
Don't Forget These Non-Functional Requirements
NFRs are also important to effective systems...

When designing and building software systems, developers often focus on what the system does—this is the functional part. But just as critical is how the system behaves under real-world conditions.
That’s where non-functional requirements (NFRs) come into play.
Non-functional requirements define the quality attributes of a system: its reliability, responsiveness, scalability, flexibility, and more. These aspects don’t deal with features directly but ensure the system delivers a robust experience.
Here are 8 essential non-functional requirements that every developer should know—along with how to implement them in practice.
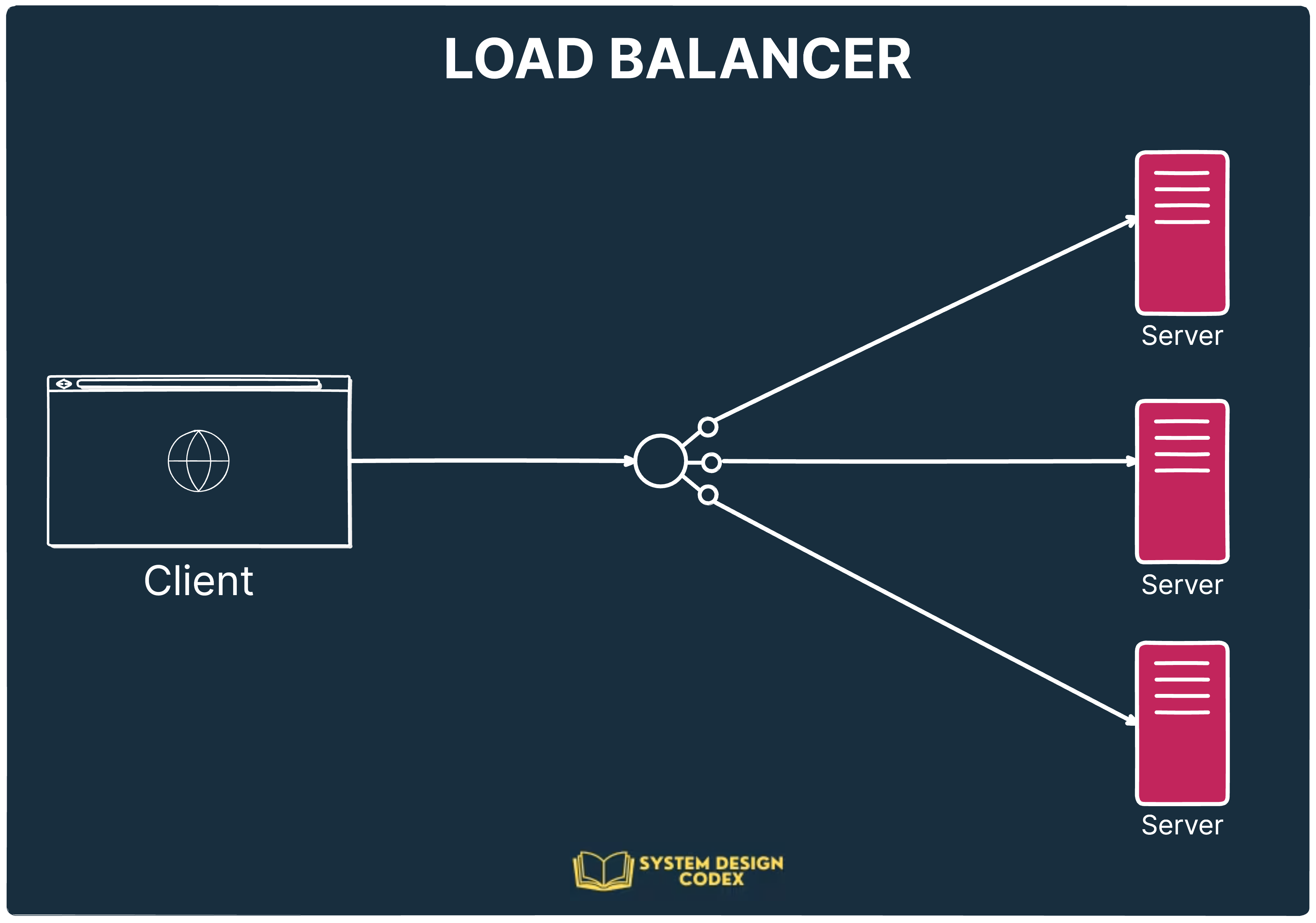
1 - Availability
What it means:
Availability ensures that your system is operational and accessible when users need it.
