


API Performance Improvement Tips
The API consumers will thank you for using them...

Building APIs is a core part of modern software development. It's fun when things work smoothly. But sooner or later, performance issues creep in—slow responses, timeouts, overwhelmed servers—and suddenly, no one wants to use your APIs anymore.
When your API starts dragging its feet, user experience suffers, systems get strained, and debugging becomes a nightmare.
The good news?
There are tried-and-tested strategies that can help boost your API performance without rewriting everything from scratch. Here are 5 of them:
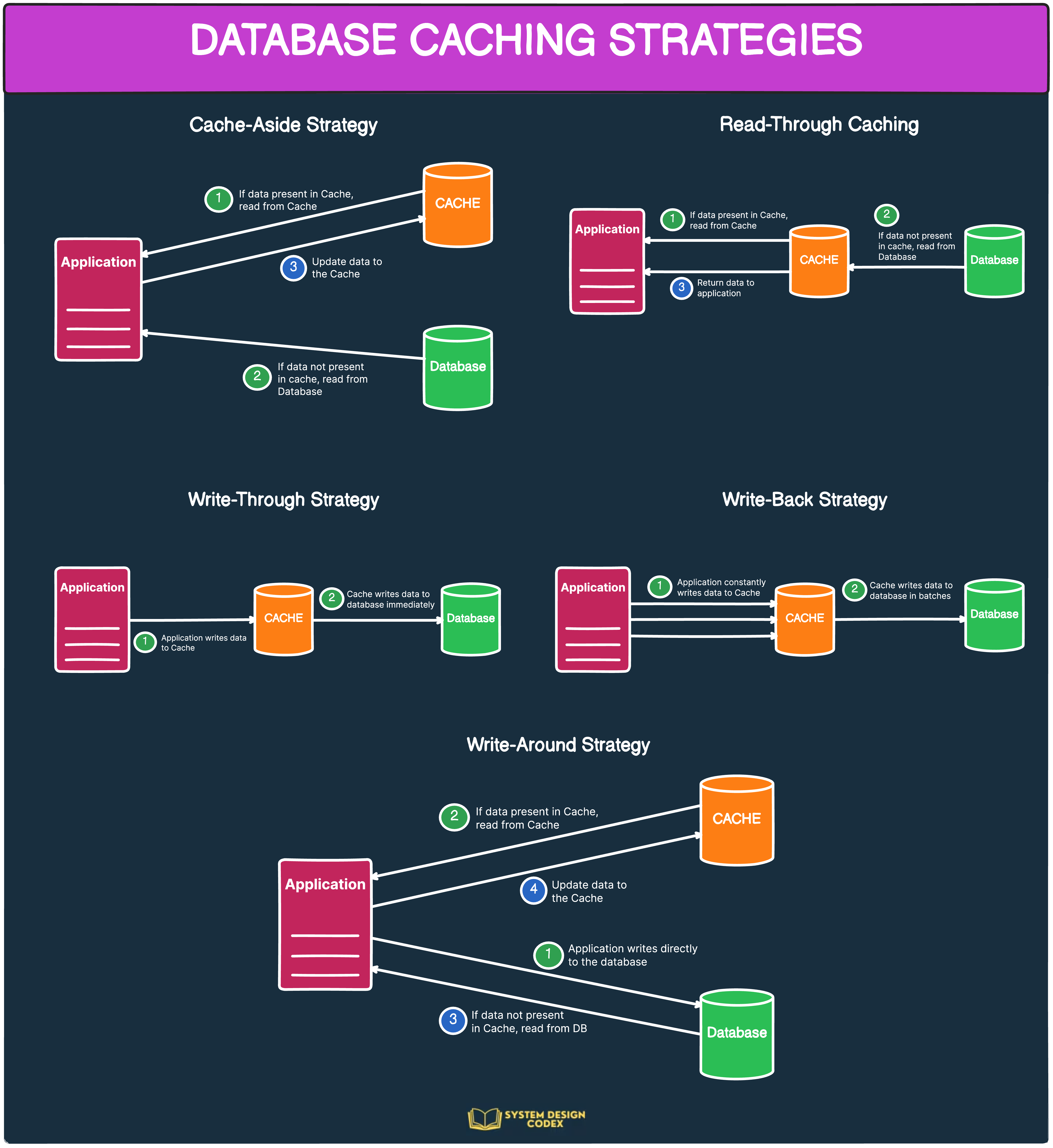
1 - Caching: Speed Things Up with Memory
At its core, caching is about avoiding repeated work.
