
How Amazon S3 Works Behind the Scenes
It has many sub-components

Amazon S3 (Simple Storage Service) is one of the largest and most sophisticated distributed storage systems in the world. It processes millions of requests per second, stores over 350 trillion objects, and achieves 11 nines of durability (99.999999999%).
But what makes S3 so powerful isn’t just its size—it’s the architecture that allows it to scale, stay reliable, and keep data safe across the globe.
S3 is built using a microservices-based architecture, where different components handle different responsibilities. Let’s break it down step by step to understand how it works.
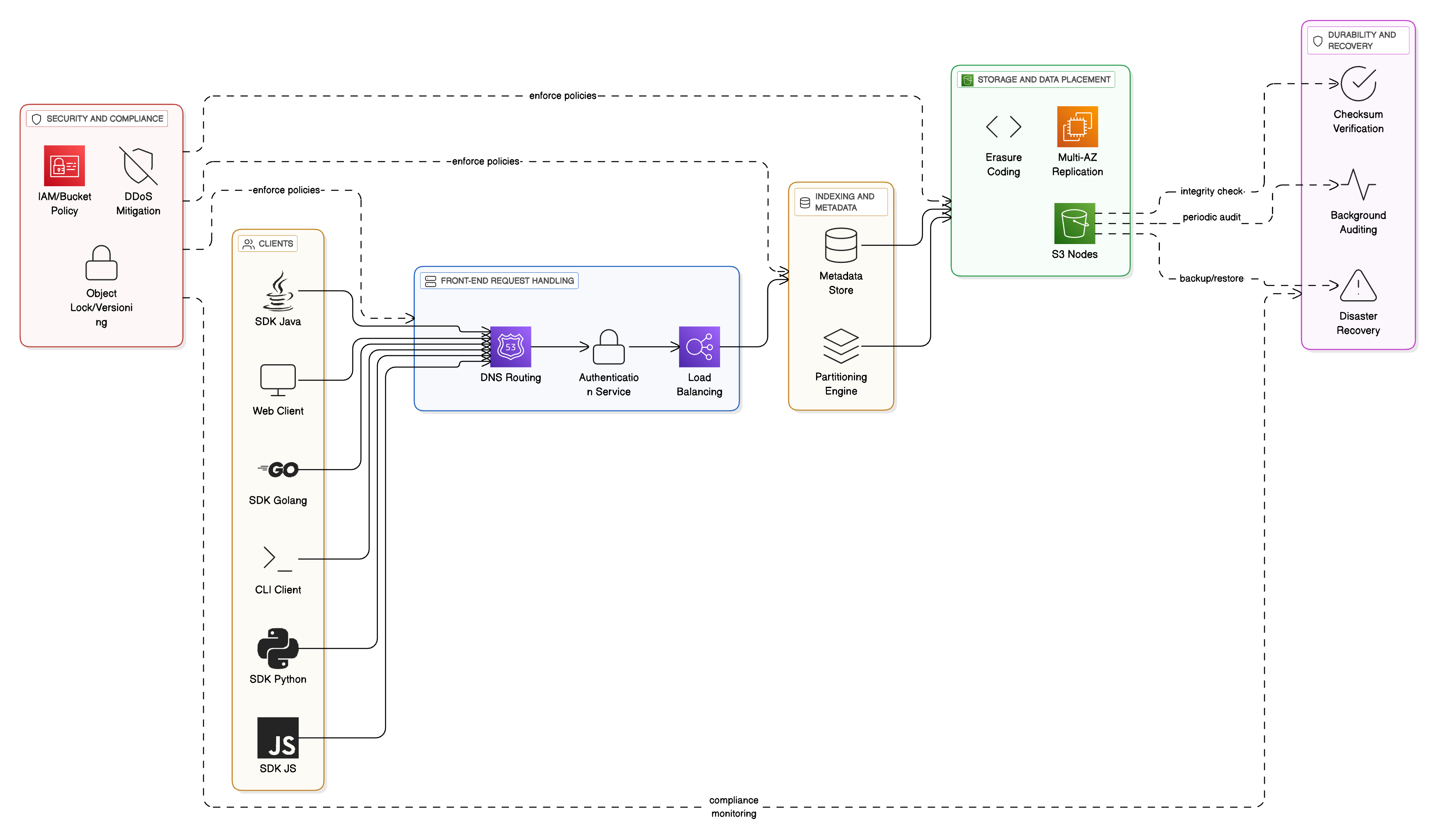
1 - Front-End Request Handling Services
Every interaction with S3 starts with a client request—whether it’s uploading a file, downloading data, or listing objects in a bucket.
