
How Consistent Hashing Works?
An introduction...

The concept of Consistent Hashing often comes up in interviews. However, I’ve seen people struggle while trying to explain it.
In today’s post, we’ll look at the process of consistent hashing in a step-by-step manner so that it becomes easier to understand and explain.
But before moving further, a quick thanks to the sponsor for today’s edition, who help keep this newsletter free for the readers.
📣 Fix Code Review Anti-Patterns & Cut Bugs in Half with CodeRabbit (Sponsored)

Tired of catching the same code review issues over and over? Want to transform code reviews from bottlenecks into learning opportunities?
Meet CodeRabbit - your AI-powered code review companion.
It helps teams merge code changes faster while maintaining superior quality. Unlike traditional tools, CodeRabbit doesn't just flag issues — it provides intelligent fix suggestions with clear explanations, turning every review into a learning moment. With AI-powered, context-aware analysis and 1-click fixes, your team can focus on building great features instead of debating code patterns.
CodeRabbit provides:
• Automatic PR summaries and file-change walkthroughs.
• Runs automated linting on popular linters like Biome, Ruff, PHPStan, etc.
• Highlights code and configuration security issues.
• Enables you to write custom code review instructions and AST grep rules.
To date, CodeRabbit has reviewed more than 5 million PRs, is installed on a million repositories, has 15k+ daily developer interactions, and is used by 1500+ organizations.
PS: CodeRabbit is free for open-source.
All right, let’s move back to our goal of understanding consistent hashing.
Consistent Hashing is a technique used for distributing keys uniformly across a cluster of nodes.
The primary focus behind consistent hashing is to minimize the number of keys that need to be moved around when we add or remove a node from the cluster.
The below steps demonstrate how consistent hashing works:
STEP 1
The keys are hashed using a hash function.
The output range of these key values is treated as a fixed circular space or ring. For example, in the diagram below, K1, K2, K3, and K15 are the positions of the keys on the hash ring.
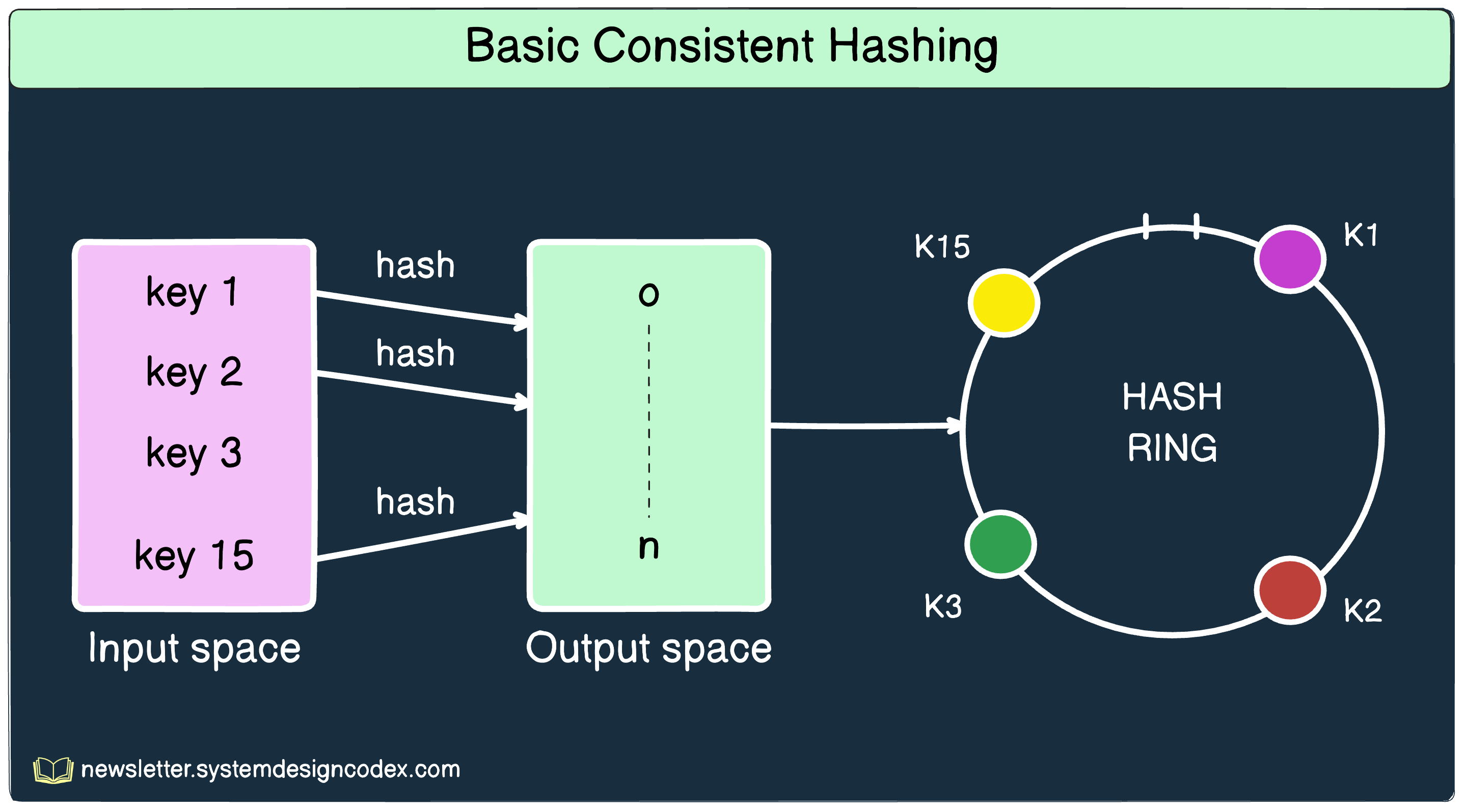
STEP 2
Next, the servers or nodes are also hashed using the IP address or the domain name as input.
We use the same hashing function to determine their respective positions on the ring.
See the below diagram:

