
SDC#17 - Database Caching Strategies
Are microservices silver bullets? And More...

Hello, this is Saurabh…👋
Welcome to the 176 new subscribers who have joined us since last week.
If you aren’t subscribed yet, join 1900+ curious Software Engineers looking to expand their system design knowledge by subscribing to this newsletter.
In this edition, I cover the following topics:
🖥 System Design Concept → Database Caching Strategies
🍔 Food For Thought → Are Microservices Silver Bullets?
So, let’s dive in.
🖥 Database Caching Strategies
Databases are critical to an application’s performance.
In fact, I think they are on top of the most important factors when it comes to performance.
The difference between good performance and poor performance comes down to how well you deal with the typical database challenges such as:
Query processing speed
Cost of scaling
Making data access easy
Balancing these challenges is important to get the most out of your system.
But sometimes, you need quick results.
And that’s where Database Caching can offer you the “olive branch” you were looking for.
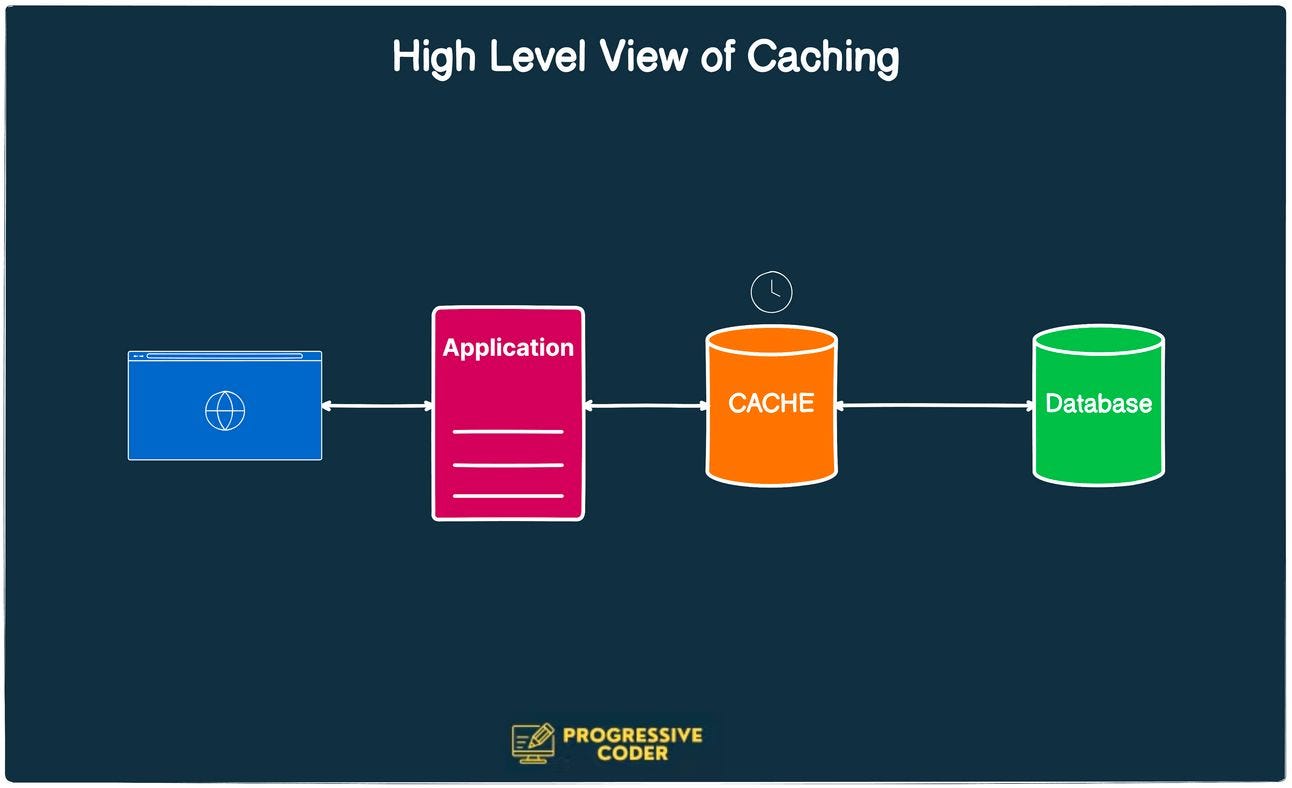
What is Database Caching?
A cache is a collection of items.
You can think of a cache as a stockpile of something that you need to keep handy for quick access in a time of need. For example, a cache of medicines or a stock of food items.
