
SDC#23 - Amazon's Dynamo Breakdown
Dynamo Design Goals, Consistent Hashing, Replication and more...

Hello, this is Saurabh…👋
Welcome to the 275 new subscribers who have joined us since last week.
If you aren’t subscribed yet, join 3500+ curious Software Engineers looking to expand their System Design knowledge by subscribing to this newsletter.
In this edition, I cover the following topics:
🧰 Case Study → Breakdown of Dynamo (Amazon’s Highly Available Key-value Store)
🍔 Food For Thought → Should you start a tech blog?
So, let’s dive in.
🧰 Case Study - Dynamo Breakdown
For starters, Dynamo is NOT the same as DynamoDB managed service that is part of the AWS platform.
Dynamo was born out of Amazon’s pressing need for a highly reliable, ultra-scalable key/value database. It was a response to outages that Amazon faced in the 2004 holiday season.
Of course, a lot of the principles Amazon used while building Dynamo went into the creation DynamoDB.
In fact, Dynamo has inspired multiple storage systems over the years. Studying about it can offer a lot of insights into the working of modern database systems.
But what exactly is a key/value database?
A key/value database is a type of NoSQL database that stores data as pairs of unique keys and data objects. This allows for quick retrieval of information based on the key.
Here’s a simple illustration of a key/value database.

Why Amazon Built Dynamo?
On a website like Amazon, sales are heavily dependant on how the user feels while browsing the catalog, viewing products or selecting them for purchase.
If the website seems slow and key features don’t work as expected, it can turn a potential customer away from the platform forever.
Three factors are super-important:
Reliability
Performance
Scalability
And if balancing those three factors wasn’t hard enough, Amazon is also built using a high decentralized, loosely coupled, service-oriented architecture. There are literally thousands of services that work in tandem to make Amazon function as intended.
It’s pretty obvious that providing a perfect availability level with a good enough performance in such a system is quite a challenge.
The application state or data should be always available.
In a system as big as Amazon, there are always chances of failing disks, faulty network connections or even entire data centers being impacted by some calamity. And despite all this, the customers should be able to view and add items to their shopping carts, make payments and track their orders.
The development of Dynamo was a direct result of these difficult requirements.
Amazon’s View of a Service Boundary
Before we get into the details of Dynamo, let’s look at Amazon’s idea of a service boundary.
Amazon categorizes services in two ways:
Stateless services that aggregate responses from other services
Stateful services that executes business logic based on its state stored on a persistent store.
See the below diagram that shows the service-oriented architecture of Amazon’s platform.

As you can see, there are several layers of services that make up the Amazon stack.
A typical page request to the e-commerce site may involve sending requests to over 150 services. To make things even more complicated, these services also depend on other services and the call graph is usually more than one level deep.
To maintain a good user experience, each service needs to stick to its Service Level Agreement (SLA) in terms of the response times and availability.
Executing complex business logic can impact the response times. However, for the typical use-cases on Amazon’s e-commerce platform, the business logic is mostly lightweight.
The complexity of scale mostly exists on the data side.
Therefore, the storage system i.e. Dynamo is often the most important factor in meeting the SLA of a service.
Design Goals behind Dynamo
Now, before building Dynamo, Amazon had a few important design goals:
1 - Simple Query Model
The idea was that a large number of Amazon’s services can work with a simple query model and doesn’t need a relational schema.
For this reason, Dynamo will use a simple query model.
You read based on a key. Also, you write based on a key.
There will be no operations involving multiple data items that may require a relational schema.
2 - No need of ACID Guarantees
As you might be aware, ACID guarantees the reliability of a transaction.
In typical relational databases (especially at the time when Dynamo was built), providing these guarantees can result in poor availability.
For Amazon, the main focus of Dynamo was high availability. Therefore, Dynamo is would be meant for applications that can operate with a weaker consistency level.
This meant no isolation guarantees and only single key updates.
3 - Incremental Scalability
Dynamo should be able to scale out one storage host (or node) at a time with minimal impact on the clients of the system and the team operating the system.
Here, scale out refers to the ability to horizontally scale a system based on the demand. I talked about it in an earlier post (so you can check it out after reading this post)

