
How to Improve a System's Scalability?
And what exactly is scalability?

At its core, scalability refers to the system’s ability to handle increasing workloads without a drop in performance. But that’s only the surface-level view.
To truly design scalable systems, we must go deeper and look at scaling as a strategy—one that must remain technically sound and cost-effective as the workload continues to grow. In this article, we’ll examine what scalability really means, the common bottlenecks that stand in the way, and the most widely adopted patterns and techniques to improve scalability in real-world systems.
The True Definition of Scalability
We often define scalability as the ability of a system to "handle more load." But what makes a system truly scalable is whether it can keep handling more load by repeatedly applying a cost-efficient strategy.
For example, imagine you have a web application that performs well with 100 users. If performance drops when 1,000 users arrive, and your only solution is to buy ten times more infrastructure, that may work once, but it’s not sustainable or efficient.
Scalability, therefore, isn’t just about capacity. It’s about the strategy behind increasing that capacity.
Common Bottlenecks to Scalability
Before we look at solutions, let’s understand what commonly blocks scalability in systems:
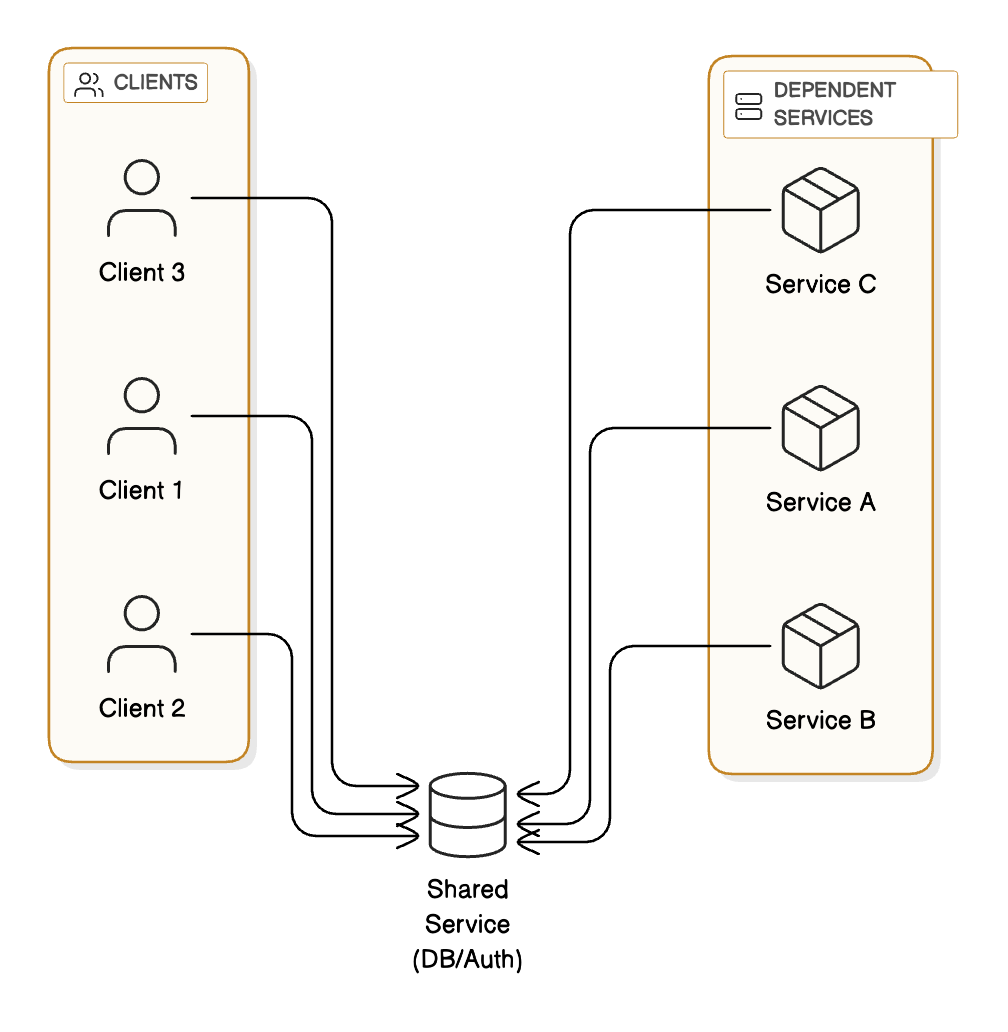
1 - Centralized Components
When a single service (like a database or authentication service) handles all requests, it becomes a single point of failure. This component’s limits are the system’s limits. If it fails, everything fails.
2 - High-Latency Components
Some operations (such as complex joins, synchronous API calls, or intensive data processing) take time. These slow down the request path and can cause cascading delays when the load increases.
