as needed.
2 - Circuit Breaker
A circuit breaker monitors the success and failure rates of requests and temporarily disables calls to a service if failures exceed a predefined threshold. Like an electrical circuit breaker, it prevents further damage by "tripping" the connection.
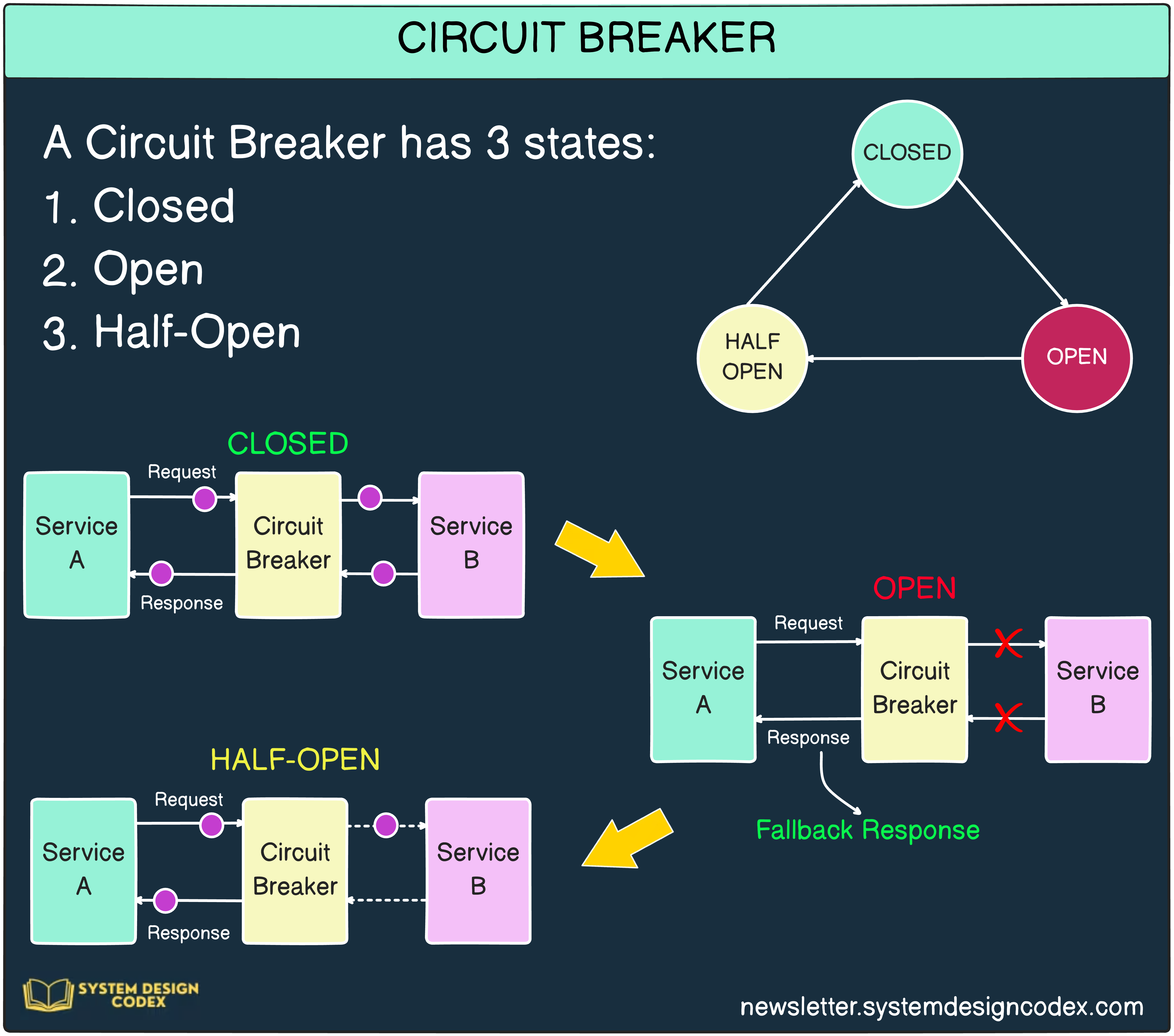
Why It’s Important:
Protects your system from overwhelming downstream services during failures.