4 - Always Writeable
Dynamo should be “always writeable”. In other words, a data store that’s always available for writes.
For a lot of Amazon services, rejecting customer updates could result in a poor user experience. For example, you don’t want to stop the users from adding items to a shopping cart in case of a network failure or conflicting data.
Architecture of Dynamo
Now that we understand the design goals Amazon had with Dynamo, let’s look at its overall architecture and how they achieved those goals.
To make things understandable, I’ll be focusing on 6 main parts:
1 - The Interface
Dynamo exposes a super-simple interface for the clients.
This interface has just two operations - get() and put().
The get() operation takes a key as input and finds the data object associated with that key within the storage. It returns a single object or a list of objects in case there are conflicting versions. Also, it returns a special context object.
The put() operation takes the key, data object and context as input. Using the key, it determines where the data object should be placed in the storage and writes the data to disk.
What’s the deal with the context object?
The context stores information about the object’s version.
As we will see in a later section, this contains the object’s vector clock. It is actually opaque to the caller and handled by the Dynamo client itself.
2 - Partitioning Algorithm with Consistent Hashing
As we discussed earlier, incremental scaling is a primary design goal of Dynamo.
For a database, this means the ability to partition the data over a set of nodes (or server hosts).
Dynamo uses Consistent Hashing to perform the partitioning.
But what is Consistent Hashing?
As you know, each data object stored in Dynamo has a key. With consistent hashing, you hash the keys using a hash function (using something like MD5 algorithm). The output range of these key hash values is treated as a fixed circular space or ring.
See below illustration that describes this transformation:

Here, K1, K2, K3 and so on are the positions of the keys on the hash ring.
Next, we also hash our servers (storage nodes) on the ring.
This is usually done by hashing the IP address or domain name of the node using the same hash function that we used for the keys.
See the below diagram where we also have host servers A, B and C mapped to specific positions on the ring:

But how are the keys in Dynamo assigned to a particular node or host server?
It’s a straightforward process:
We hash the key to determine its position on the hash ring.
Then, we traverse the ring in clockwise direction starting from the position of key until a node is found
When the node is found, we store the data object on that node.
The below illustration makes it crystal clear:

As we move clockwise from K1, the first node is A. Hence, K1 is stored on A. Similarly, K2 is stored on B and K3 is stored on C.
To express things even more simply, each node is responsible for the region between it and its predecessor node on the ring. For example, node B is responsible for all the keys falling between node A and node B on the hash ring.
Sounds perfect?
Yes, it does. But the basic consistent hashing has two major downsides:
First, random position of each node on the ring can result in non-uniform data distribution
Second, it doesn’t take into account the node’s resource capacity. Bigger nodes and smaller nodes are treated in the same way even though they have different storage capacities.
To deal with these problems, Dynamo uses a variant of consistent hashing that applies the concept of virtual nodes.
“What are virtual nodes?” - you may ask.
With virtual nodes, you don’t map a node to a single point in the circle. Instead, each node gets mapped to multiple points in the ring. These points are also known as tokens and are determined using different hash functions.
All of these multiple points are basically virtual nodes pointing to a single physical node.
Check out the below illustration that shows consistent hashing with virtual nodes.

As you can see, each of the nodes A, B and C are mapped to three distinct positions on the ring.
For example, node A is represented with A0, A1 and A2. There are is only one physical node A. But it maps to three virtual nodes.
With virtual nodes, you get a few nice advantages:
If a node becomes unavailable for some reason or is added again, there is an even distribution of data.
Also, nodes can be assigned more tokens based on server capacity. This way, nodes with higher capacity get more data and smaller ones get less data.
3 - Data Replication
Another major design goal of Dynamo is high availability and durability.
To achieve this, Dynamo replicates data for a particular key on multiple physical hosts or nodes. The number of nodes is controlled by a special parameter known as N.
Each key is assigned to coordinator node. The coordinator is responsible for storing each key assigned to it locally as well as replicating it to N-1 additional nodes. For example, if N has a value of three, the coordinator node will replicate the key to another two clockwise successor nodes in the hash ring.
See the below diagram for reference:

With virtual nodes, it is possible that the first N successor positions may not be occupied by N physical nodes. It might be a virtual node pointing to the same physical node.
Dynamo takes care of this by skipping positions in the ring to ensure that the key is replicated to only distinct physical nodes.
4 - Data Versioning with Vector Clocks
Dynamo is an eventually consistent system.
Updates are sent to the replicas asynchronously. In other words, the client may receive confirmation of an update from the database before the update has reached all the replicas.
This situation happens because of replication lag. In case you are interested to read more, check out my detailed post on replication lag.