When it comes to software engineering, the meaning isn’t so different.
Think about a bunch of bestseller products on an e-commerce website, a list of country codes, or the most popular posts on your blog.
What do these things have in common?
Yes, they are all frequently needed by the users.
Going to the database every single time a user asks for these frequently accessed items is a serious drag on performance.
Why not store the frequently accessed data in temporary storage that is faster than database access?
This temporary storage location is the cache.
So - how can we define Database Caching?
In essence, Database Caching is a buffering technique that stores frequently-read data in temporary memory.
This temporary memory is optimized for high-speed data storage resulting in faster access to the information as compared to the primary database.
Of course, database caching itself is not a singular technique.
It’s an umbrella term for a bunch of strategies that you can adopt depending on your data.
Database Caching Strategies
If you find database caching useful and want to use it to build your next million-dollar application, it’s important to evaluate the various strategies at your disposal.
Each strategy has a slightly different twist on the relation between the cache and the database.
This twist can have a good deal of impact on how you end up designing your application.
Let’s look at these strategies:
Cache-Aside Strategy
This is by far the most common strategy used in the wild.
Here’s what it looks like:
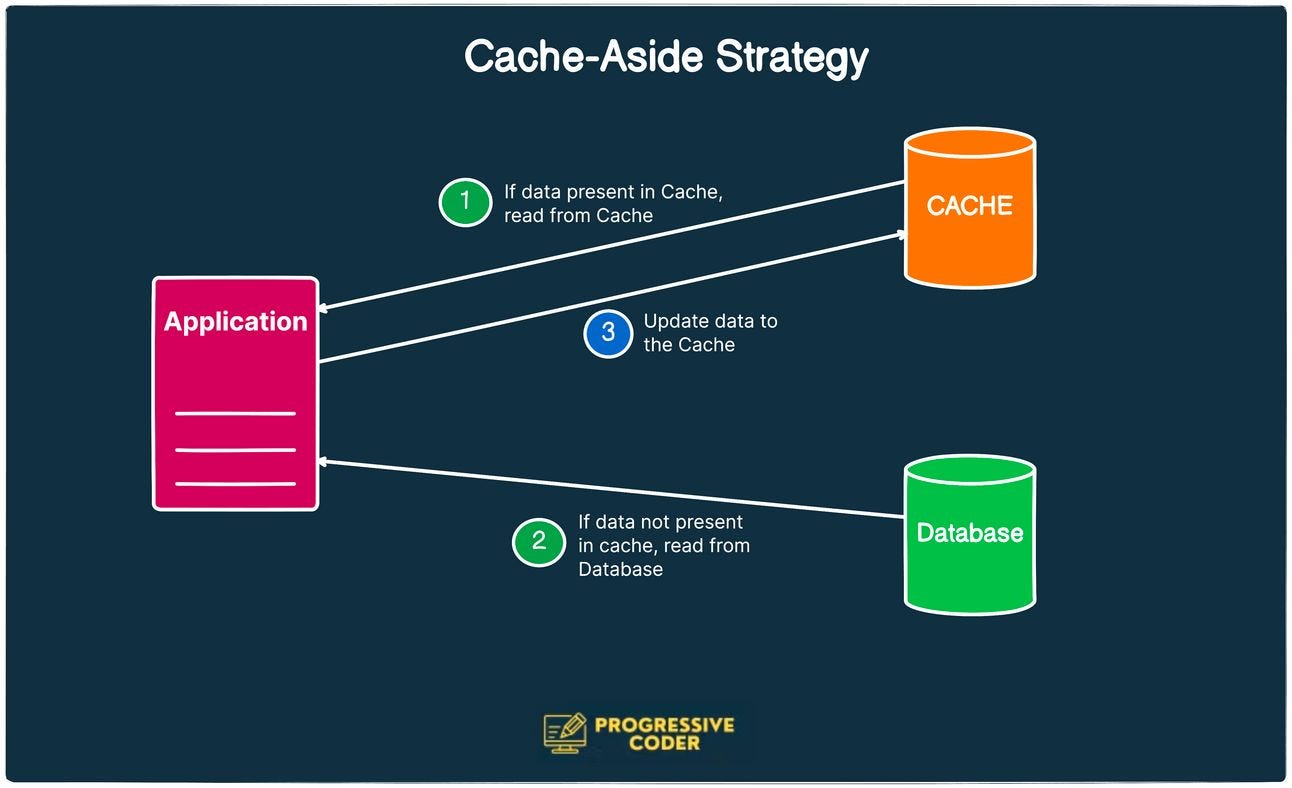
In this strategy, the cache sits next to the database.
