
SDC#22 - HTTP/1.1 vs HTTP/2
The only post you need to understand the difference...

Hello, this is Saurabh…👋
Welcome to the 306 new subscribers who have joined us since last week.
If you aren’t subscribed yet, join 3300+ curious Software Engineers looking to expand their system design knowledge by subscribing to this newsletter.
Happy New Year to all the wonderful subscribers!
In this first edition of 2024, I cover the following topics:
🖥 System Design Concept → HTTP/1.1 vs HTTP/2
🍔 Food For Thought → Follow tutorials but don’t forget the errors
So, let’s dive in.
🖥 HTTP/1.1 vs HTTP/2
The World Wide Web runs on HTTP.
The acronym stands for Hypertext Transfer Protocol.
Once upon a time, this sounded like a perfect choice. After all, the goal of HTTP was to transfer hypertext documents. Basically, documents that contain links to other documents.
But, soon enough developers realized that HTTP can also be used to transfer other types of content (such as images, sound, videos and so on).
This proves that naming things in computer science has always been hard.
Jokes apart, it’s now too late to change the name and frankly speaking, it doesn’t matter.
The point is that over the years, HTTP has become critical to the existence and growth of the web.
But what exactly is HTTP used for in the context of the web?
To transfer data between client and server.
For example, when you navigate to something like google.com on your favorite web browser, the browser sends an HTTP request to the Google servers. The Google servers send back HTTP responses with the required text, images and formatting rules so that the browser can display the web page to you.
Here’s a super high-level look at communication between the client and server over HTTP.

As we all know, the web has evolved dramatically in the last 20 years and to keep things from falling apart, HTTP also had to evolve.
HTTP/1.1, HTTP/2 and latest iteration HTTP/3 are basically the high-level milestones in this evolution journey.
In today’s discussion, I’ll cover HTTP/1.1 and HTTP/2. The discussion around HTTP/3 is reserved for a future post since it has some key differences that needs a separate discussion.
HTTP/1.1 - The Bedrock
HTTP/1.1 came into existence in 1997 as a specification.
Though there were earlier HTTP versions such as 0.9 and 1.0, the 1.1 version was the one that powered the growth of the world wide web.
And you might be amazed to know that HTTP/1.1 is still heavily used despite being over 25 years old.
That’s mind-blowing when you think about it!
Many companies don’t last more than a decade and here we have a technology that’s been there for more than two decades in an area as dynamic as the web.
What contributed to its incredible longevity?
There were a couple of factors:
1 - Persistent Connections
HTTP started off as a single request-and-response protocol.
A client opens a connection to the server, makes a request, gets the response and the connection is closed.
If there’s a second request, the cycle repeats.
Third request and still the same thing happens.
It’s like every person arriving to a conference room knocks on the door, waits for someone to open it and closes it when they get in.
However, this wasn’t so bad when websites were simpler with just one or two HTML pages.
But as the web became media-rich, this constant closing of the connection proved to be wasteful. If a web page contains multiple resources that had to be fetched from the server, you were looking at opening and closing multiple connections.
Since HTTP is built on top of TCP (Transmission Control Protocol), every new connection means going through the 3-Way Handshake Process (more on that later).
With persistent connections, HTTP/1.1 got rid of all this extra overhead. It assumes that a TCP connection should be kept open unless directly told to close.
This means:
No closing of the connection after every request.
No multiple TCP handshakes.
This is quite similar to keeping the door open for multiple people to enter a conference room. Clearly, much more efficient and less time consuming.