Anyways, there are many services in Amazon’s platform that can tolerate such inconsistencies. For example, the shopping cart app at Amazon requires that an “Add to Cart” operation must never be forgotten or rejected.
It’s possible that the latest version of the cart isn’t available. But the user can still make a change to the older version and this change should be preserved. However, it also doesn’t mean that the unavailable version of the cart is completely forgotten.
Basically, what all of this means is that conflicting versions of the shopping cart can exist and the system has to maintain all of them. After all, Amazon wouldn’t want to miss on the chance to sell an extra item.
To deal with these conflicts, Dynamo uses vector clocks.
“But what is a vector clock?” - you may ask.
In Dynamo, a vector clock is a list of (node, context) pairs. Basically, the node that created or updated a data object and the version of the update.
There’s a vector clock associated with every version of every object. By examining these vector clocks, one can determine whether an object version can be ignored.
Check the below flow diagram for reference:

Let’s understand this in a step-by-step manner.
A client writes a new object to Dynamo. The node (Nx) that handles the write for this key increases its sequence number from 0 to 1 and uses it to create the data’s vector clock. In simple terms, there is now a data object D1 and its vector clock is
[(Nx, 1)].Now, the client updates the object. Assuming that the node Nx handles this request as well, the system now has a data object D2 with a clock value
[(Nx, 2)].D2 descends from D1 and over-writes D1. This relation is quite clear by looking at the vector clocks.
Let’s say another update happens on the same object but this time, a different node (Ny) handles the request. Now, you have data object D3 with an associated clock
[(Nx, 2), (Ny, 1)].Now, assume that another client reads D2 and tries to update it. The request goes to a 3rd node (Nz). This creates D4 (another descendant of D2) with a vector clock
[(Nx, 2), (Nz, 1)].A node that is aware of D1 or D2 and receives D4 and its clock can understand that D1 and D2 are overwritten by the new data because of the presence of
(Nx, 2)However, a node that is aware of D3 and receives D4 (with its vector clock) won’t be able to determine any causal relation between the two. Basically, there are changes in D3 and D4 that are not reflected in each other. And therefore, both versions of the data must be preserved and presented to a client for reconciliation.
Assume that the client does the reconciliation and node Nx coordinates the writes. In this case, Nx will update the data object to D5 with the clock value as
[(Nx, 3), (Ny, 1), (Nz, 1)].
5 - Execution of Get and Put Operations
Earlier, we talked about Dynamo supporting a simple interface with just two operations - get() and put().
Here are some key points on how Dynamo deals with these operations internally:
Both get() and put() can be handled by any storage node.
When a client makes a request, it needs to select a node. There are two options available
Using a generic load-balancer
Using a partition-aware client library
To maintain consistency among replicas, Dynamo uses a consistency protocol. As per this protocol, there are two configurable values - R and W.
R is the minimum number of nodes that must participate in a successful read operation. W is the minimum number of nodes that must participate in a successful write operation.
If R + W > N (where N is the number of nodes to involve), you get a quorum-like system.
The latency of a request (get or put) depends on the slowest of the R or W replica. Therefore, it’s a good idea to have R and W be less than N.
When a coordinator node receives a put() request, it generates the vector clock for the new version and writes the data locally. The coordinator node also sends the new version (along with the clock) to the N highest ranked reachable nodes. If W - 1 nodes respond then the write is considered successful.
If W = 1, the writes are highly-available because write operation can fail only when the entire cluster is down. However, this reduces the durability of the data since Dynamo will write the key to only one node.
For a get() request, the coordinator requests all existing versions of data for that key. It waits for R responses before returning the result to the client. In case of conflicting versions, the coordinator node returns all of them for reconciliation.
6 - Failure Handling with Hinted Handoff
We looked at the operations when things are working fine.
But how does Dynamo handle failure scenarios?
To deal with failures, Dynamo uses the concept of sloppy-quorums. What this means is that all read and write operations are performed on the first N healthy nodes from a preference list. These nodes may not always be the first N nodes while walking the hash ring.
For example, if N=3 and node A is down or unreachable during a write operation, then a replica meant for node A will be sent to node D. This maintains the desired availability and durability guarantees.
However, the replica sent to D will have a hint in its metadata that it actually belonged to node A. Based on the hint, D will keep such records in a separate local database. Periodically this database is scanned and when node A recovers, D will deliver the replica back to A. Post the transfer, D will delete the object from its local store.
See the below diagram that shows the process:

This entire process is known as Hinted Handoff and it is quite similar to the Buffered Writes used by Uber when they built their own database from scratch.
I wrote about Uber’s buffered writes in an earlier edition:

Conclusion
All in all, Dynamo offers an excellent sneak peek into the challenges of building a modern key/value database.
In this post, I’ve covered the details about how Dynamo works. The main reference for this post comes form the original Dynamo research paper published by Amazon. However, a lot of the gaps in explanation have been filled after looking into the various topics.
There are many other aspects of Dynamo such as the internals, permanent failure, ring membership and balancing performance with durability that can offer more insights.
If you enjoyed this post, do give it a like and let me know in the comments section whether you’d like a Part 2.
🍔 Food For Thought
👉 As a developer, should you start a blog?
Yes, you should. In my view, there’s very little downside to starting a blog.
In fact, the upsides are pretty amazing.
The below post by Fernando echoes the same idea.
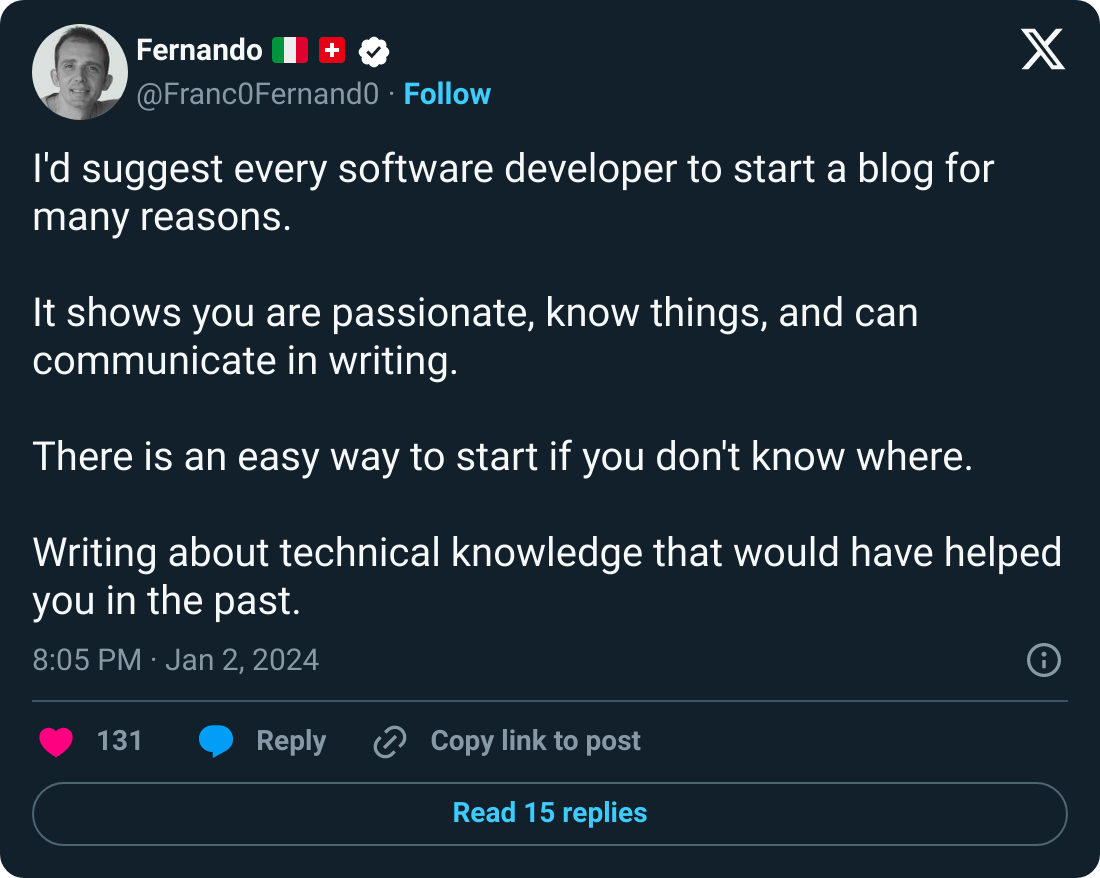
Here’s the link:
https://x.com/Franc0Fernand0/status/1742192773556568107?s=20
That’s it for today! ☀️
Enjoyed this issue of the newsletter?
Share with your friends and colleagues
See you next week with another value-packed edition — Saurabh