Allows time for the downstream service to recover.
Implementation Tips:
Implement with standard libraries like Resilience4j to handle circuit breakers.
Define three states for the circuit:
Closed: Requests flow as usual.
Open: Requests are blocked after reaching a failure threshold.
Half-Open: A limited number of test requests are sent to check if the downstream service has recovered.
Tune thresholds carefully, such as the number of failures or the time window for evaluating failures.
3 - Retries with Exponential Backoff
Retries are essential when transient failures occur.
Exponential backoff adds a delay between retries, doubling the wait time after each attempt. This gives the downstream service more time to recover and avoids overwhelming it.

Why It’s Important:
Increases the likelihood of success when the failure is temporary.
Reduces the risk of overloading a struggling downstream service.
Implementation Tips:
Combine retries with a maximum retry limit to avoid infinite loops.
Use jitter (randomized delay) in conjunction with exponential backoff to prevent synchronized retries from multiple clients causing a "thundering herd" problem.
Example: First retry after 100ms, second after 200ms, third after 400ms, with a maximum of 5 retries.
Upstream Resiliency Patterns
Upstream patterns are used by the service owner. They are implemented by service owners to safeguard the health of their service and ensure stability during high traffic or failures.
1 - Load Shedding
Load shedding involves rejecting a portion of incoming requests when a service is overloaded.
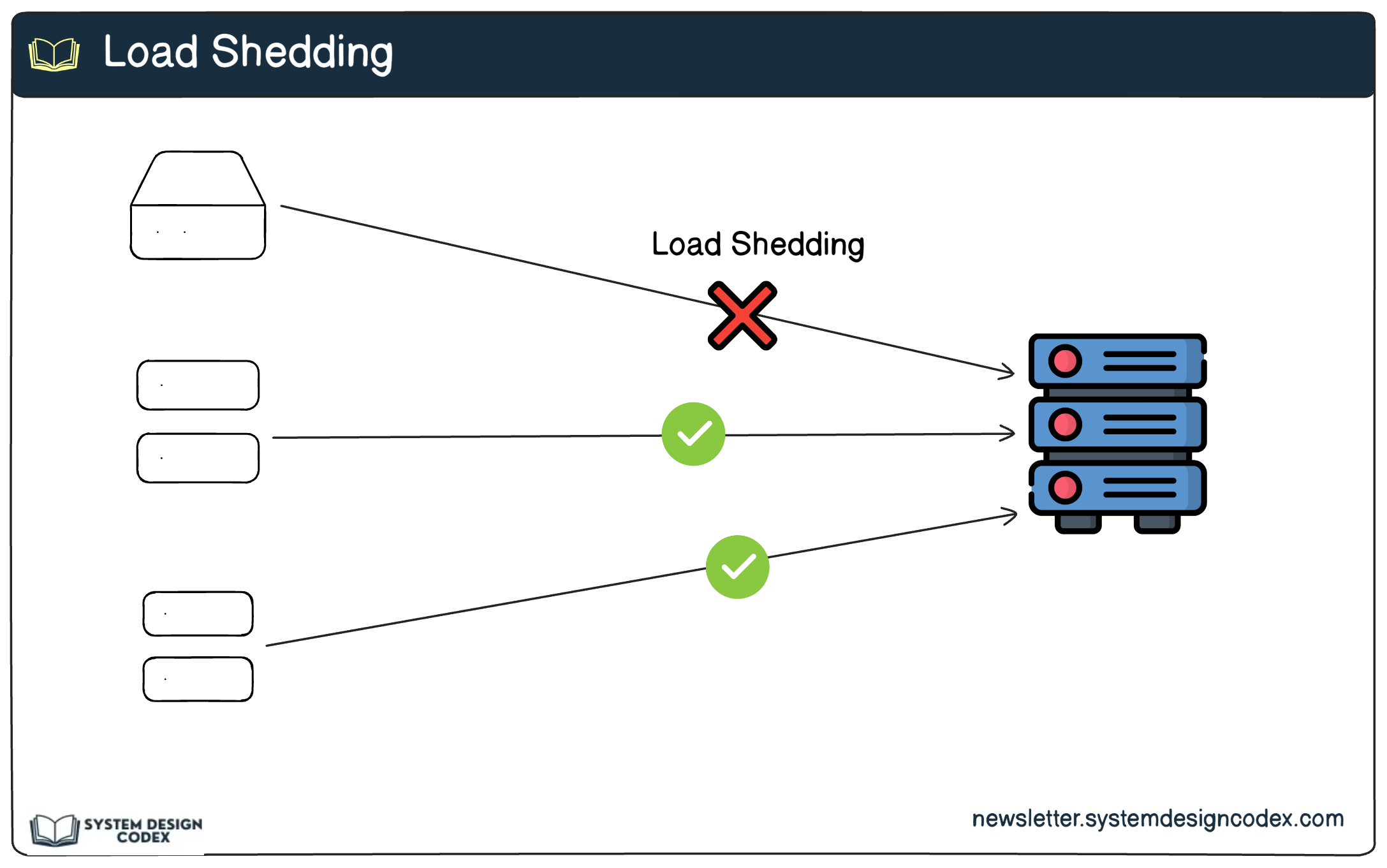
Why It’s Important:
Prevents complete system failure during peak loads.
