
How Reddit Serves 100K Metadata Requests Per Second
Using good ol' Postgres

Reddit is like the front page of the Internet.
It hosts billions of posts. And a lot many of these posts contain media content such as images, videos, gifs, and so on.
While the media content is often stored in object storage, the metadata needs to be stored elsewhere. For example, if you’ve got a video, you might need to store information such as the thumbnail URL, playback URLs, bitrates, and various resolutions.
Reddit had a big problem with this metadata.
While their systems had the information, it was scattered across multiple systems. Media data used for traditional image and video posts was stored with post data, whereas media data related to chats and other types of posts was stored in a different database.
This made it difficult for them to analyze and categorize the metadata. Auditing changes became tough. Even checking information about a specific image or video required them to query the S3 bucket.
To solve these challenges, the Reddit Engineering team decided to build a media metadata store.
Requirements of the Metadata Store
There were several requirements for the new metadata store:
Move all existing media metadata from different systems into a unified storage. In other words, migrate existing data to the new database.
Support data retrieval to the tune of over 100K read requests per second with very low latency (less than 50 ms).
Support media creation and updates.
After evaluating multiple choices, the Reddit Engineering Team went for AWS Aurora Postgres.
The diagram below shows a high-level architecture of their media metadata storage system.

The API service interfaces with the database to handle both reads and writes. To manage the connection pooling, they use pgBouncer as the proxy for connecting to Postgres.
Just so you know, pgBouncer is a lightweight connection pooler for Postgres.
Data Migration Process
While setting up a new Postgres database is easy, the real challenge lies in migrating terabytes of data from one database to another while serving 100K requests per second.
It’s like changing a car’s tires while you are driving it.

