
Essential System Design Performance Metrics
Metrics that matter...

When we talk about designing robust, scalable software systems, the conversation often revolves around architecture patterns, tools, and technologies.
But at some point, we must ask: Is the system actually performing well?
This is where performance metrics come in.
Just like you’d monitor your health using blood pressure or heart rate, developers and architects use specific metrics to evaluate and improve their system designs. These metrics give a quantifiable way to measure performance, reliability, and scalability.
Let’s break down some essential system design performance metrics you should be familiar with.
1 - Availability
Availability refers to the percentage of time your system is operational and accessible. It answers the question: “Can users access the service when they need it?”
High availability is critical, especially for applications where downtime results in lost revenue, damaged reputation, or safety concerns. For example, think of an online payment gateway going down during peak shopping hours—that's a disaster.
Availability is usually measured in “nines”:
99% availability = ~3.65 days of downtime per year
99.9% = ~8.76 hours/year
99.99% = ~52 minutes/year
99.999% (five nines) = ~5.26 minutes/year
Achieving higher availability requires:
Load balancing across instances
Health checks and failover mechanisms
Redundancy and isolation in infrastructure
Disaster recovery strategies
Remember: availability doesn’t mean your system is error-free—it means users can access it even when things occasionally fail behind the scenes.
2 - Throughput
Throughput measures the amount of work your system can handle in a given time. It’s often measured in:
RPS (Requests per Second)
QPS (Queries per Second)
TPS (Transactions per Second)
Think of throughput as a highway: how many cars (requests) can pass through per minute. A system with high throughput can process many requests without slowing down.
But throughput is not just a raw number—it reflects:
Concurrency: how many users or processes can your system handle at once?
Efficiency: are operations optimized, or is the system wasting time/resources?
To increase throughput:
Optimize database queries and indexes
Use distributed systems and sharding
Implement asynchronous processing
Remove performance bottlenecks (like blocking I/O or unnecessary API calls)
High throughput is essential for scalable systems, especially those with real-time workloads like streaming apps or financial services.
3 - Latency
Latency is the time delay between a request and the system’s response. In simple terms: How long does the system take to respond to a user or service?
Latency can be broken down into:
Propagation Delay: Time taken for the request to travel over the network
Processing Delay: Time taken by servers to compute and generate a response
Round-Trip Time (RTT): Total time for a request to go to the server and come back
Even small delays can degrade user experience. For example:
A delay of >2 seconds can cause users to abandon an e-commerce cart
In real-time gaming or financial trading apps, milliseconds matter
To reduce latency:
Use CDNs to serve content closer to the user
Implement caching to avoid repeated computation or DB hits
Use load balancing to route requests to the nearest or fastest server
Keep APIs and services lean—reduce unnecessary processing steps
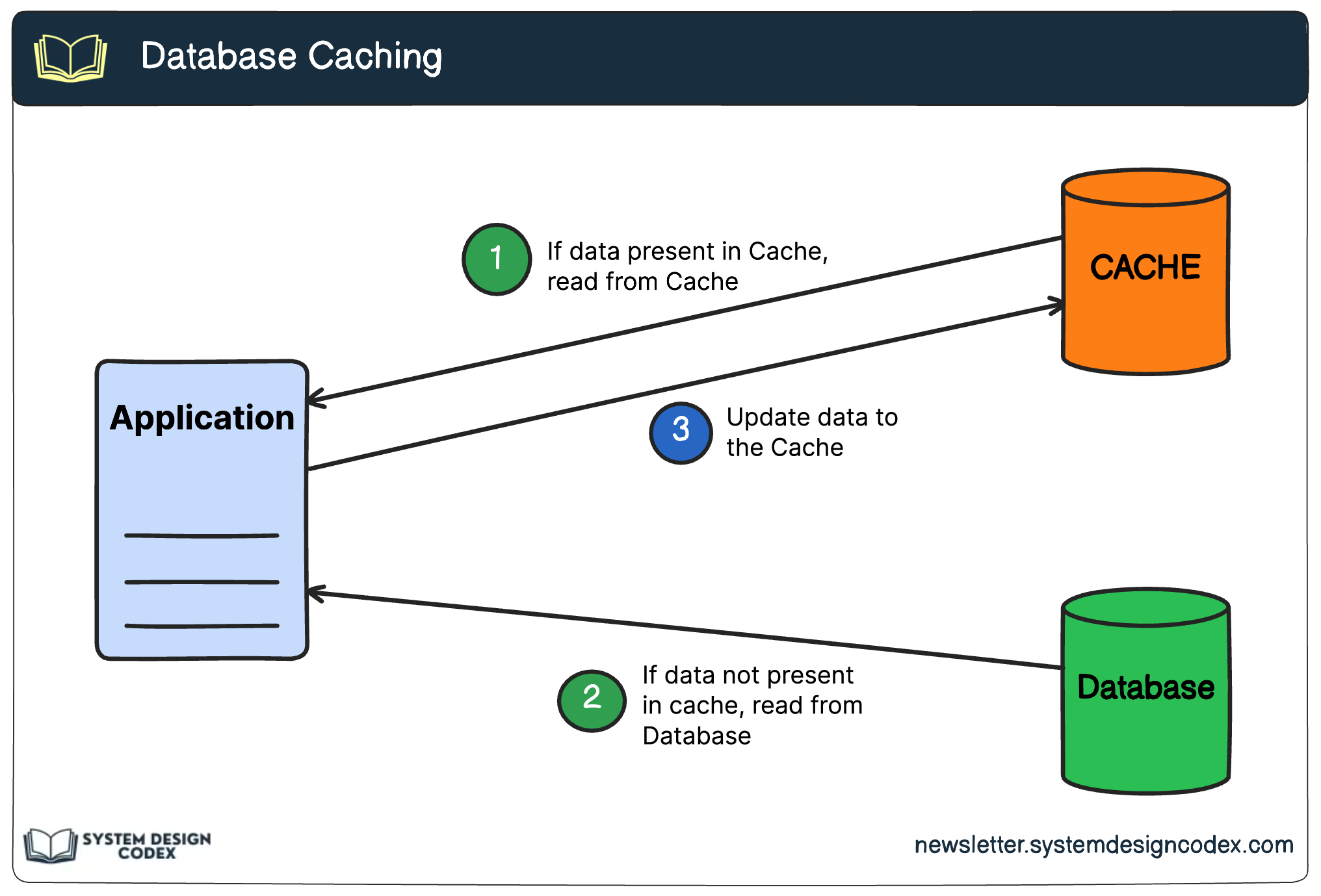
Latency optimization is not just about speed—it’s about delivering seamless user experiences.
4 - Scalability
Scalability refers to how well your system can handle an increase in load, users, or data volume.
But it’s not just about “getting bigger.” It’s about growing without compromising performance, reliability, or cost-efficiency.
There are two primary ways to scale:
Vertical Scaling: Add more power (CPU, RAM) to your existing servers. This is simple but has physical and cost limits.
Horizontal Scaling: Add more servers to distribute the load. This is more complex but highly effective for large-scale systems.