Ensures critical users or requests are prioritized.
Implementation Tips:
Use techniques like token-bucket or leaky-bucket algorithms to control the rate of incoming requests.
Implement priority queues to ensure critical requests (e.g., payment transactions) are handled first.
Gradually degrade non-critical features or services under heavy load (e.g., disabling analytics during peak demand).
2 - Rate Limiting
Rate limiting sets the maximum number of requests that a client can make within a specific time window. This prevents individual clients or malicious actors from overwhelming your service.
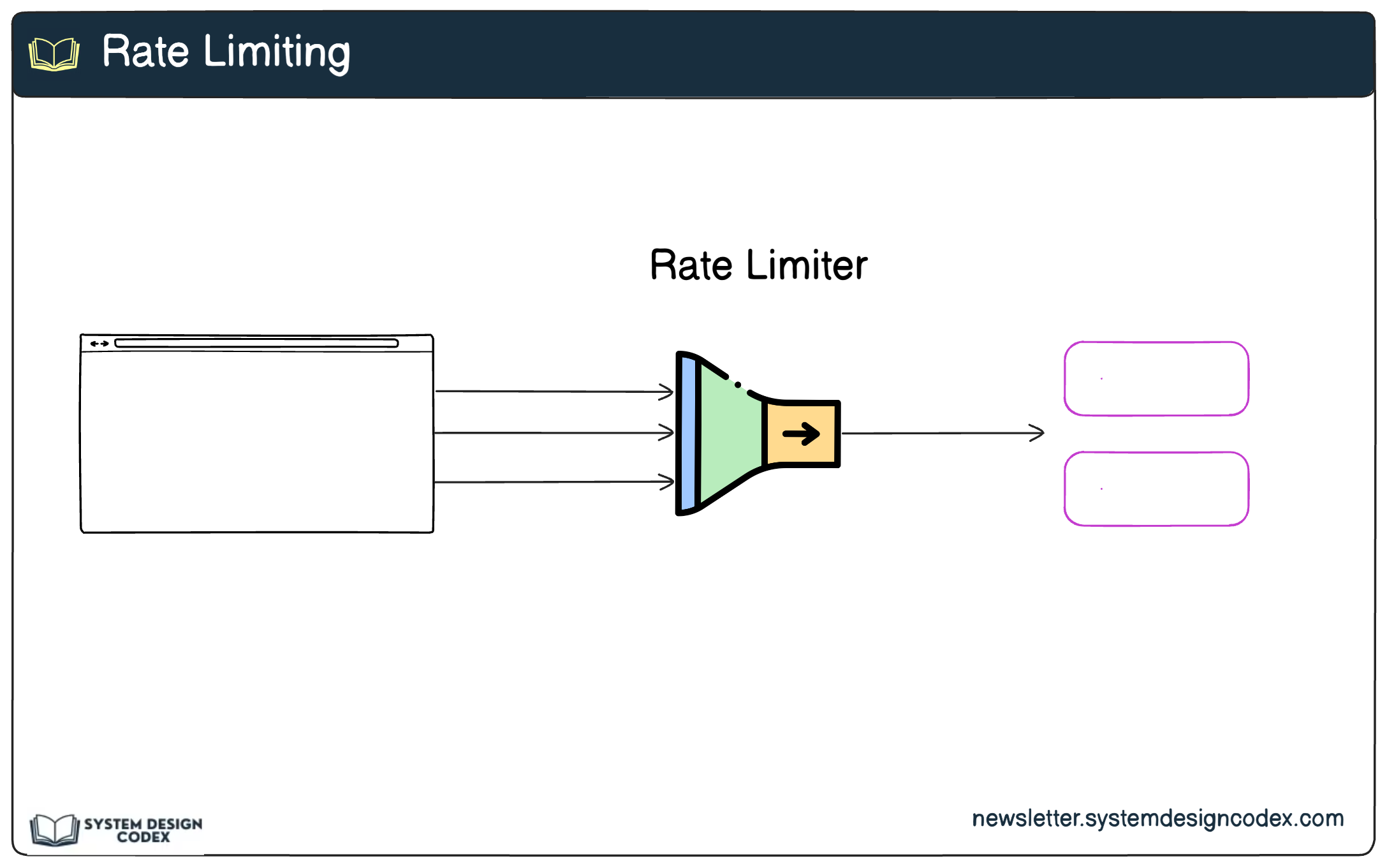
Why It’s Important:
Protects the service from abuse, such as Distributed Denial of Service (DDoS) attacks.
Ensures fair resource usage across all clients.
Implementation Tips:
Implement rate-limiting algorithms like the fixed window, sliding window, or token bucket.
Use APIs or middleware solutions such as API Gateway, NGINX, or tools like Kong.
Provide informative error messages (e.g., HTTP 429 Too Many Requests) to guide clients on retry strategies.
3 - Bulkheads
Bulkheading involves isolating different parts of the system to prevent failures in one component from cascading to others. This is analogous to compartments in a ship—if one is breached, the others remain unaffected.

Why It’s Important:
Limits the blast radius of failures.
Improves fault isolation and prevents a single failure from affecting the entire system.
Implementation Tips:
Separate resource pools for different components (e.g., thread pools or connection pools for different services).