3 - Tight Coupling Between Services
In tightly coupled systems, services rely heavily on one another and cannot evolve or scale independently. This lack of modularity makes scaling harder, as scaling one part often means scaling all of it.
Principles for Building Scalable Systems
To overcome these bottlenecks, we must embrace architectural principles that allow our systems to grow smoothly:
Statelessness: Stateless services don’t retain user session data between requests. This allows you to easily spin up new instances without worrying about state synchronization.
Loose Coupling: Services should be independent and interact through well-defined interfaces. This means that you can scale or modify one service without affecting others.
Asynchronous Processing: Long-running tasks should be processed in the background using queues or event-driven architectures. This keeps the system responsive even under load.
Scalability Techniques You Should Know
Once we have the right principles in place, we can start applying specific techniques to improve scalability. Let’s look at a few that are commonly used in production systems:
1 - Load Balancing
A load balancer distributes incoming traffic across multiple servers or instances. This prevents any single server from becoming overloaded and allows you to add more servers to handle growing traffic.
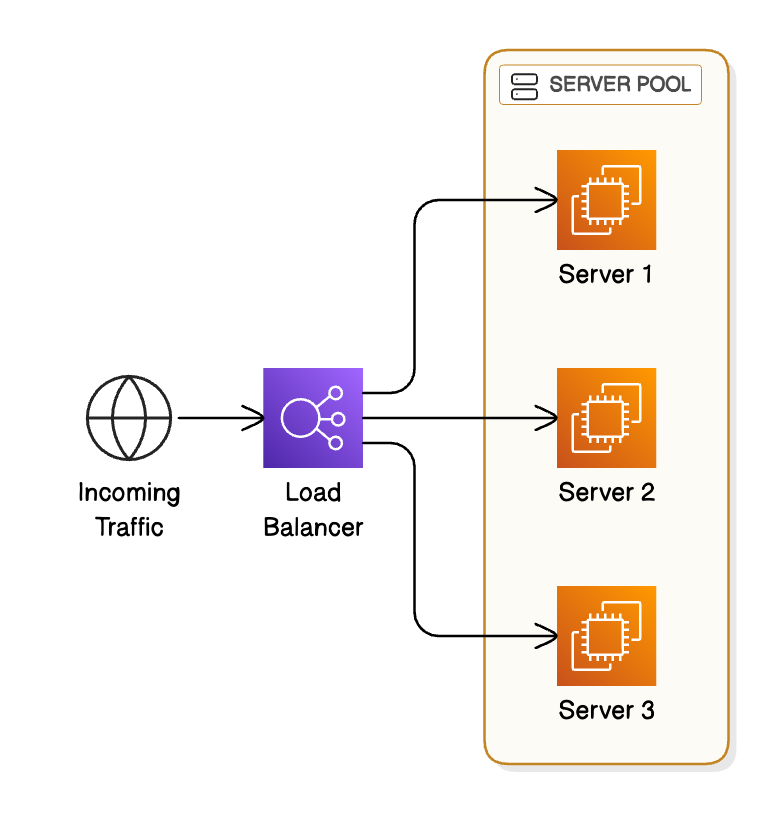
Common tools: NGINX, HAProxy, AWS ELB
Types: Round-robin, least connections, IP hash, etc.
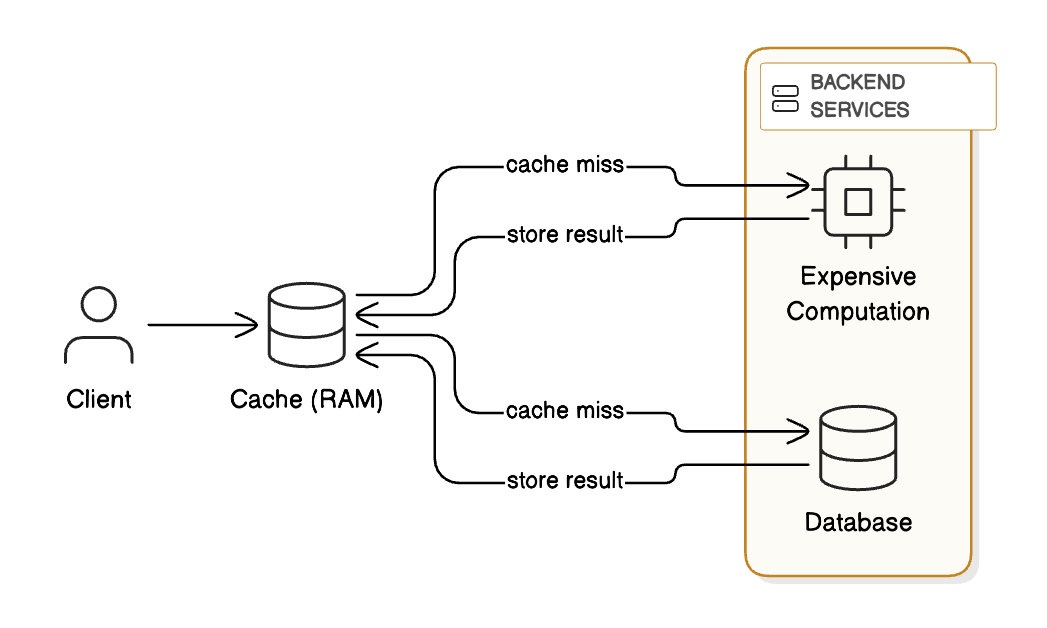
2 - Caching
Caching stores frequently accessed data in memory (RAM), reducing the need to repeatedly query the database or perform expensive computations.