Scalable systems often embrace:
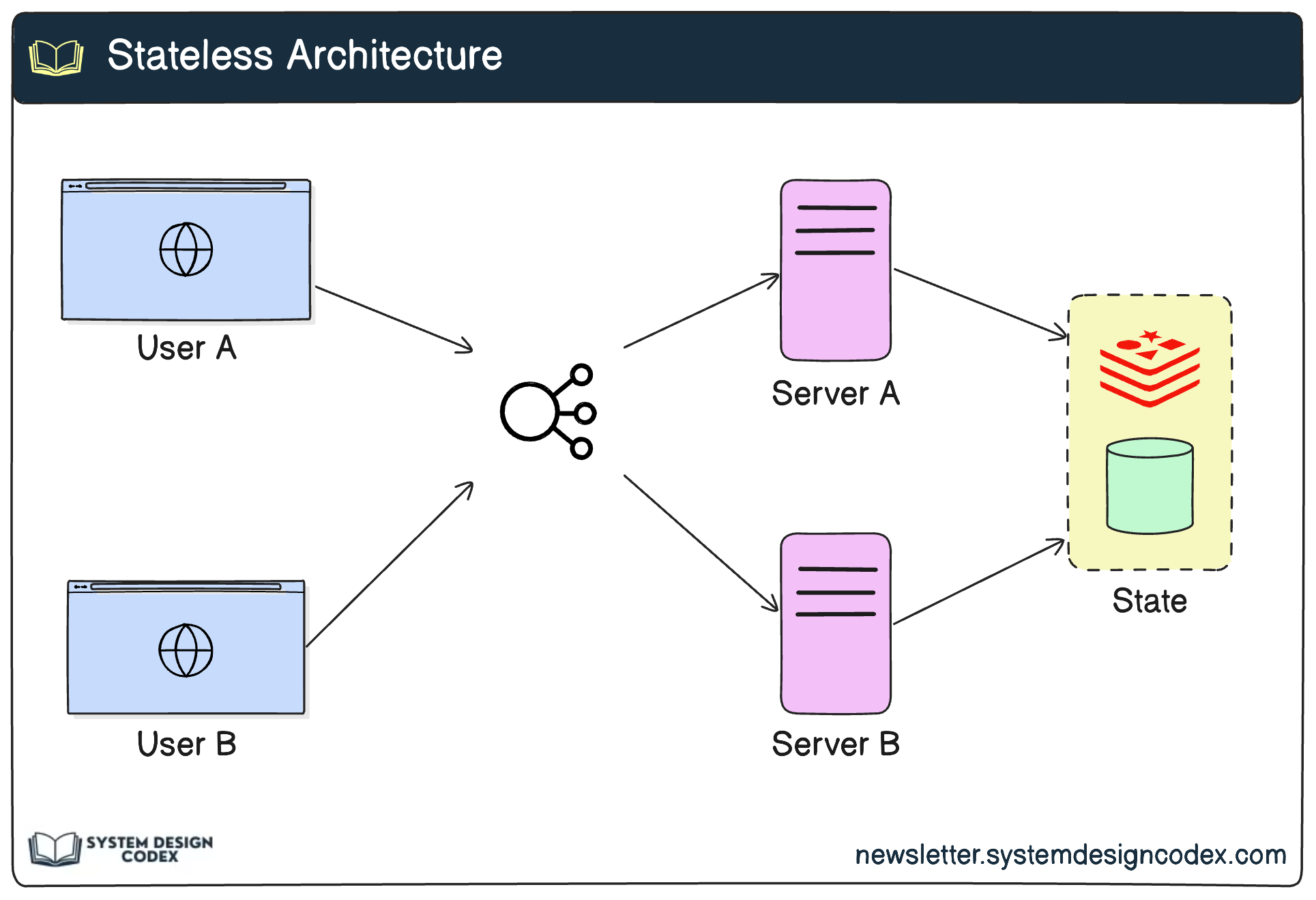
Stateless design for easy horizontal scaling
Distributed storage and databases
Event-driven architecture for async workloads
Container orchestration using tools like Kubernetes
Measure scalability by observing how your system behaves under increasing load. Can it still maintain response time and throughput? If not, it’s time to refactor.
