
7 Techniques for Database Performance & Scaling
Factors that impact performance

Data storage is probably the most important capability for an application.
While computing has many applications even when storage is not involved, it’s hard to imagine the utility of software systems for a majority of normal users in the absence of storage systems like databases.
Naturally, this means that the performance and scalability of databases play a big role in shaping an application’s user experience.
There are so many factors that can impact the performance of a database. Some important ones are as follows:
Item Size: The average payload size of an item stored in the database determines whether the workload is CPU-bound or storage-bound.
Item Type: The type of item directly impacts the kind of compression that is possible. For example, if you’re storing text, you can take advantage of a high compression ratio. Not so much when you store images, videos, or encrypted data.
Total Dataset Size: This one directly impacts the infrastructure options and whether you’d need to go for replication and sharding.
Throughput and Latency Requirements: Just saying “high throughput” is not enough. It’s critical to know the target throughput for choosing the optimal database type and infrastructure.
Having said that, databases also evolve along with your application. From time to time, you may need to come up with new strategies to extract the best performance and scalability out of your database.
Let’s look at a few tried and tested strategies that can boost the performance of the database as well as help you scale it better.
1 - Indexing
In databases, an index acts as a "table of contents" for your data.
It allows the database to quickly locate and retrieve specific information without scanning through every single record. Without an index, the database would have to scan the entire table to find matching records.

For example, if you have a "Customers" table with columns like "ID", "Name", "Email", and "City". In case you often search for customers by email, creating an index on the "Email" column can make a huge difference.
Key benefits of indexing are:
Faster queries
Reduced resource usage
Increased concurrency
The trade-offs are as follows:
Extra disk space for each indexed column
More work during write operations to update the index.
2 - Materialized Views
A materialized view is like a snapshot of a query result, stored separately from the original data.
It's derived from one or more tables or views and is maintained independently. Think of it as a pre-calculated summary that you can quickly access whenever you need it.

This materialized view can be refreshed periodically to keep the data up to date.
Key benefits of materialized views are:
No need to run complex and time-consuming queries in the user request flow.
Reduced load
The trade-offs are as follows:
Extra storage
Higher refresh time and inconsistent data in the view
3 - Denormalization
Denormalization involves duplicating data across multiple tables to optimize query performance. The goal is to reduce the number of joins and computations required to retrieve data, making queries faster and more scalable.
In other words, the rules of normalization are relaxed a bit in favor of performance.
Imagine an e-commerce store with a "Customers" table and an "Orders" table. In a normalized design, the "Orders" table would only store a reference to the "Customers" table.
To get the customer details with the order information, you'd need to join the two tables. However, as the number of orders grows, the join operation can become a performance bottleneck.
That's where denormalization comes in handy.
By storing a field like the “CustomerName” directly in the "Orders" table, you can retrieve the details along with order information in a single query. Note that this is just an example scenario and doing so may depend on the overall system context and the data modeling rules in place.

Benefits of Denormalization:
Faster queries
Reduced overhead
Improved read performance
The trade-offs are as follows:
Data redundancy.
Complex updates since redundant data may need to be kept in sync across multiple tables.
Potential inconsistency.
4 - Vertical Scaling
Vertical scaling, also known as "scaling up," is a technique that focuses on increasing the hardware resources of a single server.
It's all about making your database server bigger, stronger, and faster.