Why it matters:
If your system goes down during peak usage (e.g., an e-commerce flash sale), you risk losing revenue and user trust.
How to implement:
Use Load Balancers (like NGINX, HAProxy, or AWS ELB) to distribute incoming traffic across multiple instances of your application. This ensures that no single failure point can bring the whole system down. Combine this with health checks and failover mechanisms for maximum availability.
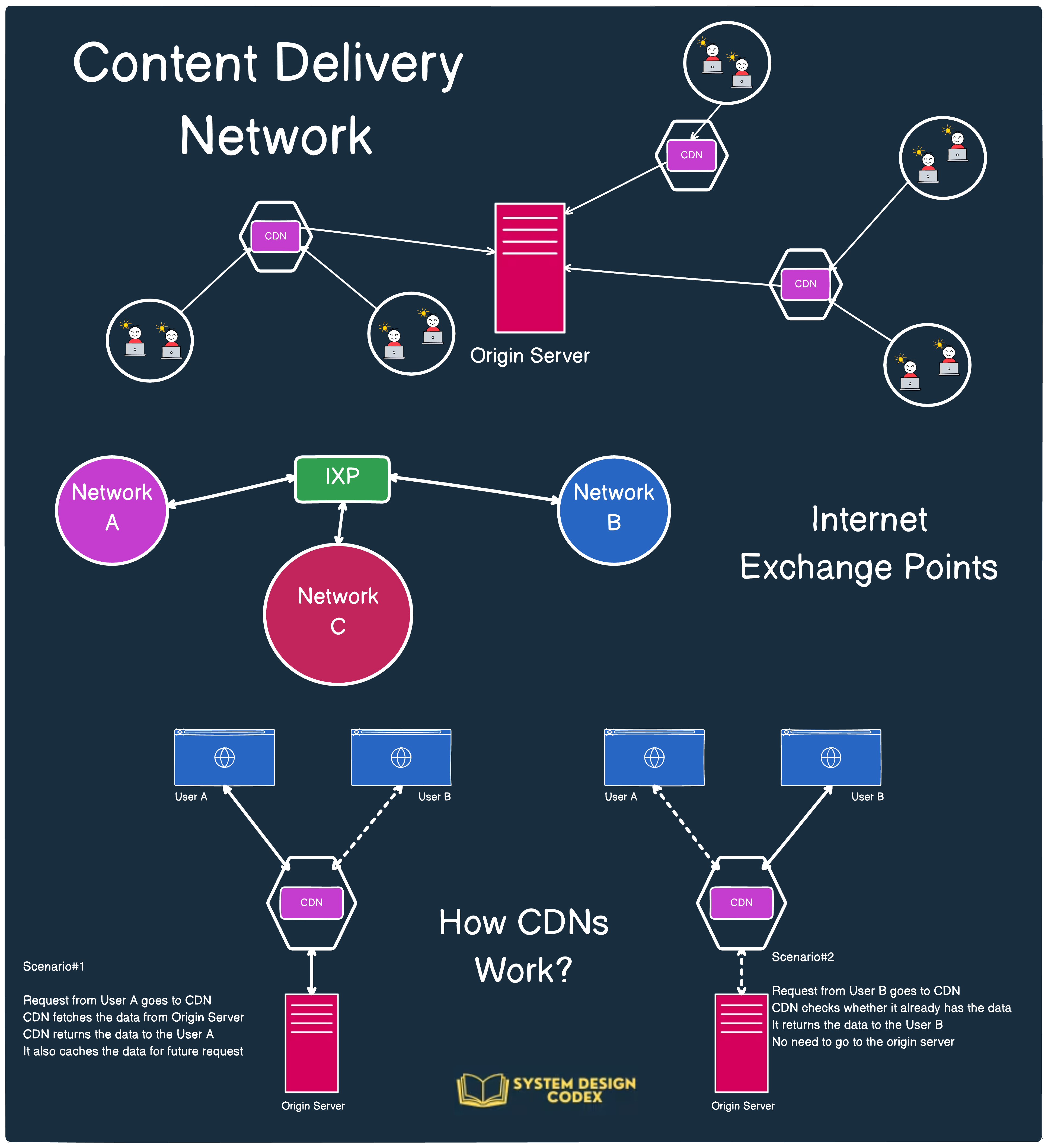
2 - Latency
What it means:
Latency is the time it takes for a user’s request to receive a response. Lower latency equals faster, smoother user experiences.
