
How Kubernetes Works Internally?
A High-Level Overview

Kubernetes is a powerful open-source container orchestration platform originally developed at Google and now maintained by the Cloud Native Computing Foundation (CNCF).
Kubernetes (or K8s for short) helps you automate the deployment, scaling, and management of containerized applications.
But how does Kubernetes actually work behind the scenes?
Let’s break it down in a simple manner.
The Developer’s Starting Point
From a developer’s perspective, the interaction with Kubernetes begins with writing manifest files, typically written in YAML or JSON.
These manifest files define the desired state of your application, such as:
What containers should be running?
How many replicas (instances) do you want?
What ports should be exposed?
What environment variables or configurations are needed?
Think of it like telling Kubernetes, “Here’s what I want my app to look like. Please make it happen—and keep it that way.”
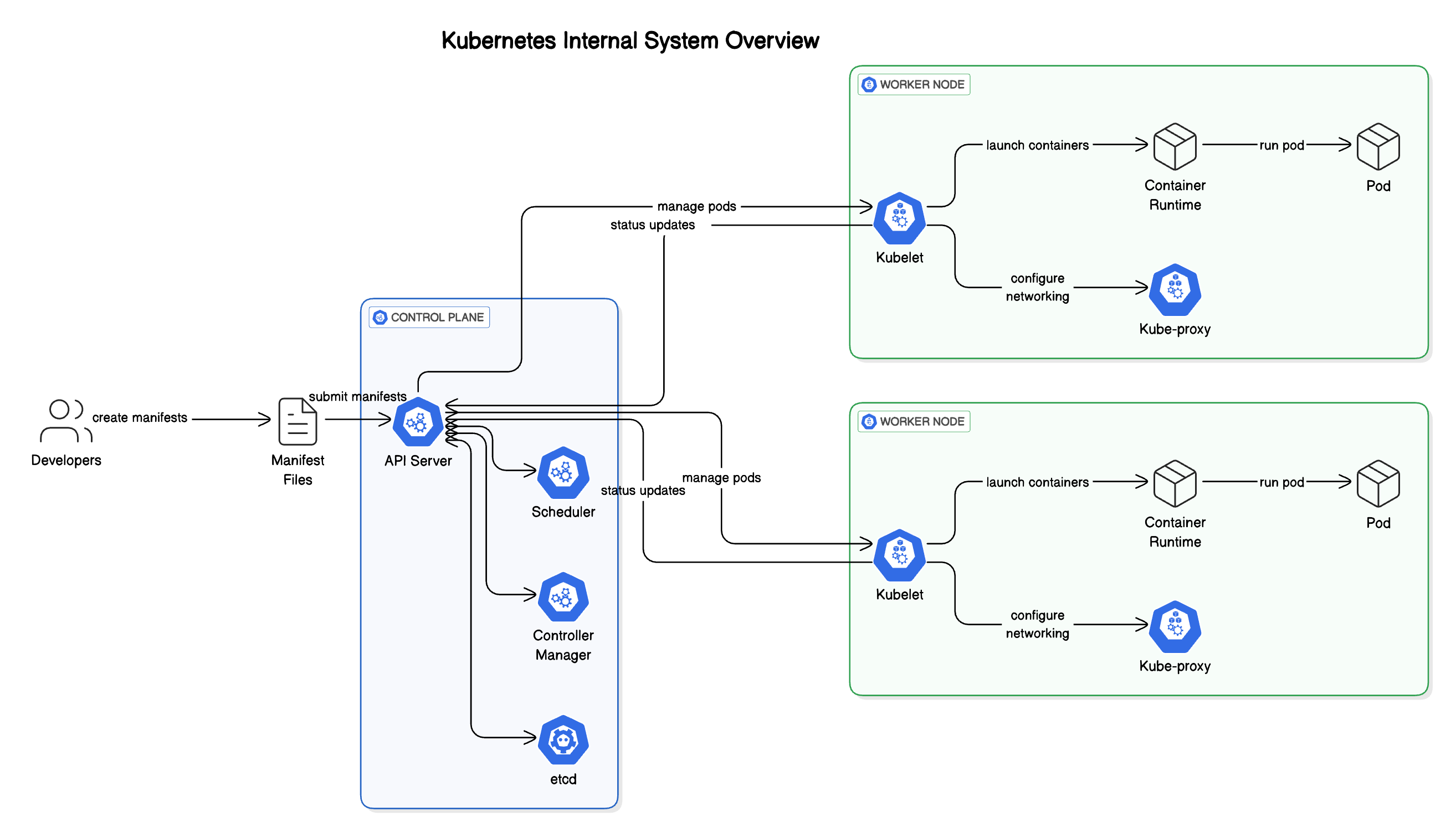
Step 1: The Control Plane
Once a manifest is submitted (usually via the kubectl CLI), it enters the Kubernetes Control Plane, which is essentially the central nervous system of the cluster.