A few easy ways to do so are:
Upgrading to a faster CPU
Adding more memory to your server
Switching to high-performance storage devices like SSDs.
There are several benefits of Vertical Scaling:
Better performance
Simplified management
Reduced latency
However, there are some limitations as well:
There’s a limit to how much you can vertically scale a server before hitting some cost constraints.
A single server failure can bring down your database.
Upgrading hardware can be expensive.
5 - Caching
Caching is a technique that involves storing frequently accessed data in a high-speed storage layer, separate from the primary database.
When an application receives a request for data, it first checks the cache. If the data is found (a cache hit), it's quickly retrieved without bothering the database. If the data is not found (a cache miss), the application fetches it from the database and stores a copy in the cache for future requests.
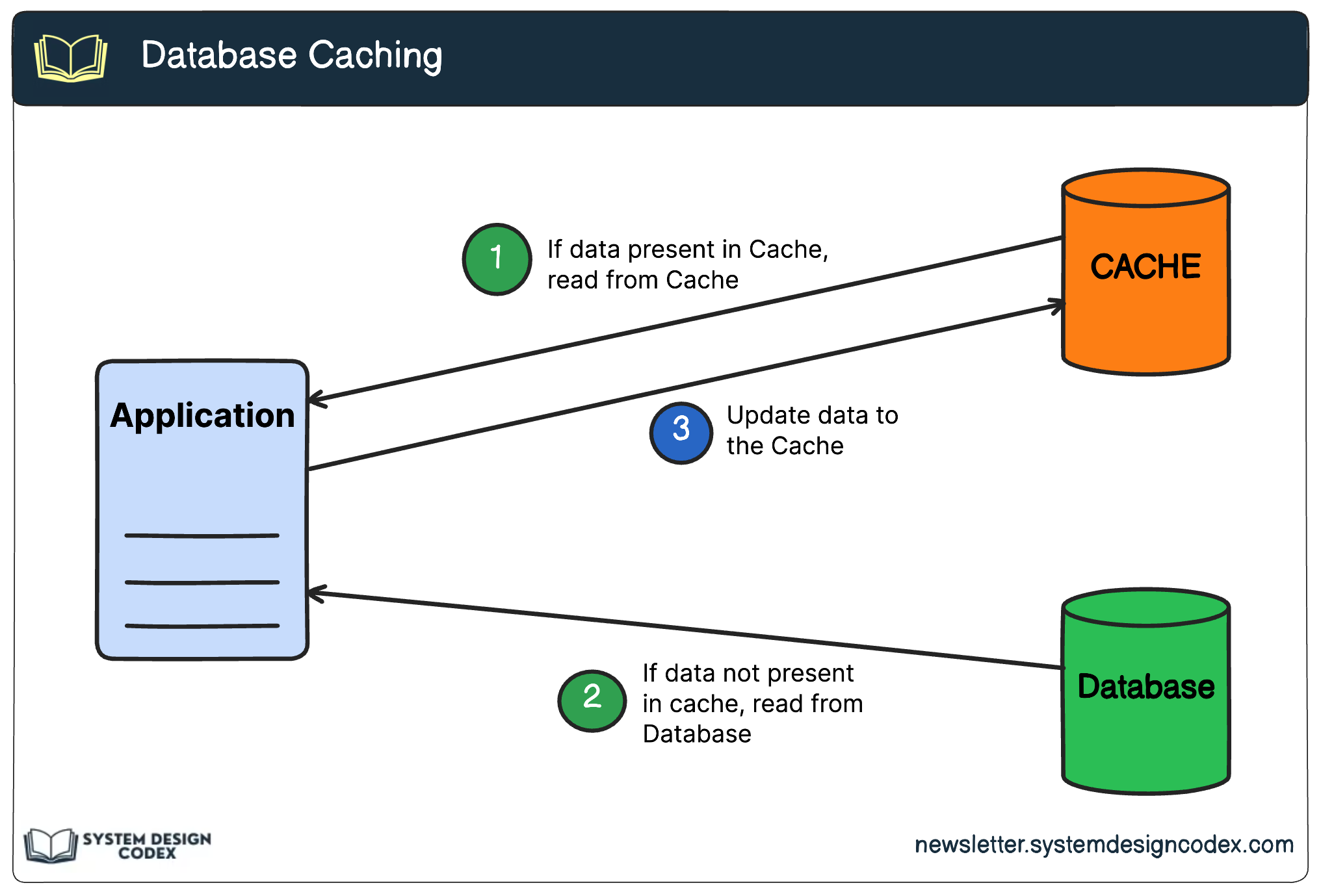
The benefits of Caching are as follows:
Reduced database load
Improved read performance
There are some trade-offs as well:
Additional complexity
Extra cost
Chances of stale data
6 - Replication
Replication is a technique used in database systems to create and maintain multiple copies of data across different servers or nodes.
In a typical leader-follower replication model, one node is designated as the leader, while the others are followers.
The leader handles all the write operations ensuring consistency and integrity. The changes are automatically shared with the follower nodes whenever a write operation is performed on the leader node. The leader can also handle critical read operations where high consistency is required.
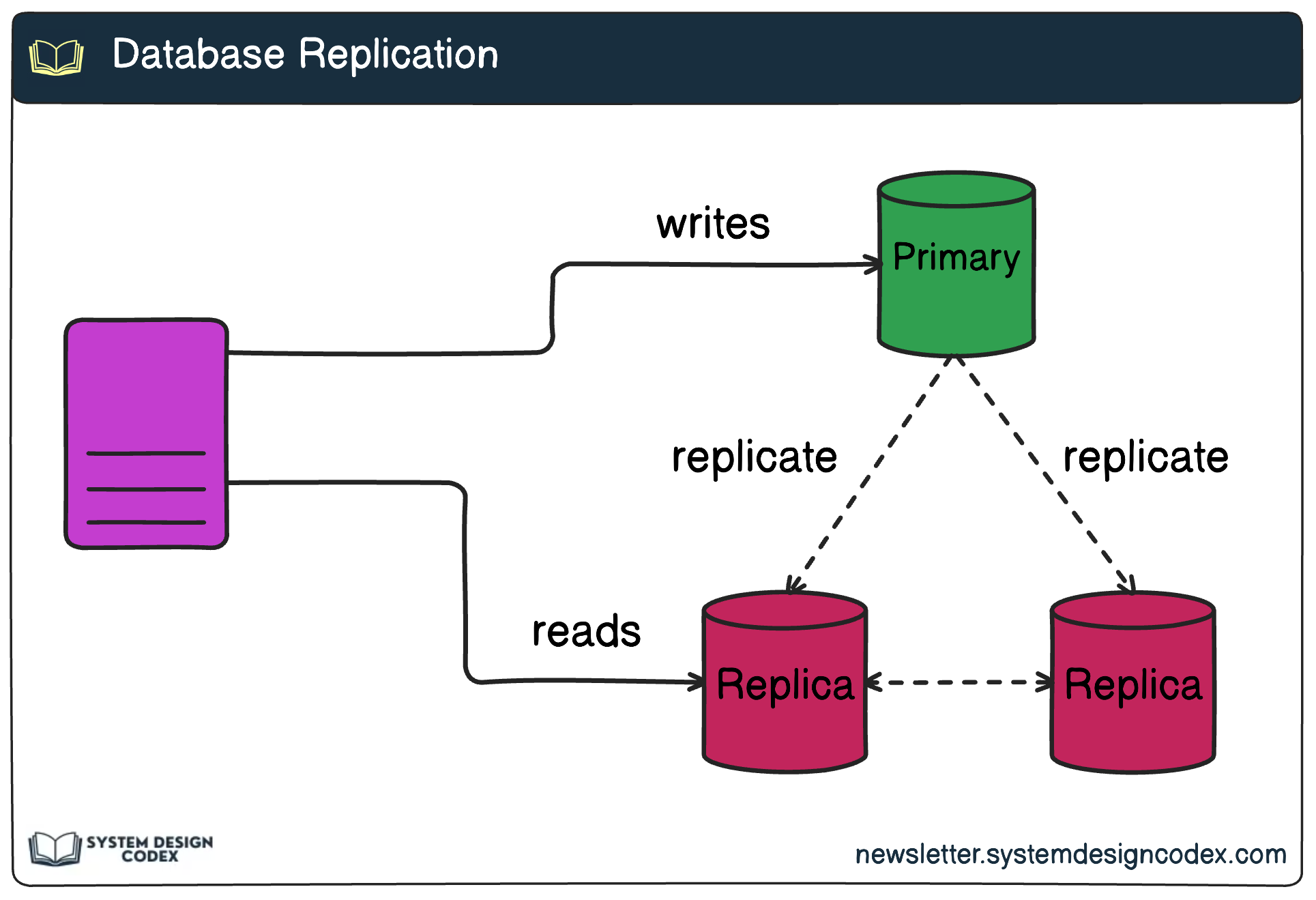
The follower nodes, in turn, handle read operations and help distribute the workload to improve performance.
The benefits of Replication are as follows:
Improved Read Performance
High Availability
Durability