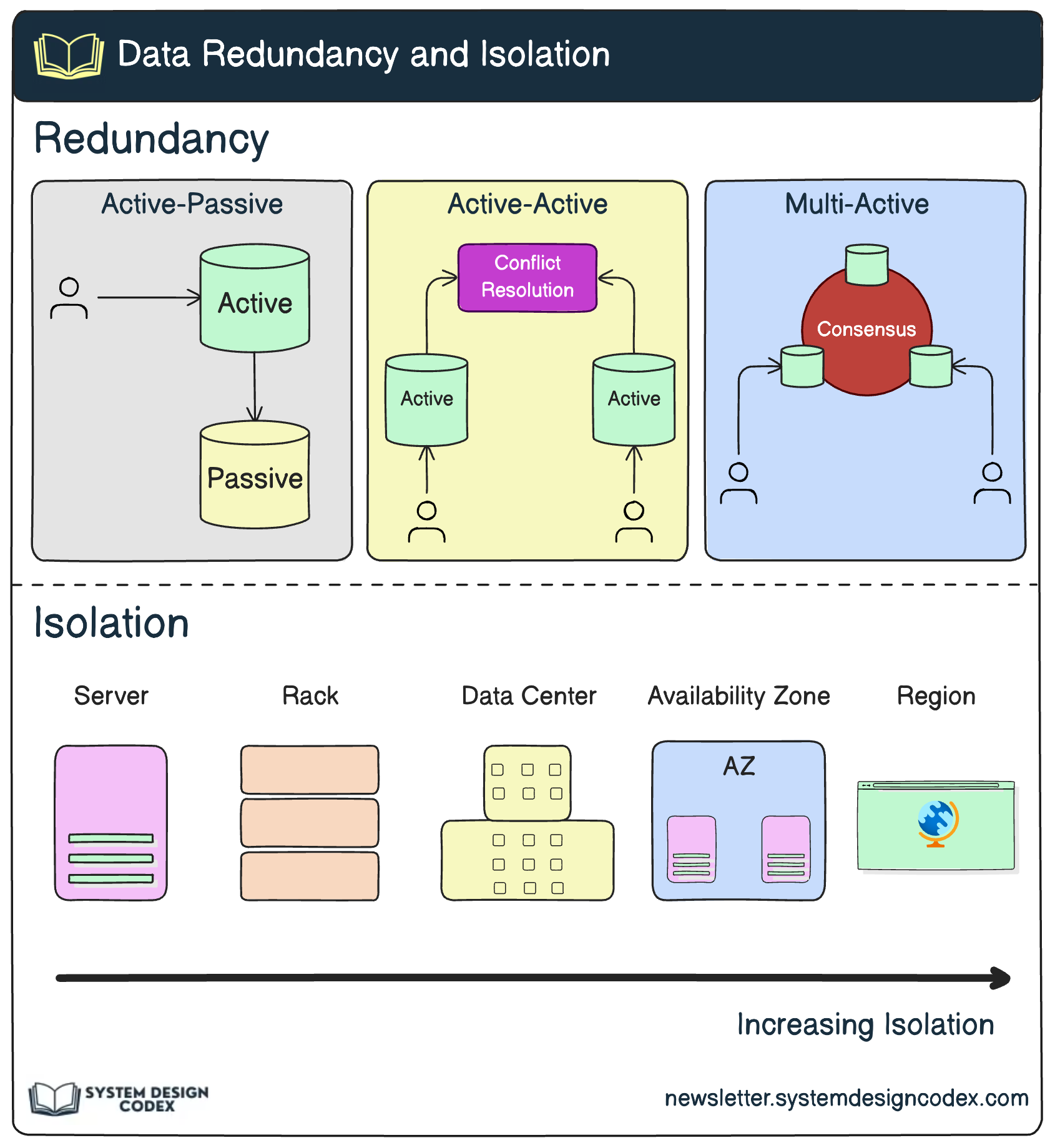
5 - Redundancy
Redundancy is the practice of duplicating critical components to avoid a single point of failure.
It’s not about performance improvement per se—but it’s critical for resilience and fault tolerance.
Two common redundancy strategies:
Active-Passive: A backup system is on standby, ready to take over if the main one fails.
Active-Active: Multiple instances operate in parallel, providing both load distribution and high availability.