Instead of hitting the database every time a client asks for the same data, you store the data temporarily in memory (cache). The next time the same data is needed, your API fetches it from the cache—much faster than querying the database.
🔧 How it works:
When a request comes in, check if the data is in the cache.
If yes → return it immediately (cache hit).
If not → fetch from the database, return it, and store it in the cache (cache miss).
💡 Real-world example:
Platforms like Facebook and LinkedIn serve millions of profile views every second using caching. Facebook’s infrastructure uses Memcache to store rendered profile data, while LinkedIn’s read layer relies heavily on TTL-based cache invalidation to ensure data freshness.
⚠️ What to watch for:
Cache invalidation: Knowing when to refresh or delete outdated data is tricky.
Over-caching: Serving stale or incorrect data if not managed carefully.
Use tools like Redis, Memcached, or in-memory caching libraries depending on your architecture.
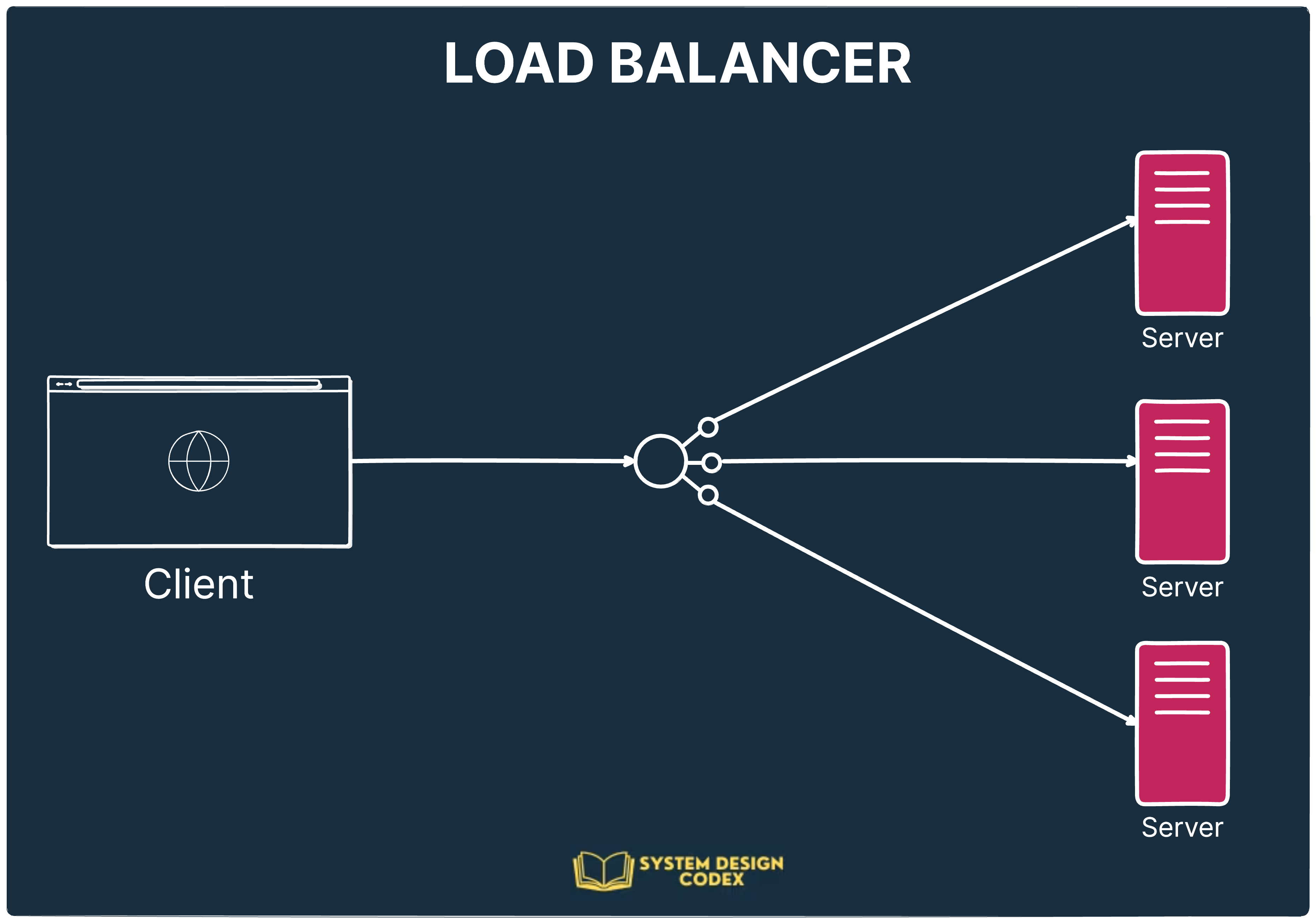
2 - Load Balancing: Scale Out, Not Just Up
When one server can't handle the traffic anymore, the natural step is to scale out—run your API on multiple instances.