Cache types: In-memory cache (Redis, Memcached), CDNs for static files
Use cases: User sessions, popular products, config data
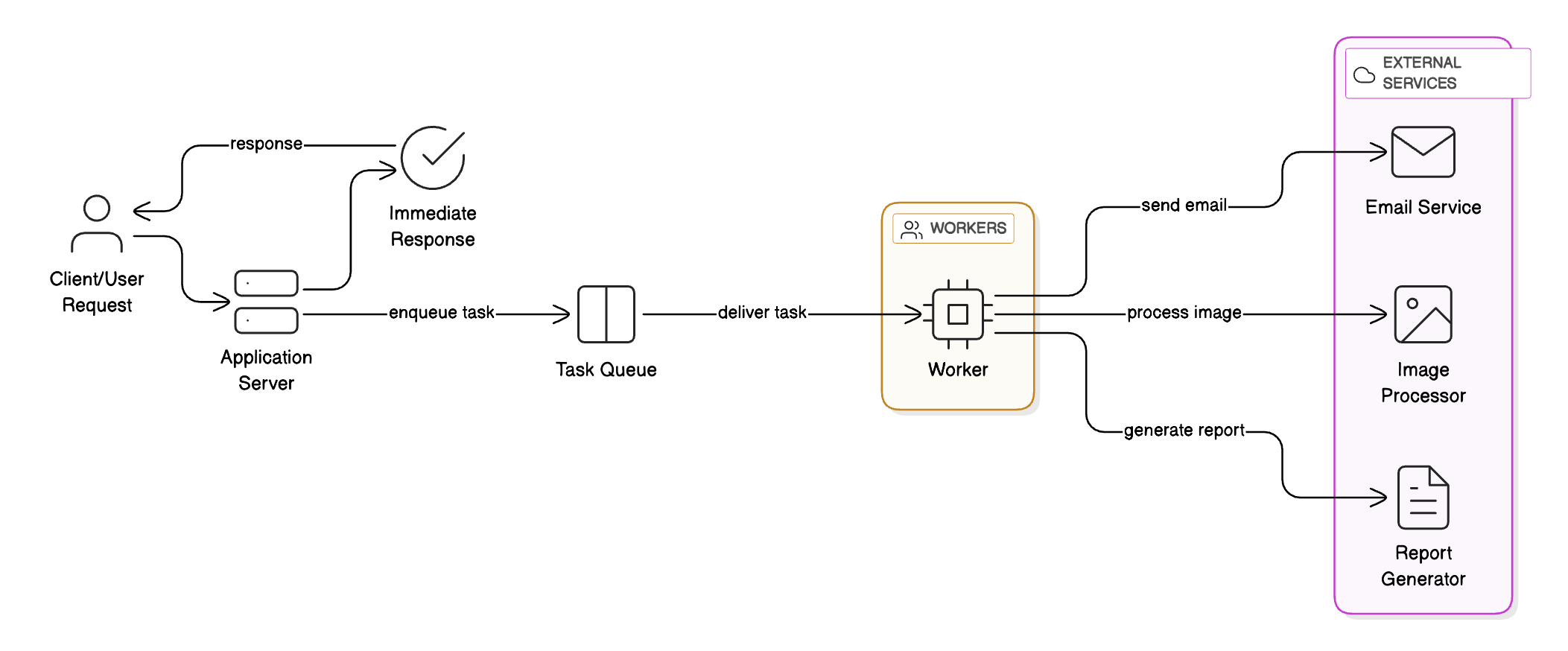
3 - Event-Driven Processing
Instead of processing everything synchronously, you can push tasks to a queue and process them later. This is especially useful for non-urgent or time-consuming operations like sending emails, image processing, or generating reports.