There are also some trade-offs:
Introduces some delay in data synchronization known as replication lag
Increased complexity
7 - Sharding
Database sharding is a technique that partitions a single large database into smaller, more manageable units called shards.
In a sharded database architecture, data is distributed across multiple shards based on a specific sharding key. The choice of the sharding key determines how the data is allocated to different shards.
Common sharding strategies include:
Range-based Sharding: Data is partitioned based on a range of values of the sharding key.
Hash-based Sharding: A hash function is applied to the sharding key to determine the target shard.
Directory-based Sharding: A separate lookup table is maintained to map the sharding key to the corresponding shard.

The benefits of Sharding are as follows:
Sharding allows for horizontal scaling of the database.
Queries and write operations are processed in parallel.
Reduced hardware costs when compared to vertical scaling.
However, there are also trade-offs:
Sharding introduces additional complexity.
Rebalancing data across shards can be a complex and time-consuming process.
Joining data across shards can be challenging.
So - how do you improve the performance and scalability of the database?
Here are some interesting articles I’ve read recently:
An introduction to the Sidecar design pattern by Franco Fernando
10 Tips to Identify and Fix Your Writing as a Software Engineer by Akos
TCP #18: When every second counts, your incident response can be your strongest asset by Amrut Patil
That’s it for today! ☀️
Enjoyed this issue of the newsletter?
Share with your friends and colleagues.
See you later with another edition — Saurabh
Very insightful and easy to understand. I appreciate the way you structured the content. I really enjoyed it and look forward to reading more articles like this.
Very important techniques to remember as your database scales. Thanks for the mention Saurabh👍