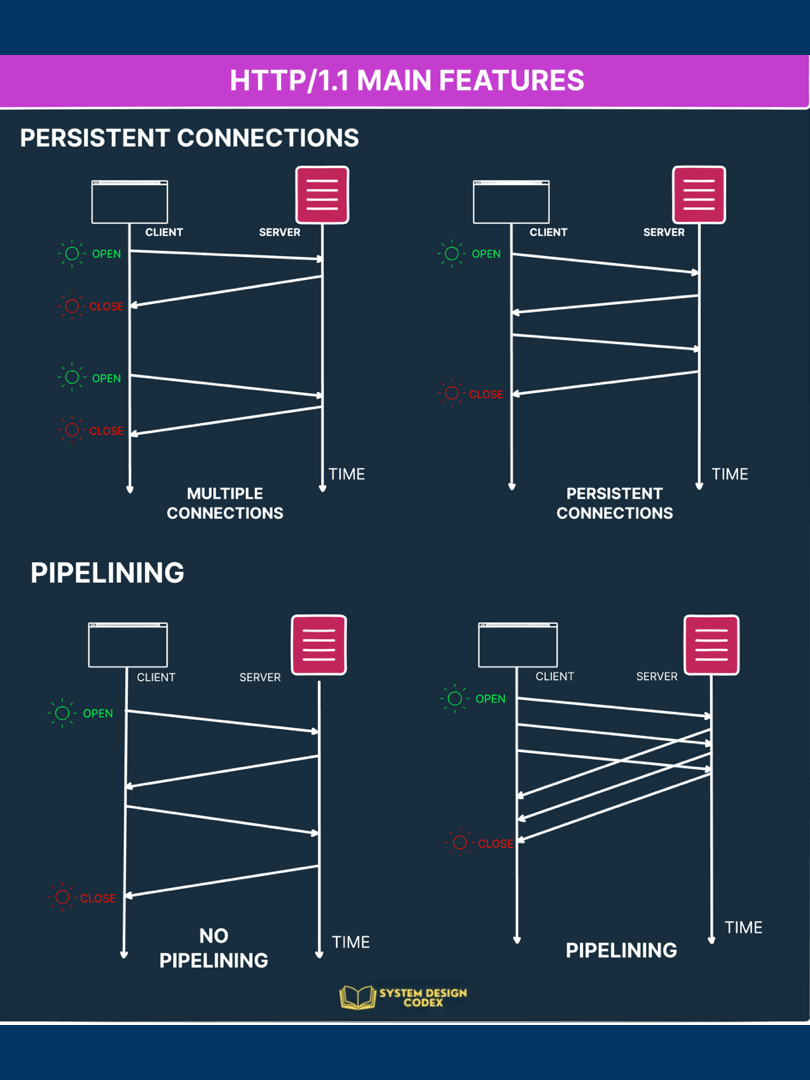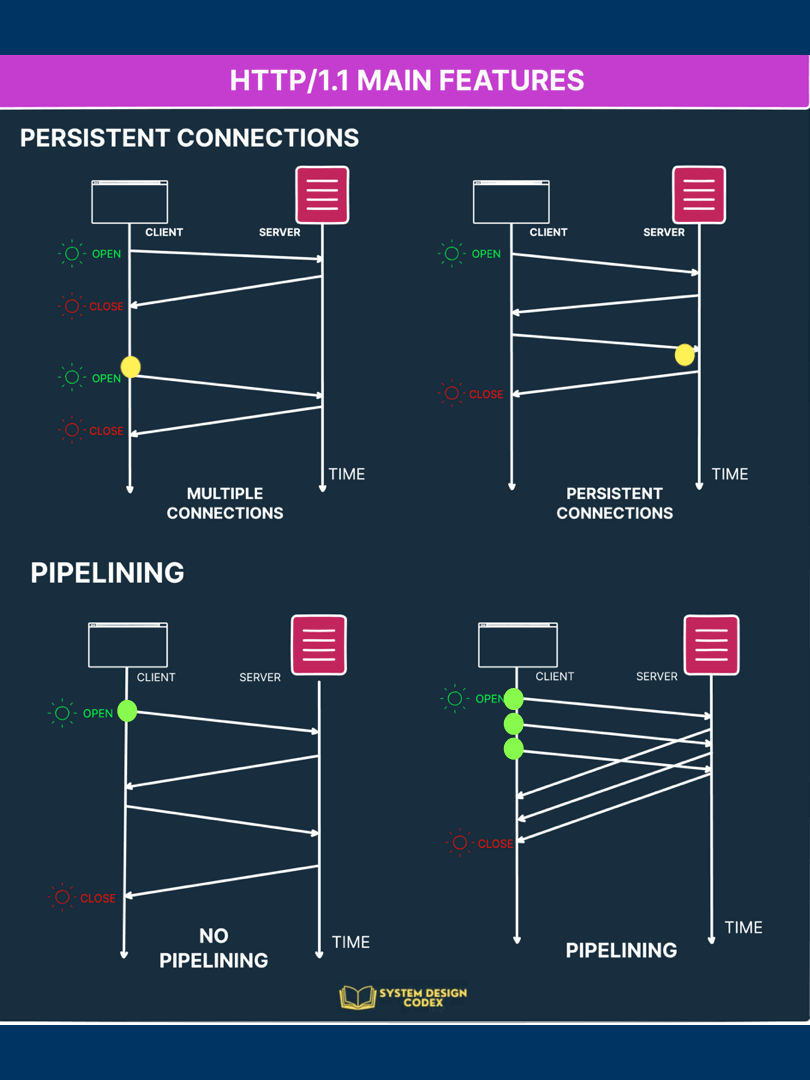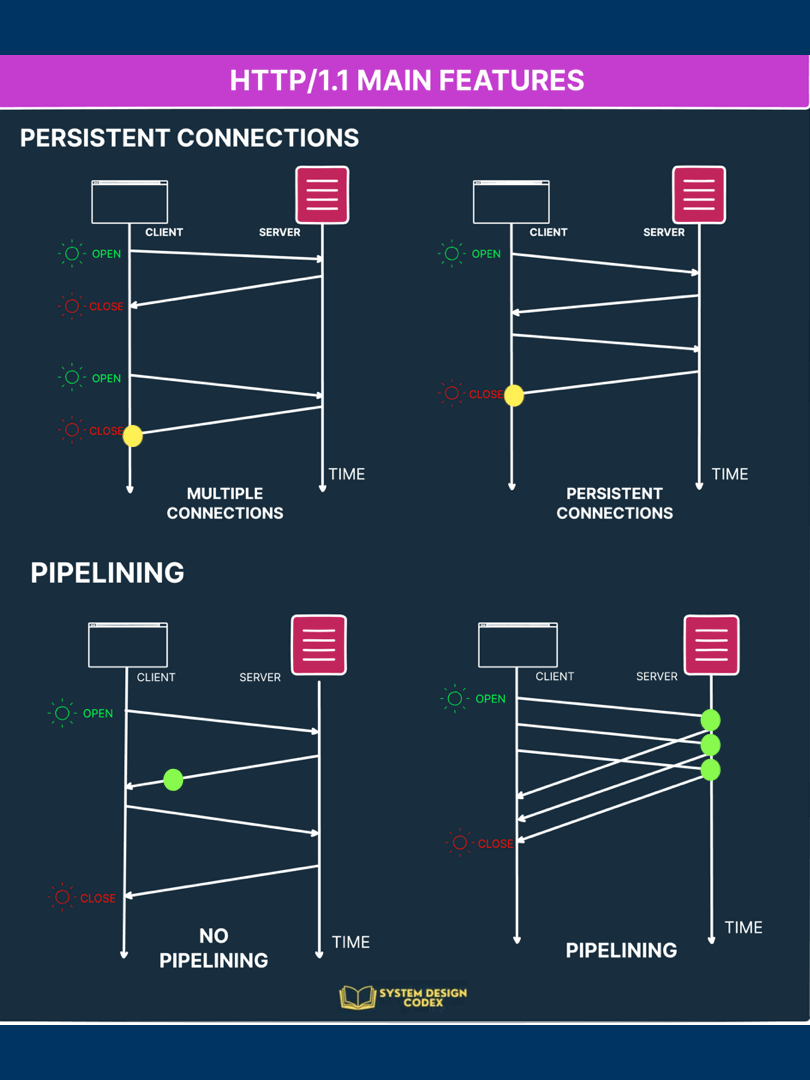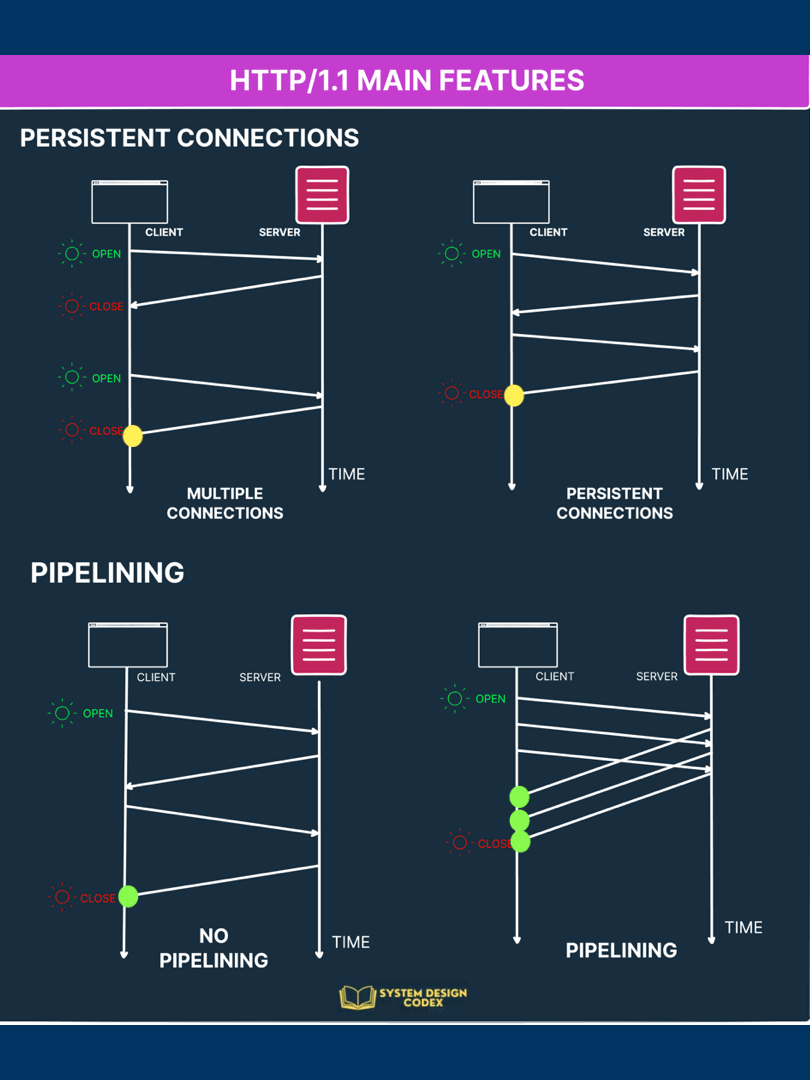
The below diagram tries to show the difference between multiple connections and persistent connection.

2 - Pipelining
HTTP/1.1 also tried to introduce the concept of pipelining.
The idea was to allow multiple requests to be sent to the server without waiting for the corresponding response. For example, when the browser sees that it needs 2 images to render a web page, it can request them one after the other.
Check out the below diagram that shows pipelining.

Though pipelining sounded cool, it didn’t solve the fundamental problems with HTTP/1.1 as we will see in the next section.
Here’s an infographic that depicts the concept of Persistent Connections and Pipelining.
The Problem with HTTP/1.1
There’s no doubt that HTTP/1.1 was amazing.
It enabled the mind-boggling growth of the world wide web over the last two decades.