STEP 3
Lastly, for every key, we traverse the ring in a clockwise direction starting from the position of the key.
Once a node is found, we store the key on that node.
See the below diagram:

Virtual Nodes in Consistent Hashing
Virtual nodes (often abbreviated as "v-nodes") are a technique used in consistent hashing to address load balancing and uneven data distribution.
Instead of mapping a single physical node to one position on the hash ring, each physical node is mapped to multiple positions, creating "virtual nodes". These positions are determined by applying a hash function multiple times with different input variations (e.g., appending a unique identifier like NodeID-1, NodeID-2, etc.).
For example, each physical node has 3 virtual nodes. After hashing, the virtual nodes might be distributed on the ring as follows:
Node A: Virtual nodes A1, A2, A3
Node B: Virtual nodes B1, B2, B3
Node C: Virtual nodes C1, C2, C3
Keys (data) are hashed onto the ring and assigned to the first virtual node encountered while moving clockwise.
Key K1 might fall near B2, so it is assigned to Node B.
Key K2 might fall near A3, so it is assigned to Node A.
Since there are more positions (virtual nodes) on the ring, the data distribution is more evenly spread across physical nodes. Even if one key hashes poorly to a specific ring area, the effect is diluted across the multiple virtual nodes for each physical node.
On the downside, virtual nodes increase the size of the metadata the system needs to track, as multiple entries represent each physical node.
Advantages of Consistent Hashing
There are multiple advantages of consistent hashing:
Scalability: Adding or removing nodes in the system only affects a small portion of the data, rather than requiring all data to be reassigned. This makes it ideal for distributed systems with dynamic membership.
Load Balancing: By using techniques like virtual nodes (assigning multiple positions for each physical node), consistent hashing ensures a more balanced data distribution across servers.
Fault Tolerance: When a node fails, only its keys need to be redistributed to other nodes. The rest of the system continues to function smoothly.
Disadvantages of Consistent Hashing
Consistent hashing also has some disadvantages that should be kept in mind:
Imbalance Without Virtual Nodes: Without virtual nodes, the natural distribution of keys can be skewed, leading to uneven loads across nodes.
Dependency on Hash Function: The quality of the hash function directly affects the balance of the distribution. A poorly chosen hash function can lead to clustering or inefficiencies.
Use Cases
Consistent hashing is widely used in various solutions. Here are a few important examples:
Distributed Databases: Ensures even data distribution and minimal disruption when nodes are added or removed (e.g., Amazon DynamoDB).
Caching Systems: Balances requests across cache servers and minimizes cache misses after server changes (e.g., Memcached).
Content Delivery Networks (CDNs): Balances file storage and retrieval across geographically distributed servers.
👉 So - have you used Consistent Hashing?
Shoutout
Here are some interesting articles I’ve read recently:
That’s it for today! ☀️
Enjoyed this issue of the newsletter?
Share with your friends and colleagues.
See you later with another edition — Saurabh
Consistent hashing is one of the main reasons distributed systems scale so well—it keeps things balanced even when nodes come and go.
Thanks for the shoutout, Saurabh!
You outlined it pretty simply, Saurabh. Now I understand it :D