When there is a request for data, the application first checks the cache.
If the cache has the data (i.e. a cache hit), the application will return from the cache.
If the cache doesn’t have the data (a cache miss), the application queries the database and returns the data to the requester.
The application also stores the missing data in the cache for any future requests.
This strategy is great for read-heavy workloads.
Also, since the cache is separate from the database, a cache failure cannot cripple the system. The application can always go directly to the database.
That’s wonderful for resiliency.
However, the main drawback of cache-aside is the potential inconsistency between the cache and the database. Any data being written or updated goes to the database and therefore, the cache may have a period of inconsistency with the primary database.
But it’s something that we can get around.
Read-Through Strategy
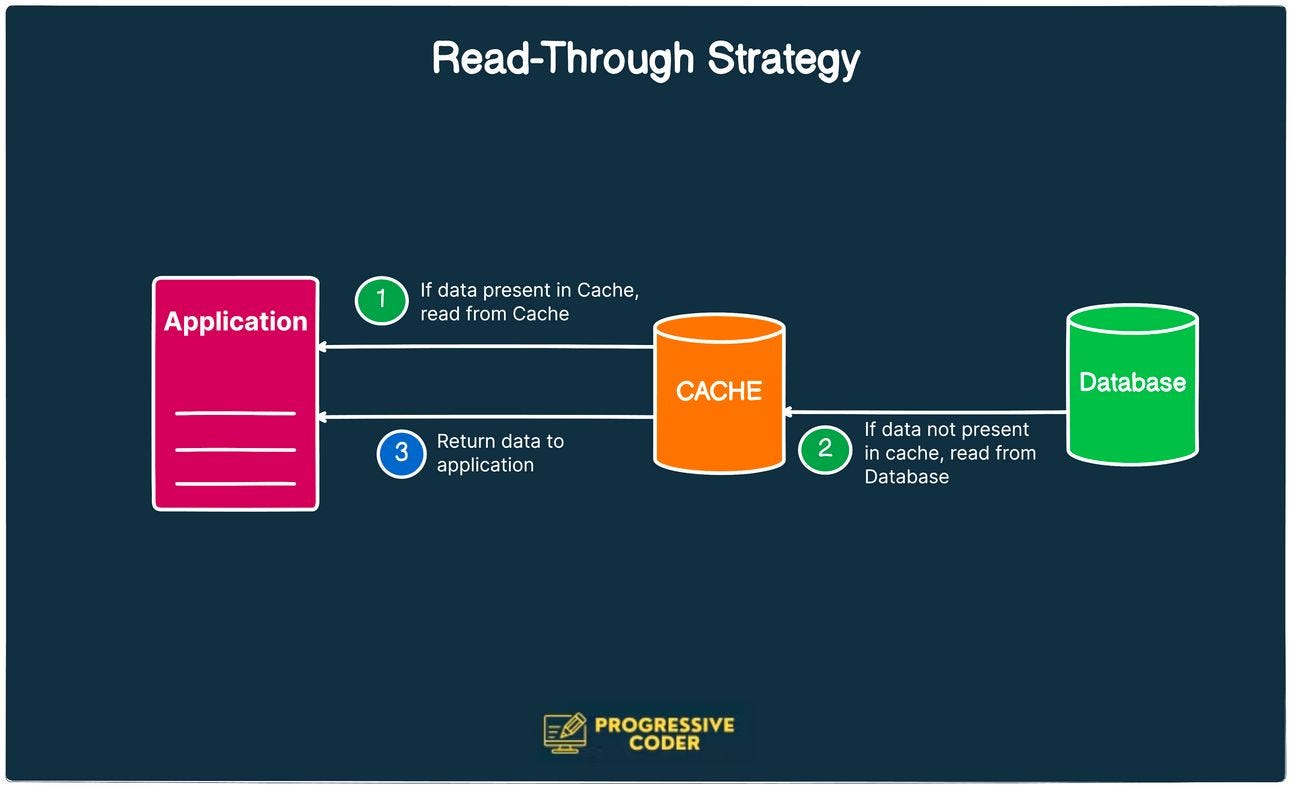
In the read-through strategy, the cache sits between the application and the database.
See the below diagram:
Here’s what happens in read-through:
The application will always reach out to the cache for any read request.
If there’s a cache hit, the data is immediately returned from the cache and that’s the end of the flow.
But in case of a cache miss, the cache will get the missing data from the database and return it to the application.