The consequences of the new database having the wrong media metadata could spell disaster for the website.
The migration was handled as follows:
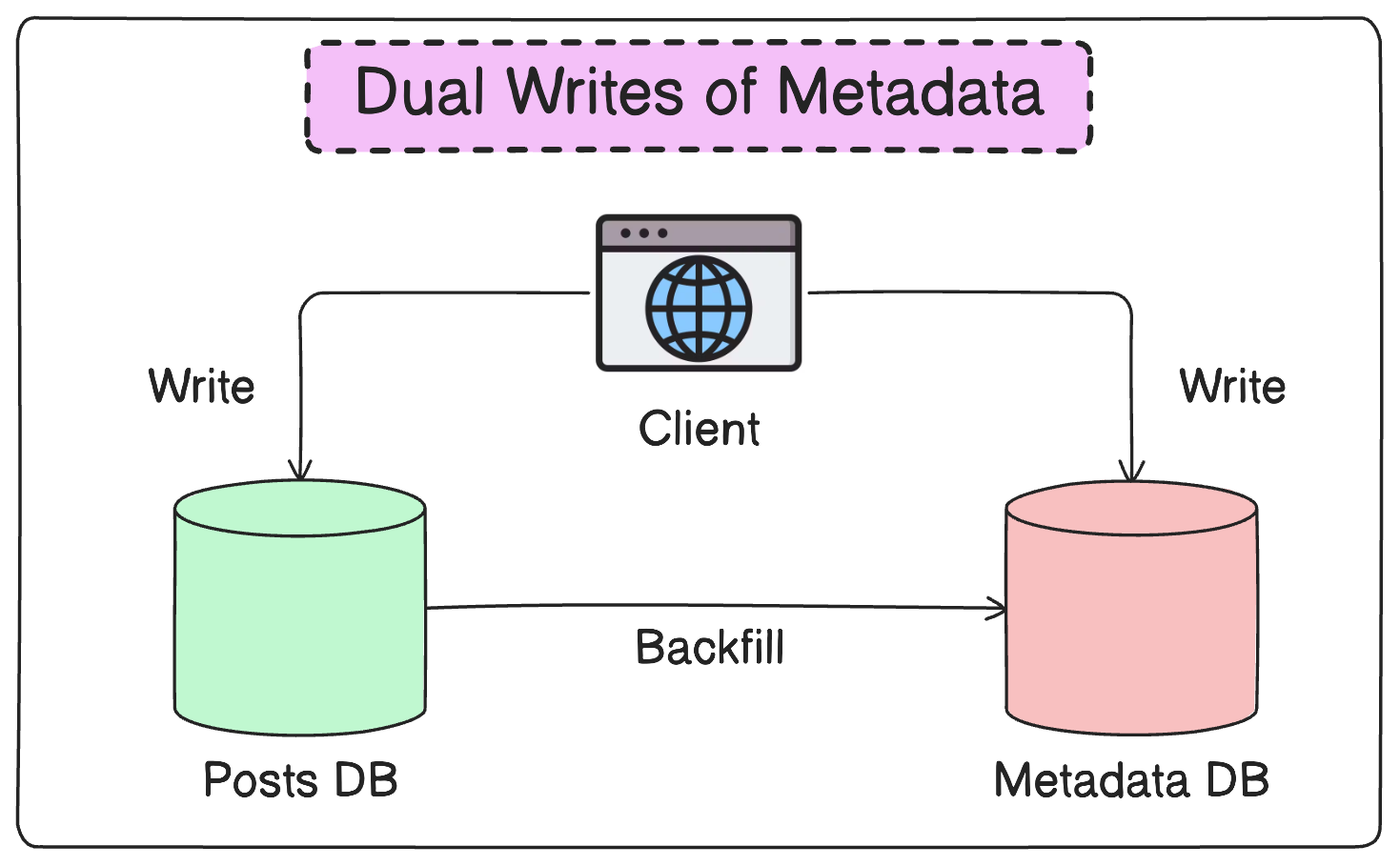
Enable dual writes into both the new and old databases from the clients of media metadata. This ensures that any new metadata is stored in the new database.
Backfill data from older databases to the metadata store.
Next, enable dual reads on media metadata from our service clients.
Compare the output of the reads and fix any data gaps.
Ramp up read traffic to the new database.
Here’s what the dual writes and backfill part looks like.
Dealing with Issues
While the overall approach is fine from a happy path perspective, that’s not always the case in real software development.
Some issues that could come up are as follows:
Data transformation bugs in the service layer.
Writes to the new metadata store could fail and the writes to the source database succeed resulting in inconsistent data.
The backfill process during migration can overwrite newer data from the service write.
To handle these scenarios, the Reddit team built a more robust solution as shown below:

Here is what’s going on:
The client dual writes to the new database and the old database.
A Kafka consumer listens to the stream of data change events from the source database. This is done using a Change Data Capture (CDC) process.
The consumer performs data validation with the media metadata store to check inconsistencies.
In case of any inconsistency, the consumer reports the differences to another database so that engineers can take a look and fix the issues.
What about Scaling?
The new media metadata store was heavily optimized for reads, helping Reddit achieve a p50 latency of 2.6 ms and p99 latency of 17 ms at 100K requests per second.
However, the data volume is also quite high and according to their estimates, the media metadata can reach 50 TB by 2030.
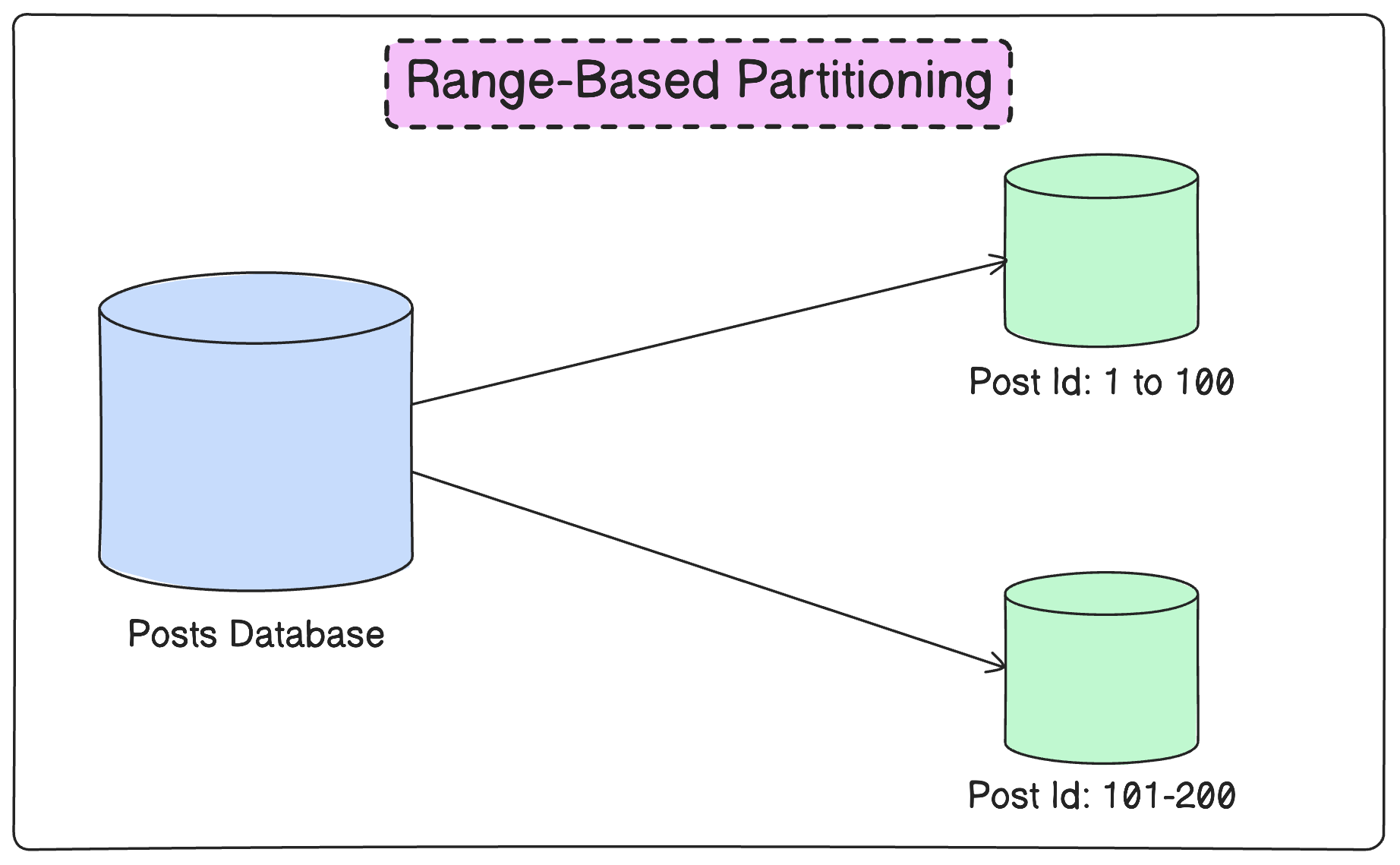
To handle this scalability challenge, Reddit has implemented partitioning in Postgres using an extension known as pg_partman.

The above SQL statement is scheduled using the pg_cron scheduler to create new partitions when the number of spare partitions goes below a certain number.
They used range-based partitioning instead of hash-based partitioning for the partition key post_id.
This is because range-based partitioning on a monotonically increasing field such as post_id automatically ensures the partitions are created based on distinct time periods.
Since most read requests at Reddit target recent posts, it allows the Postgres engine to cache the indexes of the most recent partitions in its buffer pool. In other words, less Disk I/O and better performance.
So - what do you think about Reddit’s solution to the metadata problem?
Would you have done something differently?
References:
Shoutout
Here are some interesting articles I’ve read recently:
That’s it for today! ☀️
Enjoyed this issue of the newsletter?
Share with your friends and colleagues.
See you later with another edition — Saurabh
It's quite incredible to see what kind of problems occur at such a scale. I have no idea how I would have done it. On the other hand, I'm relieved that the cat videos I upload go through Kafka, pgBouncer, and Aurora. 😃
And of course, thanks for the shoutout! 🙇♂️ Glad you liked this article.
Interesting read. Thanks for Sharing