But this brings a challenge: how do you distribute incoming requests?
That’s where a Load Balancer comes in.
🔧 How it works:
The load balancer sits between clients and your servers.
It forwards requests to available servers using rules like round-robin, least connections, or geographic proximity.
If one server goes down, it reroutes traffic to healthy instances, keeping your system up and running.
💡 Benefits:
Prevents one server from becoming a bottleneck.
Improves both performance and availability.
⚠️ Watch out:
Load balancers are most effective when your APIs are stateless—meaning they don’t store data in memory that’s specific to a single user or session. Otherwise, requests may hit a server that doesn’t know the context.
Popular load balancers include Nginx, HAProxy, AWS ELB, and Traefik.
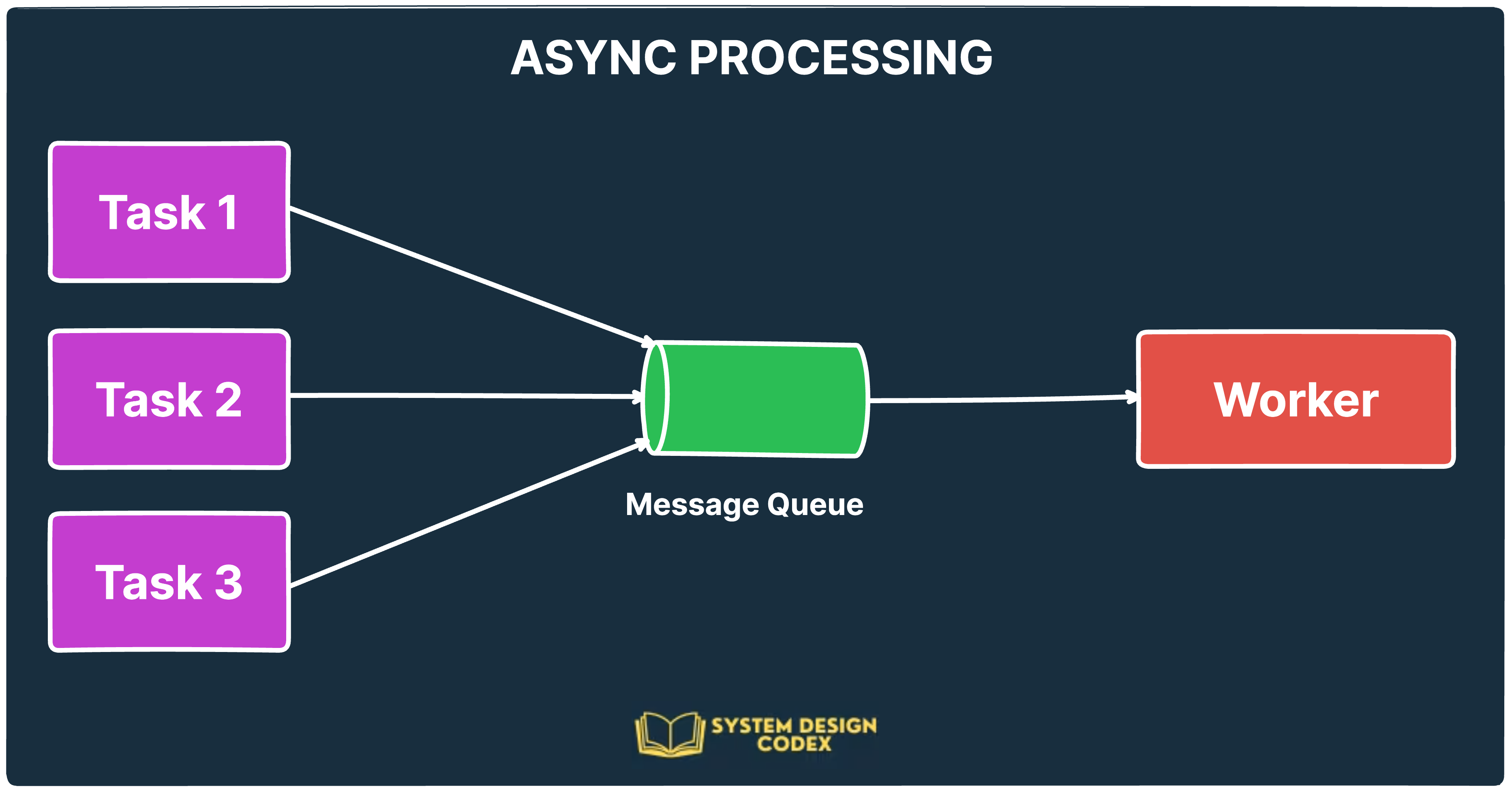
3 - Async Processing: Don't Keep the User Waiting
Not every request needs to be processed synchronously.
Sometimes, it’s smarter to accept a request, queue it, and return a response immediately, especially if the task takes time (e.g., sending emails, processing images, or running analytics).
This is where asynchronous (async) processing helps.
🔧 How it works:
The API receives a request and immediately acknowledges it.
The task is pushed into a message queue (like Kafka or RabbitMQ).
A background worker picks up the task and processes it independently.
💡 Benefits:
Frees up your API to respond faster.
Great for long-running or background tasks.
Prevents server resource exhaustion.
⚠️ Things to plan:
Users need a way to check status or receive notifications.
Ensure retries and error handling in the background processor.
4 - Pagination: Serve Data in Bites, Not Buffets
Returning thousands of records in one API response?
That’s a surefire way to overload your server, increase network latency, and frustrate your client.
Pagination helps you solve this by limiting how much data is sent per request.
🔧 How it works:
Clients send parameters like
page=1andlimit=20.The API returns only the requested slice of data.
Clients can request more pages as needed.
💡 Benefits:
Reduces payload size.
Improves perceived performance (faster UI updates).
Lowers the burden on both servers and clients.
Common approaches include offset-based pagination and cursor-based pagination (for better performance at scale).