In case you’re wondering, any write requests still go directly to the database.
So, how is read-through any different from cache-aside?
In cache-aside, the application is responsible for fetching the data and populating the cache. In read-through, all of this is done by a library or a cache provider.
The disadvantage of read-through is also the same as cache-aside:
potential data inconsistency between the cache and the database
the need to go to the database every time a brand-new read request comes through.
The second problem is often mitigated by “warming” the cache by issuing likely-to-happen queries manually. You can think of it as a form of pre-caching.
Write-Through Strategy
The write-through strategy tries to get around the problem with read-through.
Instead of writing data to the database, the application first writes to the cache and the cache immediately writes to the database.
The word “immediately” is important over here.
Check the below illustration:
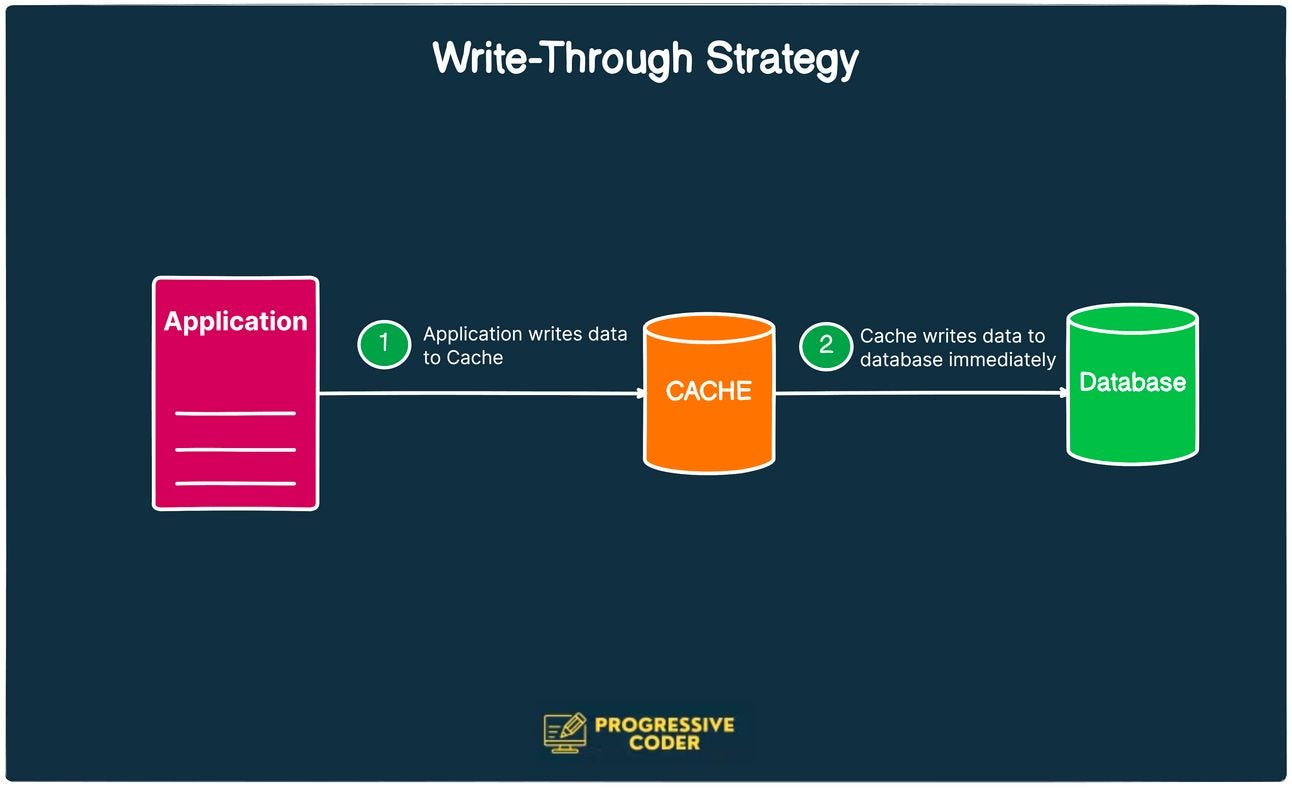
The advantage of write-through is that the cache is ensured to have any written data. New read requests won’t experience a delay while the cache requests the data from the main database.
What’s the downside?
Extra write latency because the data must go to the cache and then to the database. While the impact should be negligible, there are still two writes happening one after the other.
You can also combine write-through with read-through to get the good parts of the read-through strategy without the whole data consistency issue.