Isolate critical resources to prevent non-critical services from consuming them (e.g., separate database connections for high-priority and low-priority queries).
Use container orchestration tools like Kubernetes to allocate dedicated resources to specific services.
4 - Health Checks with Load Balancers
Health checks monitor the status of service instances and enable a load balancer to redirect traffic away from unhealthy instances. This ensures that users are always routed to functioning parts of the system.

Why It’s Important:
Prevents traffic from being sent to failing or degraded instances.
Improves overall user experience by minimizing downtime.
Implementation Tips:
Use active health checks (periodic pings) or passive health checks (monitoring error rates).
Configure thresholds for health checks, such as the number of failed requests or response latency.
Implement rolling updates with health checks to ensure smooth deployment without downtime.
So - which resiliency patterns have you used in your project?
Shoutout
Here are some interesting articles I’ve read recently:
No matter what the books say, nobody likes making 20 requests to render a page by Raul Junco
How did I improve my focus & productivity with a simple Second Brain in Notion? by Petar Ivanov
That’s it for today! ☀️
Enjoyed this issue of the newsletter?
Share with your friends and colleagues.
This was a nice overview, and I learned a lot. I never had to use loads shedding or bulkheads, but I guess those are responsible for the "service is currently unavailable" whenever I try to accomplish something in a banking system. 😄
Building Resiliency is the only way to build a truly distributed system.
Good compilation of patterns, Saurabh!