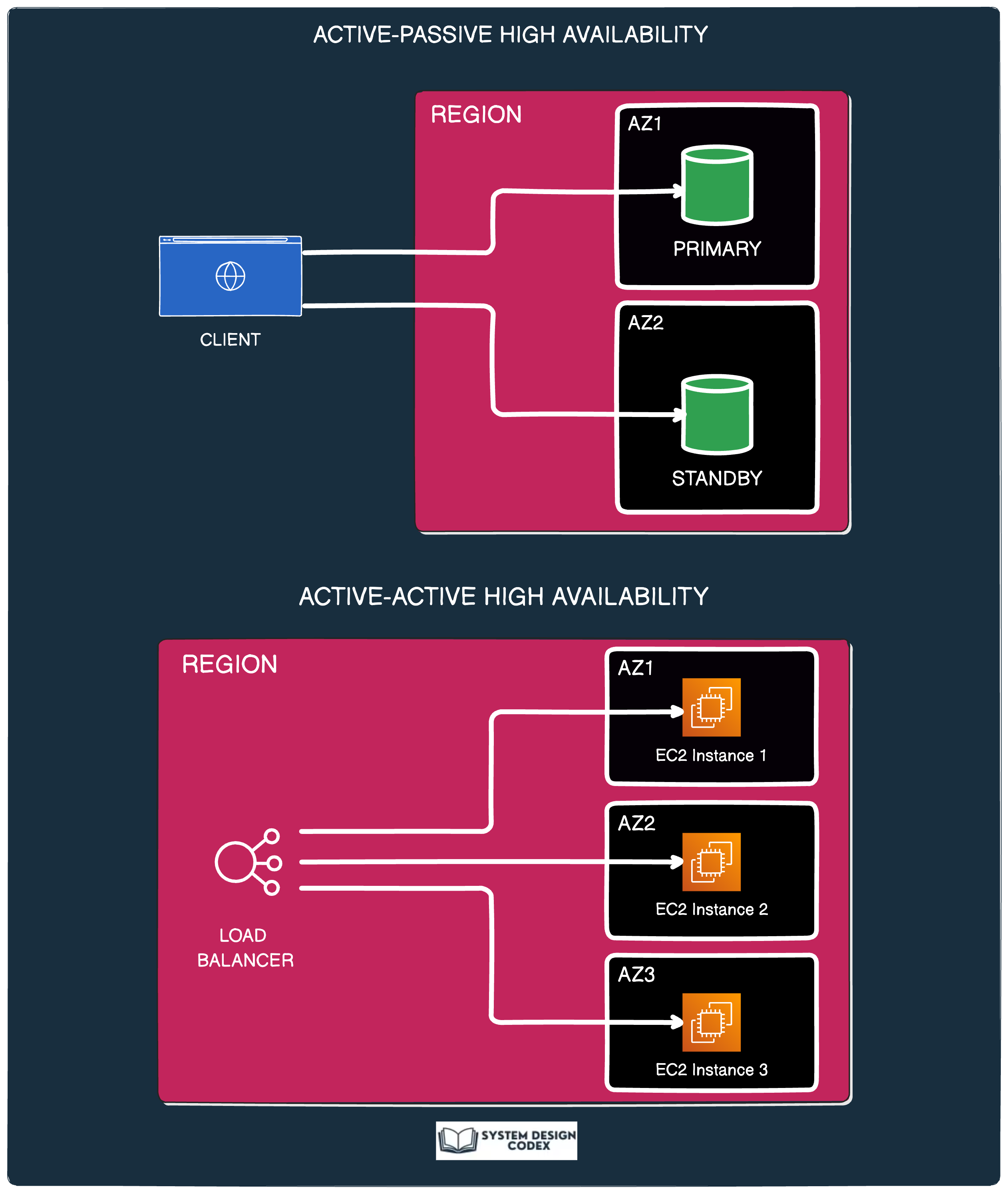
You’ll find redundancy in:
Database replicas
Multi-zone or multi-region cloud deployments
Backup message queues
RAID disk configurations
Redundancy adds reliability, but also complexity and cost. The trick is to balance the need for uptime with operational overhead.
👉 So - which other metrics do you typically track?
Shoutout
Here are some interesting articles that I read this week:
That’s it for today!
Enjoyed this issue of the newsletter?
Share with your friends and colleagues.
https://open.substack.com/pub/hamtechautomation/p/a-battle-tested-sredevops-engineers?utm_source=app-post-stats-page&r=64j4y5&utm_medium=ios
Very useful!!