These requests come through various clients, such as:
Web browsers (via the S3 console)
AWS CLI
SDKs for languages like Python, JavaScript, Java, or Go
The front-end layer has three main responsibilities:
DNS routing directs the request to the right S3 endpoint.
Authentication services validate user credentials using AWS IAM or temporary tokens.
Load balancers distribute incoming traffic evenly to ensure smooth performance.
This layer doesn’t store data itself. Instead, it ensures that requests are authenticated, validated, and routed to the correct backend services.
2 - Indexing and Metadata Services
Once the request reaches S3, the next step is metadata lookup.
Every object stored in S3 is assigned:
A unique identifier (based on the bucket name and object key)
Metadata like creation date, size, owner, access control lists (ACLs), and versioning details
The metadata services act like a giant distributed index.
They consist of:
A global metadata store that tracks information about every object.
A partitioning engine that distributes metadata across different partitions to avoid bottlenecks.
This ensures that S3 can find your object’s location in milliseconds—even when managing trillions of them.
3 - Storage and Data Placement Services
After metadata lookup, the request moves to the storage layer, where the actual object data lives.
Here’s what happens:
Data is stored across multiple S3 nodes (storage servers).
S3 uses erasure coding, a method that breaks data into chunks, encodes them with redundancy, and spreads them across multiple locations. This provides fault tolerance without duplicating entire objects.
Data is replicated across multiple Availability Zones (AZs) within a region. Even if an entire data center goes down, your data remains safe and accessible.
This multi-AZ replication is a big reason why S3 achieves such high durability.
4 - Durability and Recovery Services
Storing data is only half the job—ensuring it remains intact over time is equally important.
The durability and recovery services handle this through:
Checksums: When you upload data, S3 calculates a checksum and stores it. Periodically, background processes re-verify these checksums to detect any bit rot or corruption.
Auditing: Background jobs continuously scan storage nodes to detect anomalies and repair issues proactively.
Disaster recovery: S3 can rebuild lost data fragments using erasure coding. Even if a disk or node fails, the system automatically regenerates missing parts without impacting availability.
These invisible background processes are why users rarely, if ever, lose data stored in S3.
5 - Security and Compliance Services
Finally, Amazon S3 includes a strong security layer to protect against unauthorized access and meet compliance requirements.
Some of the key features include:
IAM policies and bucket policies to control access at both user and resource levels.
DDoS mitigation to handle large volumes of malicious traffic.
Object Lock and versioning to prevent accidental or malicious deletions.
Server-side encryption options for data protection at rest.
S3 also complies with major standards like PCI-DSS, HIPAA, and FedRAMP, making it suitable for sensitive enterprise workloads.
Why This Architecture Matters
By splitting responsibilities across specialized services, Amazon S3 achieves incredible scale, durability, and security.
The front-end handles massive request loads efficiently.
The metadata layer keeps track of billions of objects instantly.
The storage layer ensures resilience and redundancy.
The durability and security layers protect data for the long term.
This modular microservices approach allows AWS to update and scale each component independently, which is why S3 has grown continuously since its launch in 2006.
So, have you used S3 in your projects?
Shoutout
Here are a few interesting articles I read last week:
How Uber Upgraded 2M Spark Jobs (Saved $MMs/Year) by Alexandre Zajac
Most Engineers Want Both Consistency and Scalability by Raul Junco
That’s it for today! ☀️
Enjoyed this issue of the newsletter?
Share with your friends and colleagues.
nundfdffu
beri smart totful