Why it matters:
Users won’t wait forever. Studies show that even a 100ms delay can impact user engagement and conversions.
How to implement:
Deploy a Content Delivery Network (CDN) like Cloudflare, Akamai, or Amazon CloudFront to cache static content closer to the end user. This reduces travel time for requests and significantly speeds up asset delivery.
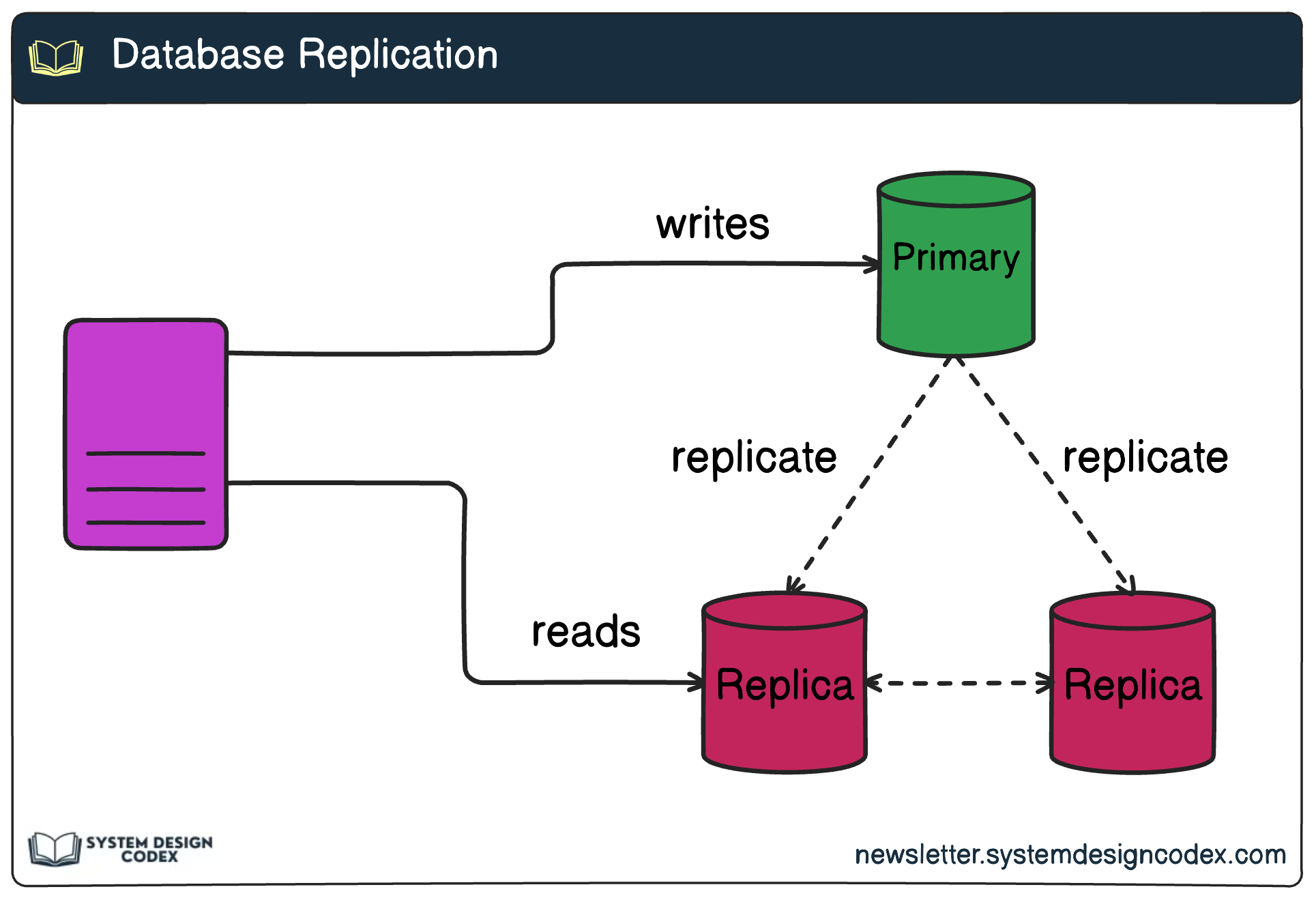
3 - Scalability
What it means:
Scalability is the system’s ability to handle increasing workloads by efficiently adding resources.