But let’s be honest. The web has changed considerably since the time HTTP/1.1 was launched.
Websites have got bigger with more resources to download and a greater amount of data to be transported across the network. According to HTTP Archive, the average website these days requests 80 to 90 resources and downloads nearly 2 MB of data.

This growth exposed the fundamental performance problem with HTTP/1.1
Consider the below request response flow for a web page with two images:
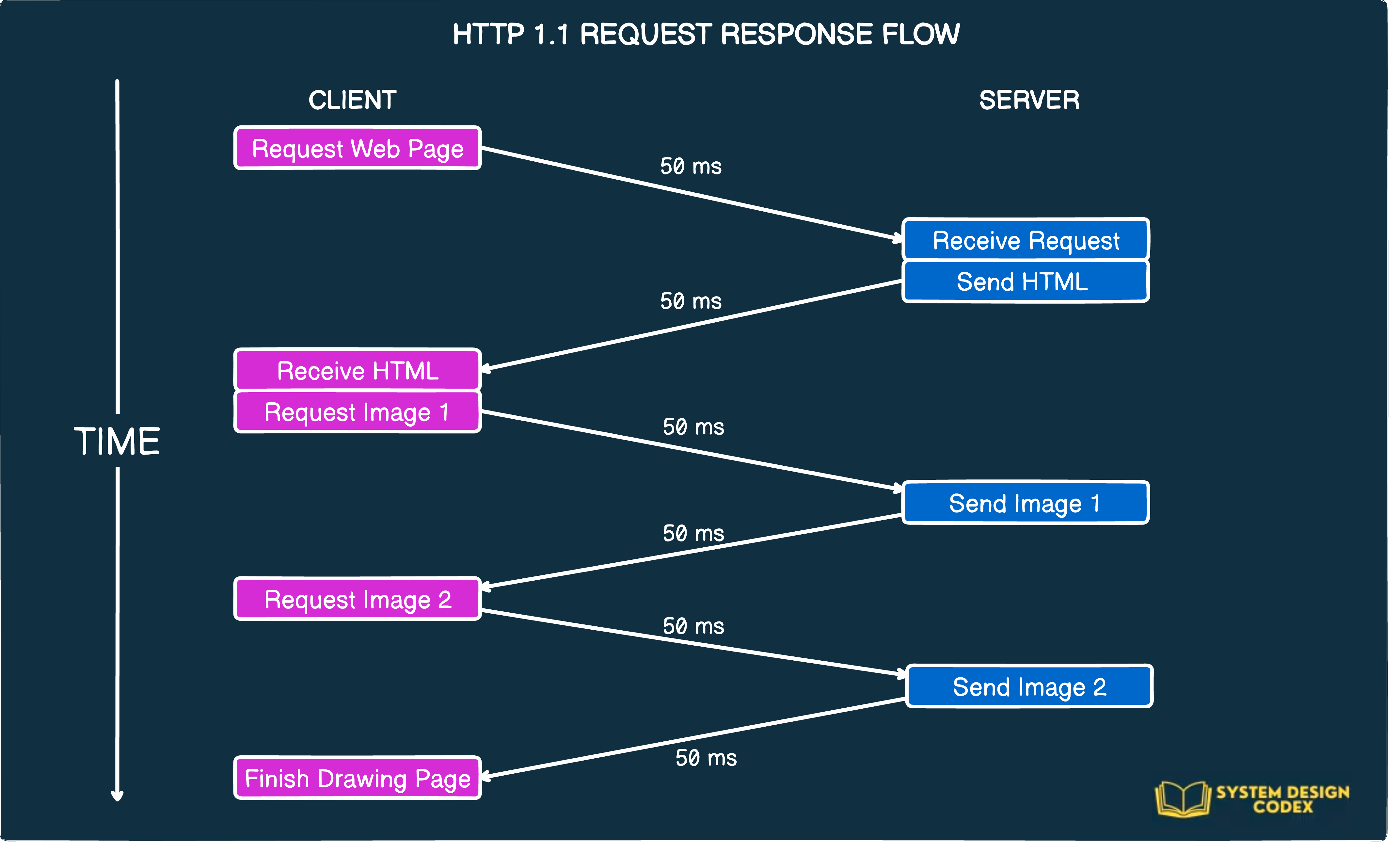
What’s going on over here?
The client (or the browser) makes a request to the server for the HTML page. Assume that the roundtrip takes 100 milliseconds.
After receiving the HTML page, the browser request for Image 1. This adds another 100 milliseconds for the request to reach the server and the image to arrive at the client.
Next, the browser requests for Image 2. Add another 100 milliseconds.