Tools: Apache Kafka, RabbitMQ, Amazon SQS
Benefits: Improves responsiveness, handles traffic spikes smoothly
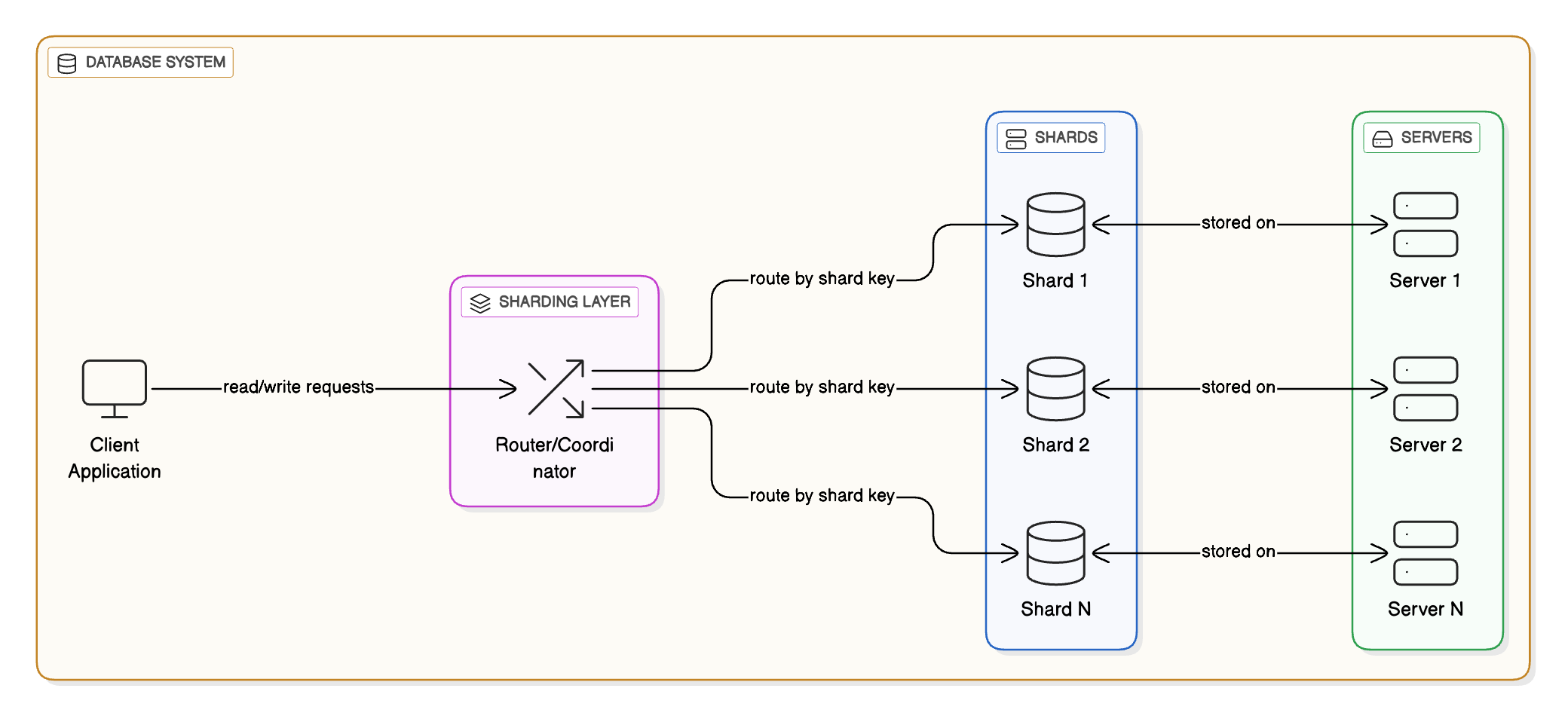
4 - Sharding (or Partitioning)
As databases grow, they can become performance bottlenecks. Sharding splits the data into smaller subsets (called shards) and distributes them across multiple servers.
Sharding can be done horizontally (splitting rows) or vertically (splitting tables by domain).
Ensures that no single server has to store or manage the entire dataset, improving both performance and fault isolation.
Cost vs Scale: The Real Trade-off
A system that scales linearly but also increases cost linearly may not be viable in the long run. That’s why scalability also involves making sure each unit of increased capacity is affordable.
For example, doubling your user base shouldn’t mean doubling your infrastructure costs. The most scalable systems find clever ways to reuse resources, optimize workloads, and degrade gracefully when needed.
Final Thoughts
Scalability isn’t just an infrastructure problem. It’s an architectural mindset.
To build truly scalable systems, developers need to:
Understand the bottlenecks,
Follow the right design principles,
And apply proven scaling techniques that balance performance and cost.
Remember, the earlier scalability is considered in your system design, the fewer painful rewrites you'll need when traffic actually grows.
👉 So - how do you approach scalability in your systems?
Shoutout
Here are some interesting articles I’ve read recently:
The #1 Mistake in Unit Testing (and How to Fix It) by Daniel Moka
The 17 biggest mental traps costing software engineers time and growth by Fran Soto
That’s it for today! ☀️
Enjoyed this issue of the newsletter?
Share with your friends and colleagues.
Awesome 👌