
An Intro to LSM Trees
Guaranteeing fast writes to DB

How do you guarantee fast writes to the database?
Choose a database with a storage engine that follows the LSM Tree approach to store and retrieve data.
An LSM Tree, which stands for Log-Structured Merge-Tree, is a data structure designed to store and retrieve key-value pairs efficiently. It is specifically optimized for high write throughput.
Storage engines based on this data structure are called LSM storage engines. For example, LevelDB and RocksDB are a couple of key-value storage engine libraries that use LSM trees. Similar storage engines are also used in databases like Cassandra and HBase.
4 Steps to LSM Storage Engine
Here’s how a typical LSM Storage Engine works:
STEP 1: When a write request for a key-value pair arrives, it is added to an in-memory structure known as memtable.
STEP 2: When the memtable gets bigger than some threshold, it is flushed to disk as an immutable file called an SSTable (Sorted String Table). This is handled asynchronously so that the new requests are not blocked.
STEP 3: To serve a read request, first try to find the key in the memtable, then in the most recent SSTable, then in the next older SSTable, and so on.
STEP 4: To keep the number of SSTable files in check, run a periodic merging and compaction process in the background to combine them and discard overwritten or deleted values.

Components of an LSM Tree
What is an LSM Tree made up of?
It has a few key components:
Memtable
SSTable
Compaction Process
The diagram below shows the overall design of LSM Trees

1 - Memtable
Imagine having a notebook where you write down new information as it comes in. In an LSM Tree, this notebook is called a memtable.
It’s a place in memory where all the new data is initially stored. You can use well-known tree data structures (such as red-black trees or AVL trees) to insert keys in any order and read them back in a sorted order.
For example: let’s say you are running a bookstore and want to keep track of your inventory. Whenever you receive a new shipment of books, you write down the book name and quantities in your memtable.
Here’s how the memtable looks like:

2 - SSTable
SSTables are files on disk that store the data from the memtable in a sorted order.
When the memtable reaches a certain size threshold, its contents are flushed to disk as an SSTable file.
For example: taking our bookstore example, here’s how the data might look in the SSTable

As more updates come in, new memtables are created and flushed to disk as additional SSTables.

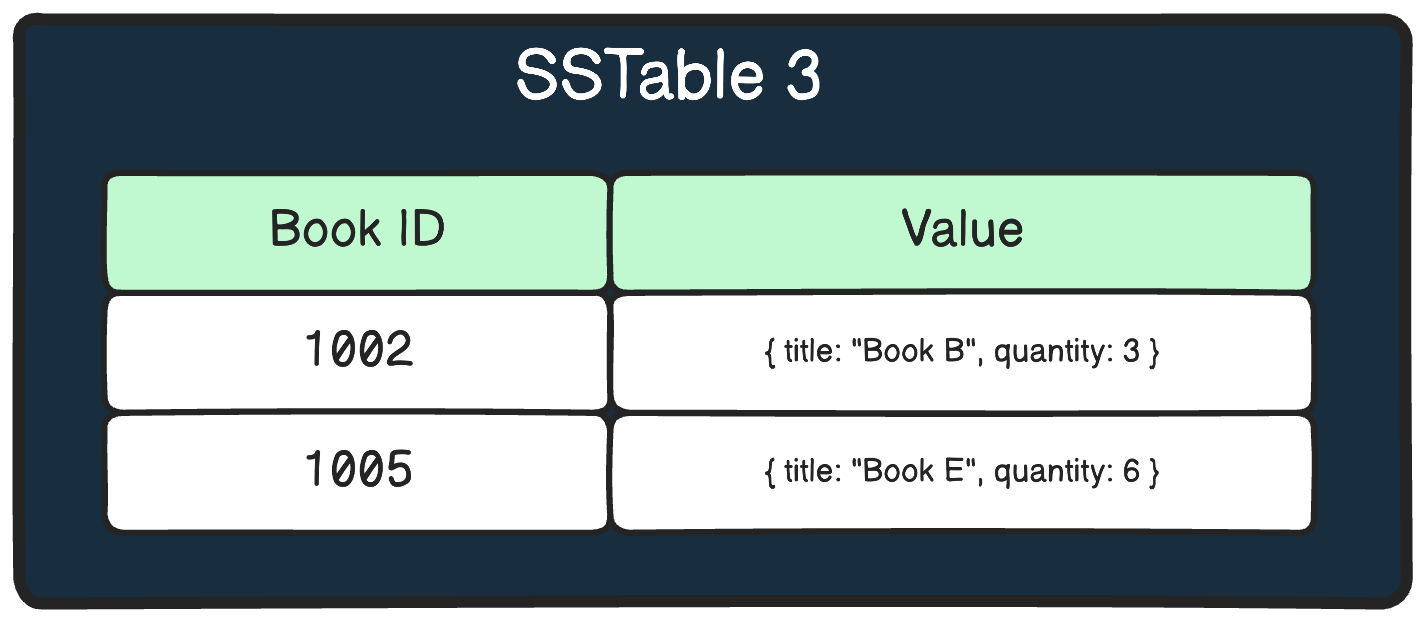
3 - Compaction Process
Over time, you might end up with many SSTable files, making it harder to find specific information.
As the number of SSTables grows, the LSM Tree performs compaction to merge the smaller SSTables into larger ones. During compaction, the data is merged based on the key, and the latest values for each key are retained.
In our bookstore example, the data after compaction looks like this:

In this compacted SSTable, the latest values for each book are stored. For example, "Book A" has a quantity of 8, which is the most recent value from SSTable 2.
How LSM Trees Differ from B-trees?
Let’s look at the key differences between LSM Trees and B-Trees in some important aspects.
1 - Write Optimization
LSM Trees: Optimized for high write throughput. As we discussed, writes are initially stored in a memtable and later flushed to disk, allowing for fast and efficient write operations.
B-Trees: Writes require traversing the tree and potentially causing cascading splits or merges, which can be slower compared to LSM Trees.
2 - Read Performance
LSM Trees: Reads may require accessing multiple levels of SSTables, resulting in higher latency compared to B-Trees. Techniques like Bloom Filters can help but we will discuss them later.
B-Trees: Reads are faster as data is stored in a sorted manner, and the tree structure allows for efficient lookups.
3 - Space Amplification
LSM Trees: Due to the multi-level structure and the need for compaction, LSM Trees may have higher space amplifications compared to B-Trees.
B-Trees: They have lower space amplification as data is stored more compactly.
4 - Compaction Overhead
LSM Trees: Compaction is a background process that merges SSTables, which can consume I/O and CPU resources.
B-Trees: There is no separate compaction process, but they may require rebalancing and merging operations.
👉 So - have you used databases that support LSM Trees?
Shoutout
That’s it for today! ☀️
Enjoyed this issue of the newsletter?
Share with your friends and colleagues.
See you later with another value-packed edition — Saurabh
Saurabh friend is delivering high quality content as always! 💪
First time hearing this term, thanks for writing this up Saurabh! Aren't these systems prone to data loss - specifically during the memtable part where the data is stored in memory? Also, do you know if MongoDB also uses the LSM Tree approach, or is this more like your Redis and similar stuff?