Finally, the browser finishes rendering the page.
As you may have noticed, latency can be a big problem with HTTP/1.1.
In fact, you can’t solve latency issues with newer technologies because latency is restricted by the laws of physics.
Data being transmitted through fiber-optic cables is already traveling pretty close to the speed of light.
But are there no workarounds?
Sure, there are but they don’t solve the latency problem of HTTP/1.1 without creating their own problems. Let’s look at a few:
1 - Pipelining Again
As we saw earlier, pipelining sounds promising. Imagine the same request response flow with pipelining:

As you can see, pipelining shaves off 100 milliseconds because the browser can request the two images one after the other without waiting for a response.
Unfortunately, pipelining isn’t well supported by web browsers due to implementation difficulties and as a result, it’s rarely used.
However, even if that wasn’t the case, pipelining is still prone to another problem known as head-of-line (HOL) blocking.
What’s HOL, you may ask?
Well - imagine a road connecting point A with point B that’s wide enough for just one truck.
If we need to bring goods from B to A on this road, a truck starts its journey from A, loads the goods at B, and drives back to A. Multiple trucks can travel on the road, but they should all follow a queue. If the truck at the head of the queue gets blocked, all the trucks behind it are also blocked.
The same concept applies on the network.
In other words, a blocked request at the head of the queue can block all the requests behind it.
2 - Use Multiple HTTP Connections
So - how do you deal with a problem like HOL blocking?
Well, in line with the road analogy, you can build multiple lanes. In the case of network, this means opening more connections between the client and the server.
This is why most browsers support six connections per domain.
But are six connections enough?
Apparently not!