Why it matters:
Your app may work great with 1,000 users, but what happens when it hits 1 million?
How to implement:
Use data replication to distribute load across multiple database nodes. Combine this with horizontal scaling for stateless services using container orchestrators like Kubernetes. Design APIs to handle concurrent users gracefully.
4 - Durability
What it means:
Durability ensures that once data is stored, it remains safe—even in the case of power loss, crashes, or system failures.
Why it matters:
If users lose their transaction history, passwords, or saved preferences, your app loses credibility.
How to implement:
Use transaction logs or write-ahead logs (WAL) to persist operations before applying them to the database. Systems like PostgreSQL and MySQL have this built in. In distributed storage, use replicated, fault-tolerant data stores like Amazon S3, Cassandra, or HDFS.
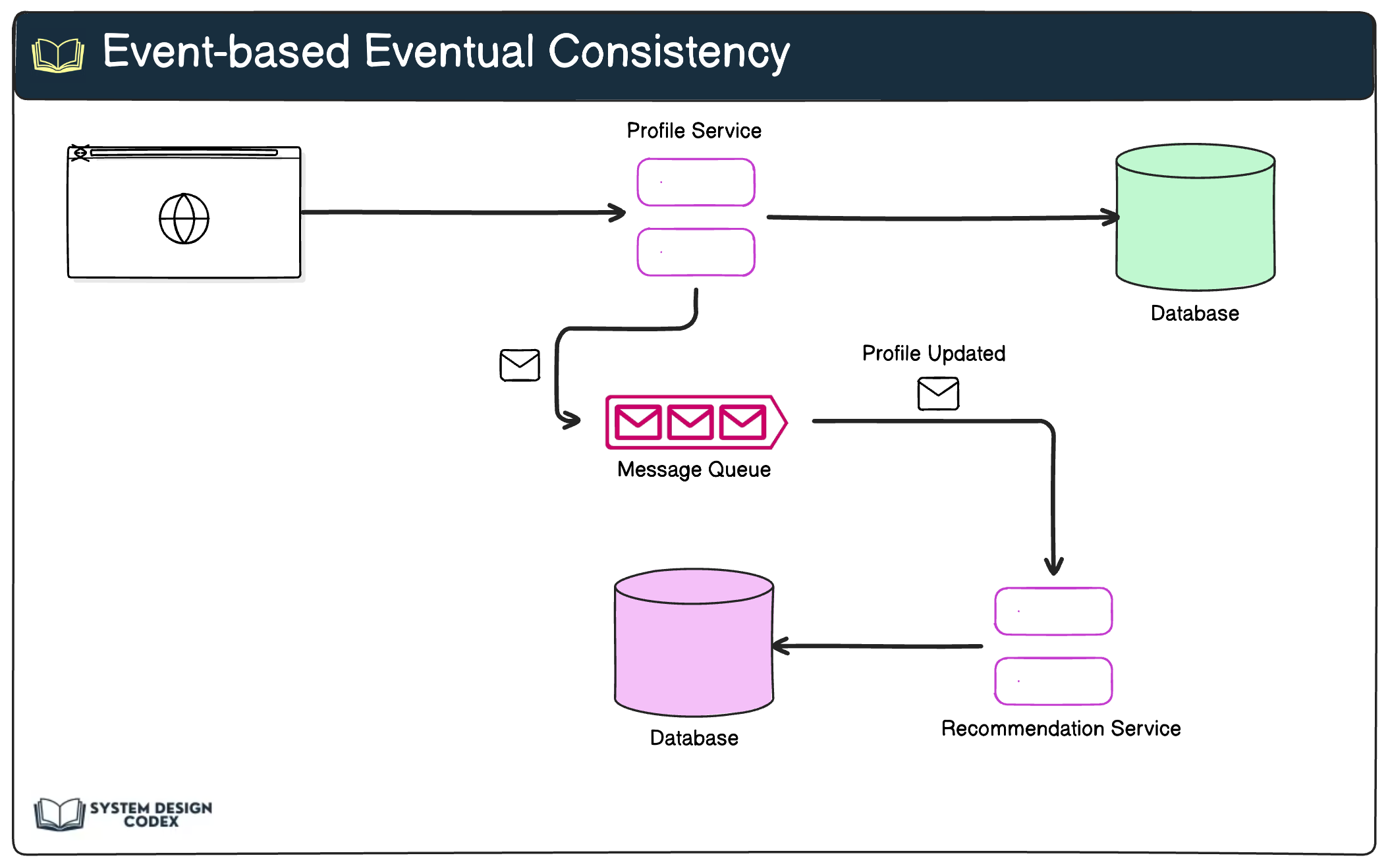
5 - Consistency
What it means:
Consistency means that users see a reliable and accurate state of data—even when multiple servers or databases are involved.
Why it matters:
If user A updates their profile but user B sees outdated data, that’s a poor experience.
How to implement:
In distributed systems, eventual consistency is often used instead of strict real-time consistency. Systems like DynamoDB and Cassandra ensure that all nodes will eventually reflect the same data. Use conflict resolution strategies and data versioning when needed.
6 - Modularity
What it means:
Modularity means breaking down the system into independent, manageable components.
Why it matters:
Tightly coupled systems are hard to scale, test, or modify. Modularity gives you agility.
How to implement:
Follow principles of loose coupling (components interact via interfaces or contracts) and high cohesion (each module has a single purpose). Use design patterns like microservices, layered architecture, or hexagonal architecture to promote modularity.
7 - Configurability
What it means:
Configurability allows you to modify system behavior without deploying new code.
Why it matters:
Want to enable a new feature or change system behavior across environments (dev, test, prod)? Doing this without code changes is a big win.
How to implement:
Use Configuration-as-Code with tools like Terraform, Ansible, or Helm to manage infrastructure settings in version control. Also, expose runtime configuration via environment variables or centralized config servers (e.g., Spring Cloud Config).
8 - Resiliency
What it means:
Resiliency is the system’s ability to recover gracefully from faults or disruptions.
Why it matters:
Failures are inevitable. What matters is how well your system handles them.