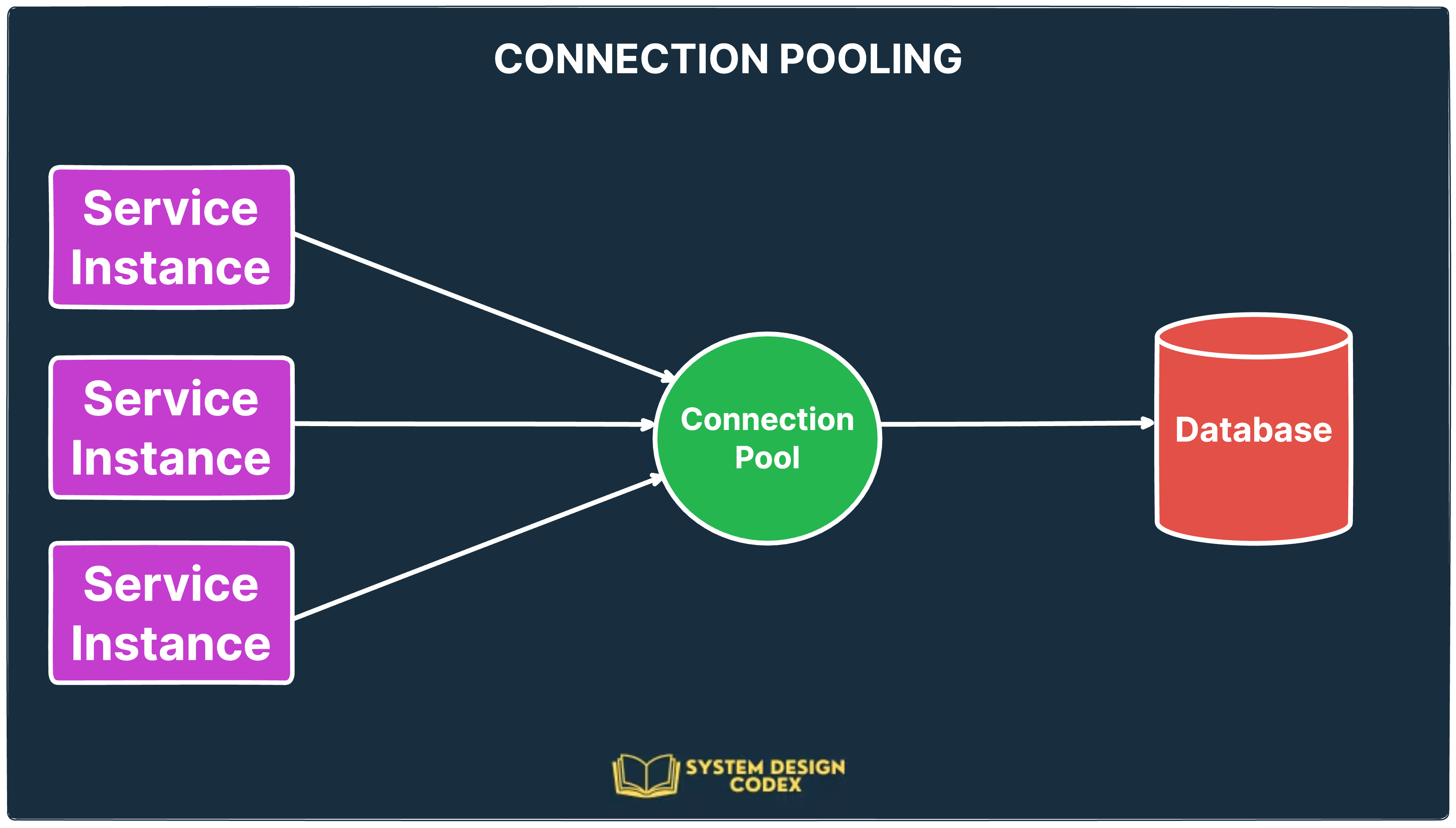
5 - Connection Pooling: Reuse Your Database Connections
Behind every API call, there’s often a database query.
Now, imagine your API creating a new database connection for every request. That’s like opening a brand-new water tap for every sip—wasteful and slow.
Connection pooling helps by maintaining a pool of pre-established connections to the database.
🔧 How it works:
When a request comes in, it uses an existing connection from the pool.
After the query, the connection is returned to the pool instead of being closed.
If all connections are busy, the request waits briefly for one to be available.
💡 Benefits:
Saves time and system resources.
Handles concurrent users more efficiently.
Reduces the load on your database.
Most web frameworks and ORMs support connection pooling (e.g., HikariCP, SQLAlchemy pools, pgbouncer for PostgreSQL).
So, will you add any other API Performance Improvement Tips to the list?
Shoutout
Here are some interesting articles that I read this week:
Mastering Linked Lists: A Complete Guide by
Load Balancer vs Reverse Proxy vs API Gateway by
How to scale a relational database by
10 Best Resources to Learn Data Structures and Algorithms in 2025 by
That’s it for today! ☀️
Enjoyed this issue of the newsletter?
Share with your friends and colleagues.
Thank you for mentioning our article Saurabh, appreciate it
- Use HTTP 2 could increase a lot of performance.
- Warm up, sometimes services are slow starting.
- Payload compression