And that’s the reason why many websites serve static assets such as images, CSS and JavaScript from subdomains or other domains. With each new subdomain, they get six more connections to play around with.
This technique is known as Domain Sharding.
For reference, stackoverflow.com loads the various assets from different domains as shown below:
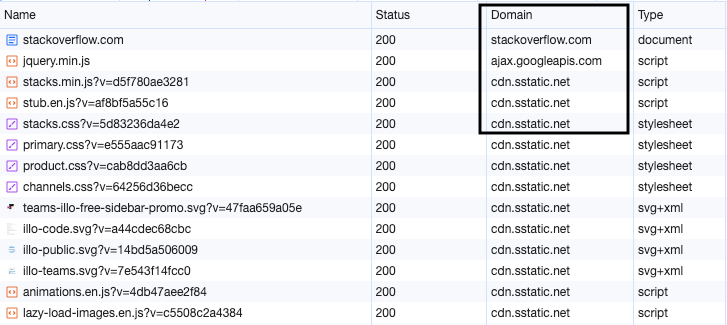
Domain Sharding seems like a perfect solution to the problems of HTTP/1.1.
But it also has downsides.
Starting a TCP connection takes time and maintaining the connection requires extra memory and processing. This is a price both client and server have to pay when multiple HTTP connections are used.
If you recall from previous section, TCP requires a three-way handshake to set up.
Why is that so?
Because TCP is a guaranteed protocol. It sends packets with a unique sequence number and re-requests any packets that get lost on the way by checking for missing sequence numbers.
Here’s how it works:
The client sends a synchronization (SYN) message to the server. This message is like a note to the server that some TCP packets are on the way and these are the sequence numbers that the server should watch out for.
The server acknowledges the sequence numbers from the client. In return, it replies back with its own synchronization request. In other words, the server tells the client what sequence numbers it will be using for its response message. Both of these are combined into a SYN-ACK message
Finally, the client acknowledges the server’s sequence numbers with an ACK message and the handshake is complete.
Check out the below illustration:

As you can see, this handshake process adds 3 network trips before you can think about sending an HTTP request.
But that’s not all!
To top it up, TCP also follows a slow-start algorithm.
Slow Start is a congestion control algorithm.
It’s job is to prevent network congestion by gradually increasing the amount of data sent until a threshold, known as the "congestion window" or CWND is reached.
This basically means that TCP starts cautiously by sending a small number of packets.
For each successful acknowledgment by the server, the congestion window is increased exponentially as the connection proves itself capable of handling larger data sizes without losing packets.
However, since all of these packets need to acknowledged, it may take several TCP acknowledgements before the full HTTP request and response messages can be sent over the connection.
3 - Make Fewer Requests
At this point, you might wonder that if the problem with modern web is the need to make so many requests, why not optimize around that?
Why not make fewer requests?
And of course, this is already being done.
Browsers cache assets all the time.
Assets are bundled together into combined files.
For example, images are bundled using a technique known as spriting. Rather than using one file for each icon, you can bundle them into one large image file and use CSS to pull out sections of the image to re-create the individual images.
In the case of CSS and JavaScript, multiple files are concatenated into fewer files. Also, you minimize them by removing whitespaces, comments and other elements.
However, all of these activities require effort.
Creating image sprites is a costly process and requires development effort to rewrite the CSS to load images correctly. Build steps to concatenate JS and CSS are not used by all websites.
The Rise of HTTP/2
In 2015, HTTP/2 was created to address the specific performance problems in HTTP/1.1.
It brought some cool improvements to deal with the limitations of the TCP protocol.
1 - Binary Framing Layer
HTTP/1.1 transfers messages in plain-text format. That’s easy for humans to understand but more difficult for computers to parse.
In contrast, HTTP/2 encodes the messages into binary format.
This allows the messages to be split and sent over the TCP connection in clearly defined frames.
What are these frames, you may ask?
They are basically packets of data not so different from TCP packets. Each frame is embedded in a stream. In fact, the Data and Header sections of an HTTP request are separated into different frames
All of this encoding magic is performed by a special component of the protocol known as the Binary Framing Layer.

The good news is that despite this conversion, HTTP/2 maintains the same HTTP semantics as 1.1. You have the same HTTP methods and headers. So, web applications created before HTTP/2 can continue functioning as normal while using the new protocol.