Here are the key components that make it tick:
🔹 1. API Server
This is the front door of the Kubernetes cluster. Every command, configuration, or request from developers, CI/CD systems, or dashboards hits the API Server first.
Validates and processes the manifest files.
Acts as the gateway to all control plane operations.
All internal components and external users interact with Kubernetes via this API.
🔹 2. Scheduler
Once the API server accepts a new workload (like a Pod), it’s the Scheduler’s job to decide where to run it.
It looks at the cluster’s current state—how much CPU, memory, and resources each node has.
Applies any constraints or affinity rules.
Chooses the most suitable node for the new Pod.
In simple terms, it’s the placement engine.
🔹 3. Controller Manager
The Controller Manager keeps everything in sync. Its main job is to constantly monitor the system and ensure that the actual state of the cluster matches the desired state.
If a Pod crashes or a node fails, the Controller Manager will recreate the Pod somewhere else.
Manages resources like Deployments, ReplicaSets, Nodes, and more.
It’s like the autopilot that constantly checks, “Is everything running the way the user asked for?”
🔹 4. etcd
This is the database of Kubernetes. It stores all the configuration data, state of the cluster, and details about workloads.
A distributed key-value store.
Highly consistent and fault-tolerant.
Every component in the control plane relies on
etcdto know what the cluster looks like.
If Kubernetes had a memory, etcd is where it lives.
Step 2: Worker Nodes
Once the control plane decides what to run and where, the actual execution happens on the Worker Nodes.
Each node is a physical or virtual machine in the cluster that runs your application containers.
Let’s look at the components that power each worker node:
🔹 1. Kubelet
Kubelet is the node agent. It communicates with the API Server to get instructions on what to run and monitors the health of running containers.
Ensures the containers defined in the Pod are up and healthy.
Reports the node and Pod status back to the control plane.
Restarts containers if they crash.
Without Kubelet, the node wouldn’t know what to do.
🔹 2. Kube-proxy
This is the networking glue. Kubernetes assigns each Pod its own IP address, and kube-proxy helps route traffic to and from these Pods.
Handles Service Discovery and Load Balancing.
Routes incoming traffic to the appropriate Pods.
Works with iptables or IPVS to manage network rules.
It’s like the air traffic controller of the node.
🔹 3. Container Runtime
Finally, there’s the container runtime, such as containerd, Docker, or CRI-O.
This is the actual software that pulls container images and runs them.
Kubernetes doesn’t run containers directly—it uses the runtime as an engine.
You can think of the container runtime as the engine room, turning commands into running containers.
Step 3: Continuous Reconciliation
What makes Kubernetes truly powerful is that it constantly reconciles the actual state of your cluster with the desired state defined in your manifests.
If a node goes down, it moves Pods elsewhere.
If a container crashes, it restarts it.
If you change your deployment config, it rolls out updates.
This ongoing self-healing behavior is one of the reasons Kubernetes has become the default platform for modern application deployment.
So - have you used Kubernetes?
Shoutout
Here are some interesting articles I’ve read recently:
Why Just Publishing Events Isn’t Enough by Raul Junco and Marcos F. Lobo 🗻
Open-Closed Principle (OCP) In React: Write Extensible Components by Petar Ivanov
That’s it for today! ☀️
Enjoyed this issue of the newsletter?
Share with your friends and colleagues.
Nice read
That's an awesome breakdown of Kubernetes. I wish you had written this article 1.5 years ago. :D
Great job, Saurabh!