Write-Back Strategy
Write-back strategy is essentially a variation of the write-through strategy.
There’s just one key difference.
In the write-back strategy, the application writes directly to the cache (just like write-through). However, the cache does not immediately write to the database but after a delay.
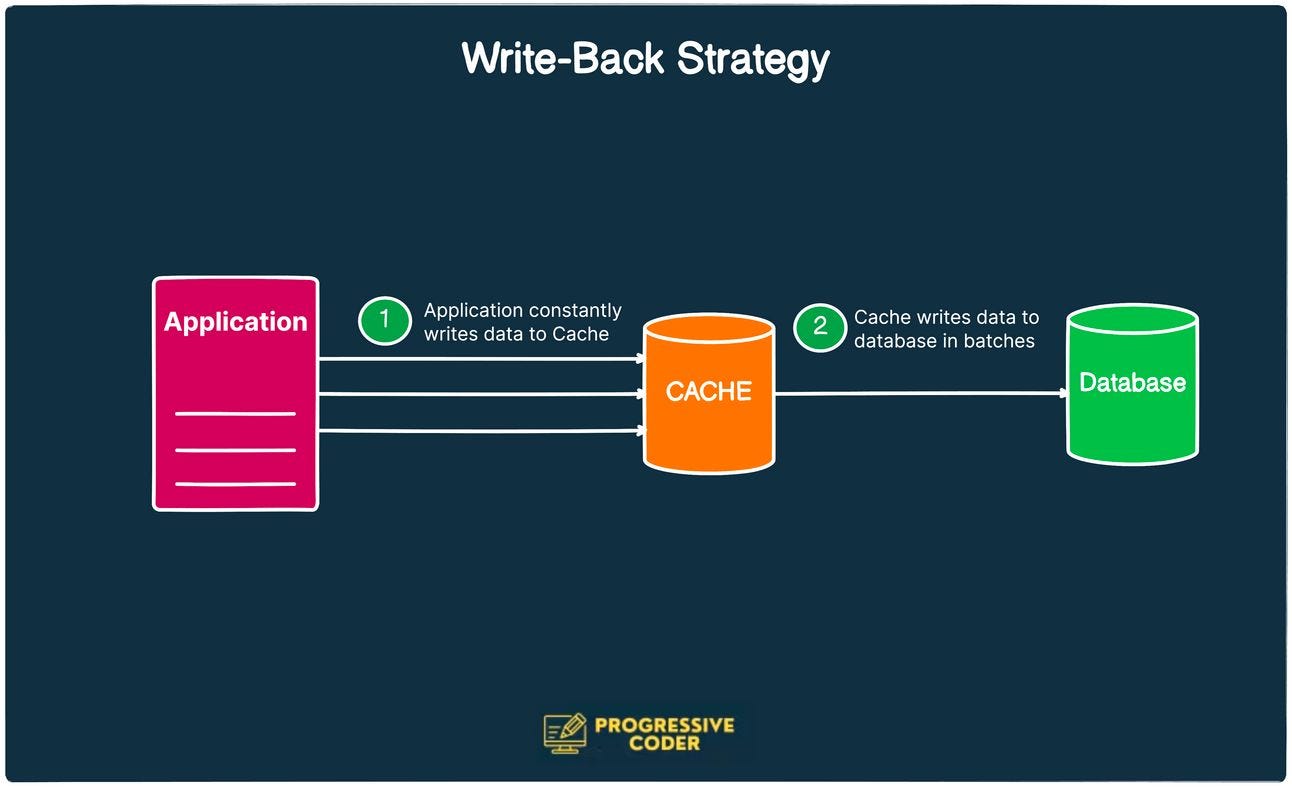
The advantage of this is that the strain on the cache is reduced in case you have a write-heavy workload. Requests to the database are batched and the overall write performance is improved.
The downside is that in case of a cache failure, there are chances of possible data loss.
Write-Around Strategy
In the write-around strategy, data is always written to the database and the data that is read goes to the cache.
In case of a cache miss, the application will read from the database and update the cache for the next time.