A few important benefits due to binary format:
Better efficiency while parsing messages
More compact
Less error prone since HTTP/1.1 had to rely on many “helpers” to deal with whitespaces, capitalization, line endings etc.
2 - Multiplexing
The Binary Framing Layer allows full request and response multiplexing.
What does that even mean?
Imagine a large family going from City A to City B to attend an event. They travel in the same lane, but in different cars that are more or less moving together. Once they reach City B, they all join together for the event.
Quite similar to this, clients and servers can now break down an HTTP message into independent frames, interleave them during transmission and reassemble them on the other end.
To make things clear, consider the below diagram. It shows how HTTP/1.1 uses three TCP connections to send and receive three requests (blue, green and black) in parallel.

Request 1 (blue) fetches the styles.css. Request 2 (green) downloads script.js and Request 3 (black) gets the image.jpg file. All of these requests use a separate TCP connection.
On the other hand, HTTP/2 allows multiple requests to be in progress at the same time on a single TCP connection.
The only difference - each HTTP request or response uses a different stream.
Streams are made up of frames (such as header frames or data frames) and each frame is labeled to indicate which message (or stream) it belongs to.
See the below diagram that shows the same three requests in the HTTP/2 approach.

As you can see, the three requests (blue, green, and black) are sent one after the other and the responses are sent back in an intermingled manner.
This wasn’t possible in HTTP/1.1 pipelining.
Basically, HTTP/2 ensures that the connection isn’t blocked after sending a request until the response is received.
3 - Stream Prioritization
When a website loads a particular asset (HTML, CSS, JavaScript or some image), the order matters. For example, you can’t have the CSS load at the end because that will make the page look deformed for the first few seconds, degrading the user experience.
With HTTP/1.1, managing this was easy.
Since it followed a single request-and-response protocol, there was no need for prioritization by the protocol as such. The client decided the priority.
However, with HTTP/2, the response to the browser may be received back in any order. And if you don’t manage the priority of the assets, you can end up with pages loading slower as compared to HTTP/1.1
Steam Prioritization was the answer to this issue.
It allows developers to customize the relative weight of requests (and streams) to optimize performance. The browser can indicate priorities for the respective assets or files and the server will take care to send more frames for higher-priority requests.
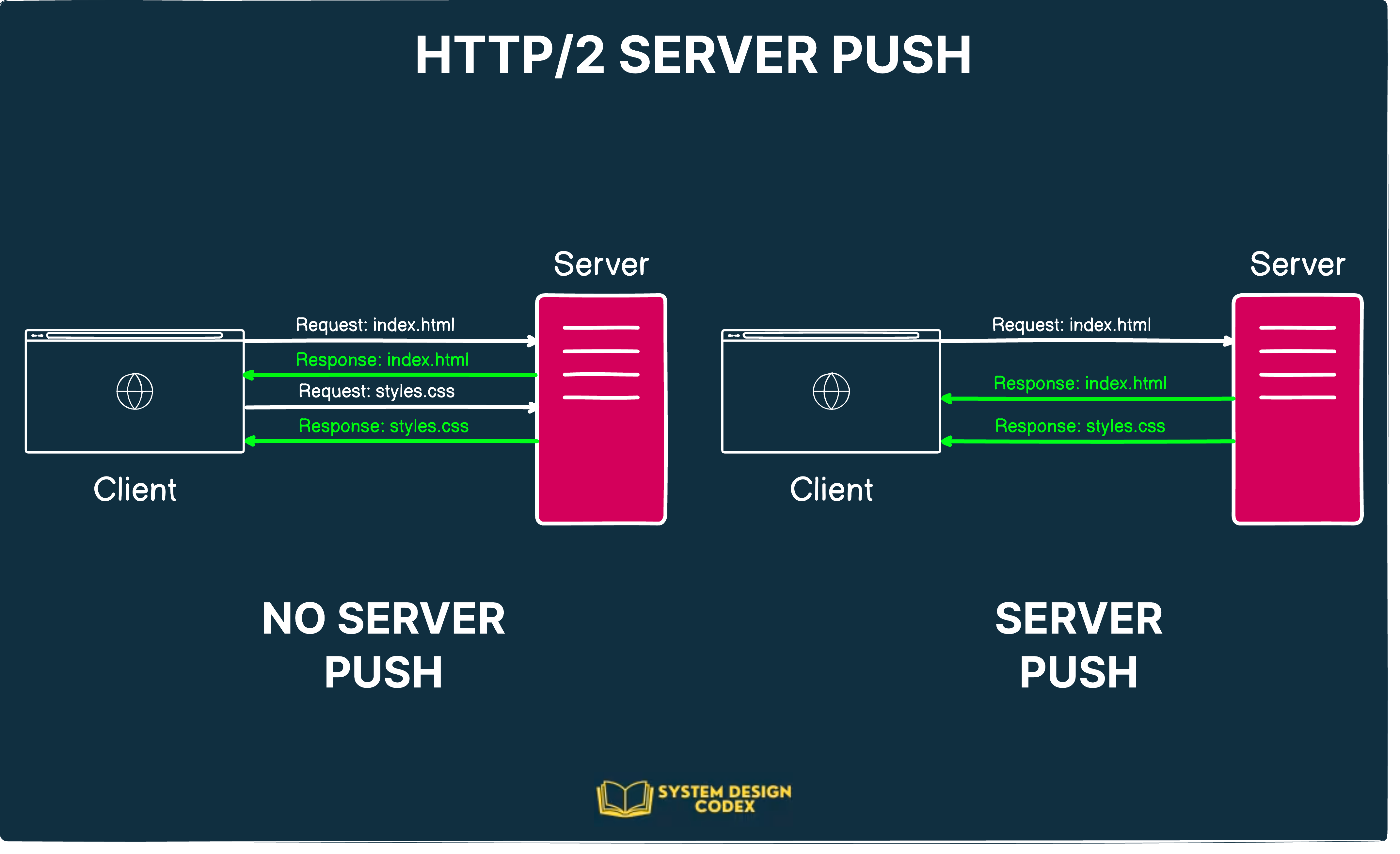
4 - Server Push
Another feature supported by HTTP/2 is the Server Push.