How to implement:
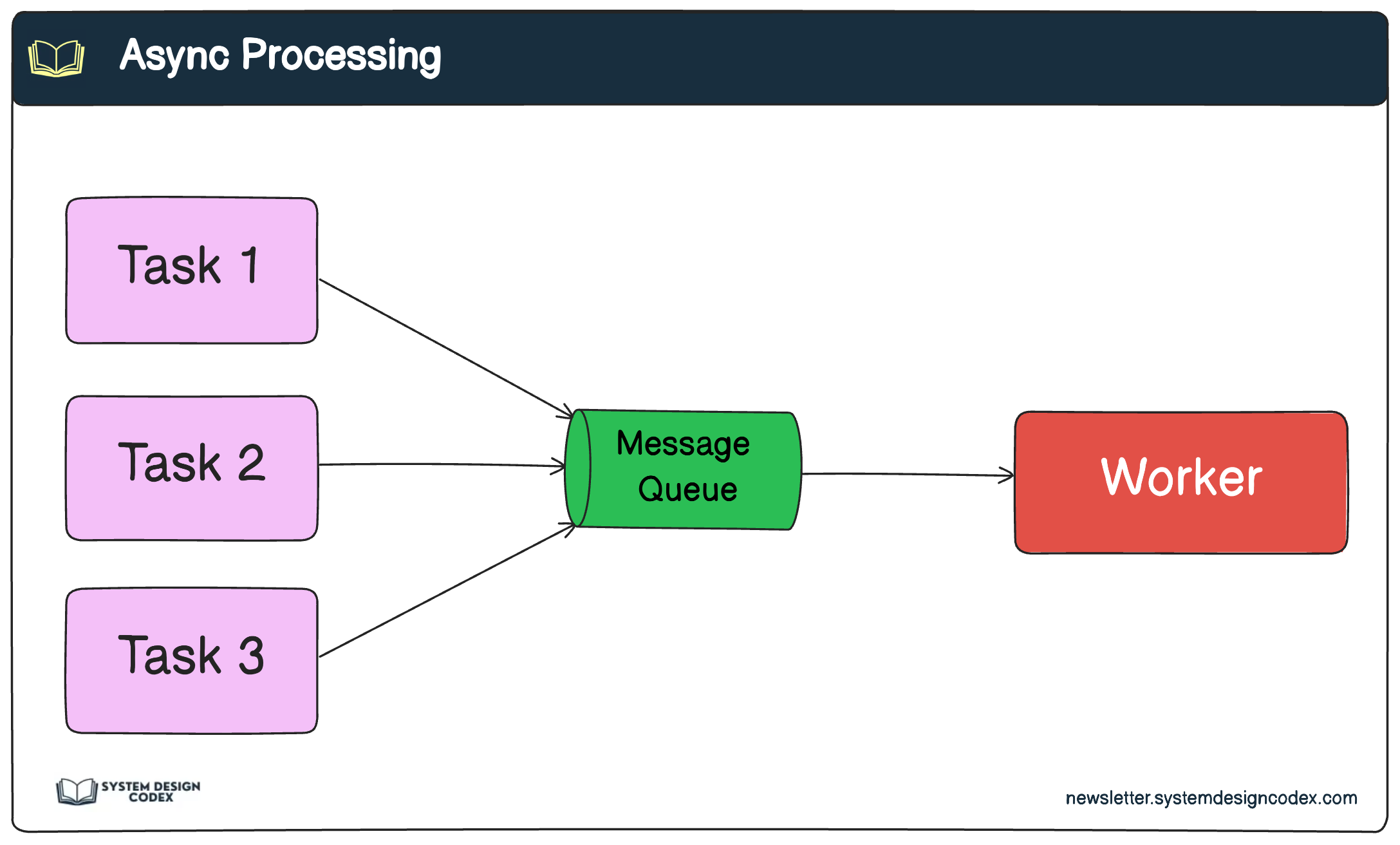
Introduce message queues (like RabbitMQ, Kafka, or AWS SQS) to decouple producers and consumers. This allows parts of your system to fail or restart without losing data. Also use circuit breakers, retry logic, and backoff strategies to handle transient issues.
👉 So - which other NFRs will you add to the list?
Shoutout
Here are some interesting articles that I read this week:
That’s it for today!
Enjoyed this issue of the newsletter?
Share with your friends and colleagues.
Great roundup, Saurabh.
One angle worth adding: observability as a core NFR.
Without solid logging, metrics, and tracing, it’s nearly impossible to meet or even measure performance, reliability, or maintainability goals.
Thanks so much for the shoutout!
I always check the wikipedia page of nonfunctional requirements to make sure I don't miss any requirement that is relevant to my design: https://en.wikipedia.org/wiki/Non-functional_requirement
Thanks for the mention, Saurabh!