Here’s what it looks like:
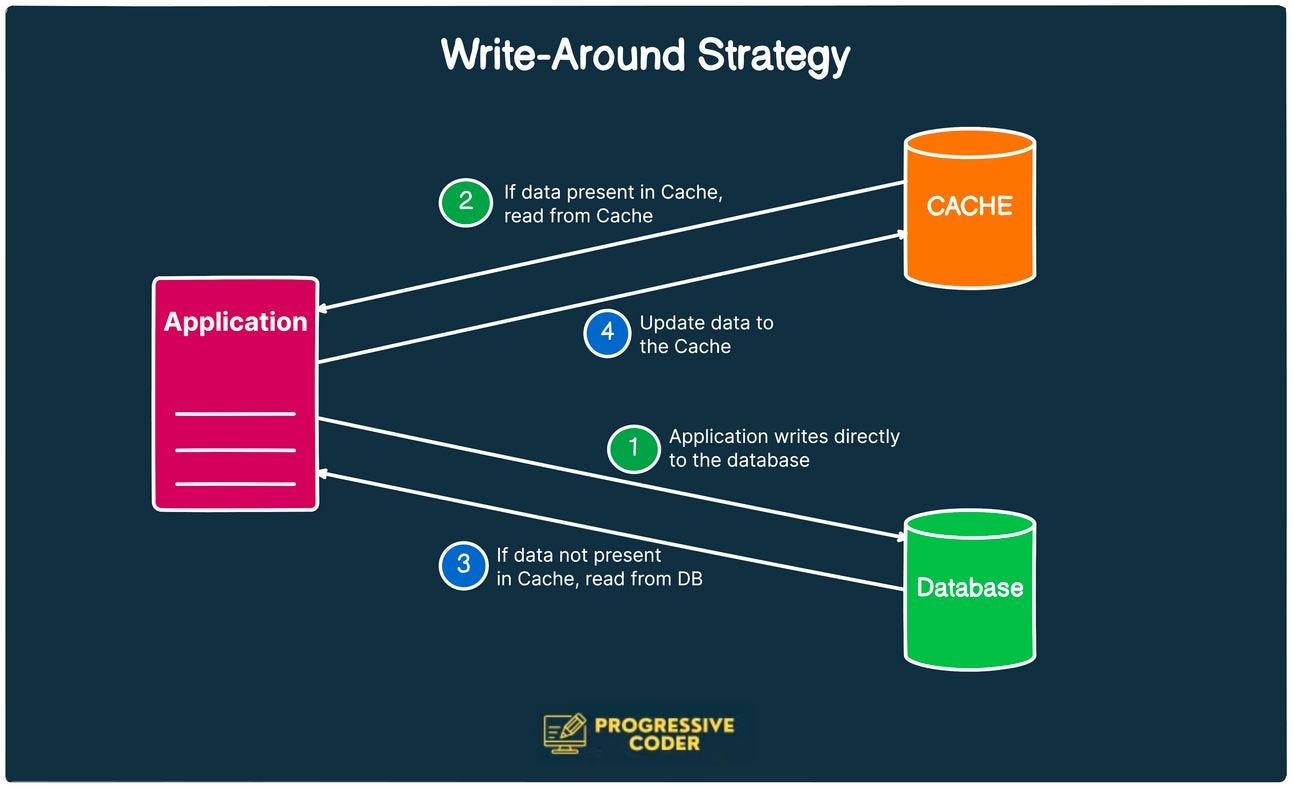
This is basically the same as a cache-aside or read-through strategy with the added context around how the writes are handled.
The best use of this strategy is in cases where data is only written once (or rarely updated) like a blog post or a static website.
👉 At this point, you may be thinking that all of these strategies sound so confusing and it’s hard to remember
And I’m with you on the same boat on this one.
Therefore, I made a handy table that can help you check out all the above strategies at a quick glance.
Here you go:

🍔 Food For Thought
👉 Are Microservices Silver Bullets?
There’s no doubt that microservices are useful.
But there’s also no doubt that microservices have been hyped a lot over the last few years.
I have witnessed an entire department collapsing and good folks getting fired just because there was a blind obsession with microservices.
To make the best use of microservices, the first rule I follow is this:
“Microservices are NOT silver bullets”
I wrote a detailed post on this on X (Twitter) and got some amazing responses.
Do check it out below👇
Here’s the link:
https://x.com/ProgressiveCod2/status/1728011683199844757?s=20
👉 How to Approach Domain-Driven Design (DDD)?
Domain-driven design has so many terms to understand that it can sometimes feel confusing.
But ultimately, there are just two important things that you should focus on:
Focus on the core domain
Maintaining encapsulation
The below post explains this approach beautifully👇
Here’s the link to the post:
https://x.com/Sunshine_Layer/status/1728496171834913057?s=20
That’s it for today! ☀️
Enjoyed this issue of the newsletter?
Share with your friends and colleagues.
See you later with another value-packed edition — Saurabh.