Since HTTP/2 enables multiple concurrent responses to a client’s request, a server can send additional resources to a client along with the requested HTML page.
This is essentially providing the resource before the client even asked for it. Hence, the name Server Push.
From the client’s perspective, they can decide to cache the resource or even decline the resource.
Check out the below diagram that shows what Server Push means:
5 - Compression
What’s a common method to optimize your web applications for performance?
It’s compression.
Even in the HTTP/1.1 world, using programs like gzip is quite common for compressing the data sent over the network.
However, the header component of the message is still sent as plain text.
But a header is quite small, you may think. How can it impact the performance?
However, modern API-heavy applications require many resources resulting in a huge number of requests. With each request, the overall weight of the headers grows heavier and heavier.
To solve this problem, HTTP/2 uses HPACK compression to shrink the size of headers.
But what is HPACK?
As you saw earlier, the Binary Framing Layer allows HTTP/2 to split headers from their data, resulting in a separate header frame and a data frame.
HPACK (a HTTP/2 specific compression program) can then compress this header frame using special algorithms. Also, HPACK can keep track of previously sent metadata fields and compresses them further.
Check out the below illustration:

As you can see, the various fields in Request 1 and Request 2 have more or less the same value. Only the path field uses a different value.
Therefore, HTTP/2 can use HPACK to send only the indexed values required to reconstruct these common fields and just encode the path field for Request 2.
Conclusion
To conclude things, HTTP/2 has fixed a lot of shortcomings that were holding HTTP/1.1 back.
It makes better use of network bandwidth, resolves the head-of-line blocking problem of HTTP/1.1 and provides better compression. At this point, HTTP/1.1 and HTTP/2 are the dominant protocols being used and HTTP/2 is becoming more prevalent.
Having said that, the web is continuously evolving and there are still shortcomings with HTTP/2 and underlying TCP protocol.
This led to the birth of HTTP/3. But more on that in a future post.
🍔 Food For Thought
Follow tutorials but don’t forget the errors
Tutorials are great for picking up new frameworks and tools. You can’t always get the chance to learn new things on the job.
But many tutorials just focus on the happy path.
While there’s nothing wrong with it if you are a beginner, it’s a good idea to also learn how to deal with errors as soon as you gain some experience.
The below post sums it up quite well and also provides a couple of tips.
Here’s the link to the post:
https://x.com/deisbel/status/1741163520232731132?s=20
That’s it for today! ☀️
Enjoyed this issue of the newsletter?
Share with your friends and colleagues
See you next week with another value-packed edition — Saurabh
Well documented, thank you