
5 Strategies for High-Availability Systems
Availability is critical to the user experience...

Imagine you're running a bustling airport, with planes taking off and landing every minute.
The last thing you want is for your control tower to go down, causing chaos and delays.
Similarly, in the era of 24/7 online services, high availability has become a sort of holy grail. You are expected to ensure that your systems are always up and running, even when you are packing off for a weekend hike with your friends and family.
So - what do you do?
Naturally, you don’t want to ruin your holidays or family time.
Therefore, you need to apply some strategies for making your system highly available.
Let’s look at 5 really important ones:
1 - Load Balancing
Coming back to the airport example, let’s say your system is like a busy airport and incoming requests are like airplanes requesting to land.
But you’ve got only 2 runways.
This is where an air traffic controller directs the planes to different runways, manages the load on each runway, and keeps the traffic ticking along without causing congestion.
A load balancer is the air traffic controller for your application.
The load balancer analyzes multiple factors like CPU utilization, memory usage, and response times to route requests to the most available and responsive servers.
By spreading the load, you prevent any single server from getting overwhelmed, ensuring a smooth flow of operations, even during peak loads.

2 - Data Redundancy with Isolation
What happens when the airplane for a given route develops a snag and cannot operate?
If you are running an efficient airline company devoted to excellent customer service, you’d likely have a backup airplane to take the passengers to their destination.
The same goes for redundancy of the data in your application.
It involves storing multiple copies of your data in different locations, such as across multiple data centers or cloud regions.
This way, if one data center experiences a failure or an outage, your users can continue accessing the data from another location.
Database replication, object storage, and distributed file systems are common technologies used to implement data redundancy.
3 - Failover
Have you ever gone for skydiving and as you are falling to the ground, you realize that the the one-and-only parachute strapped to your back is faulty?
Well - I guess not!
However, if you were in such a situation, you’d desperately wish you had a backup parachute that could be deployed easily.
In the context of system design, failover is that parachute.
It refers to the automatic switching of a system or service from a primary component to a standby or backup component when the primary fails.

This could involve transferring network traffic to a backup server, switching to a secondary database, or redirecting users to a mirrored application instance.
Failover mechanisms are typically built into load balancers, application servers, and database management systems, ensuring a quick transition with minimal downtime for your users.
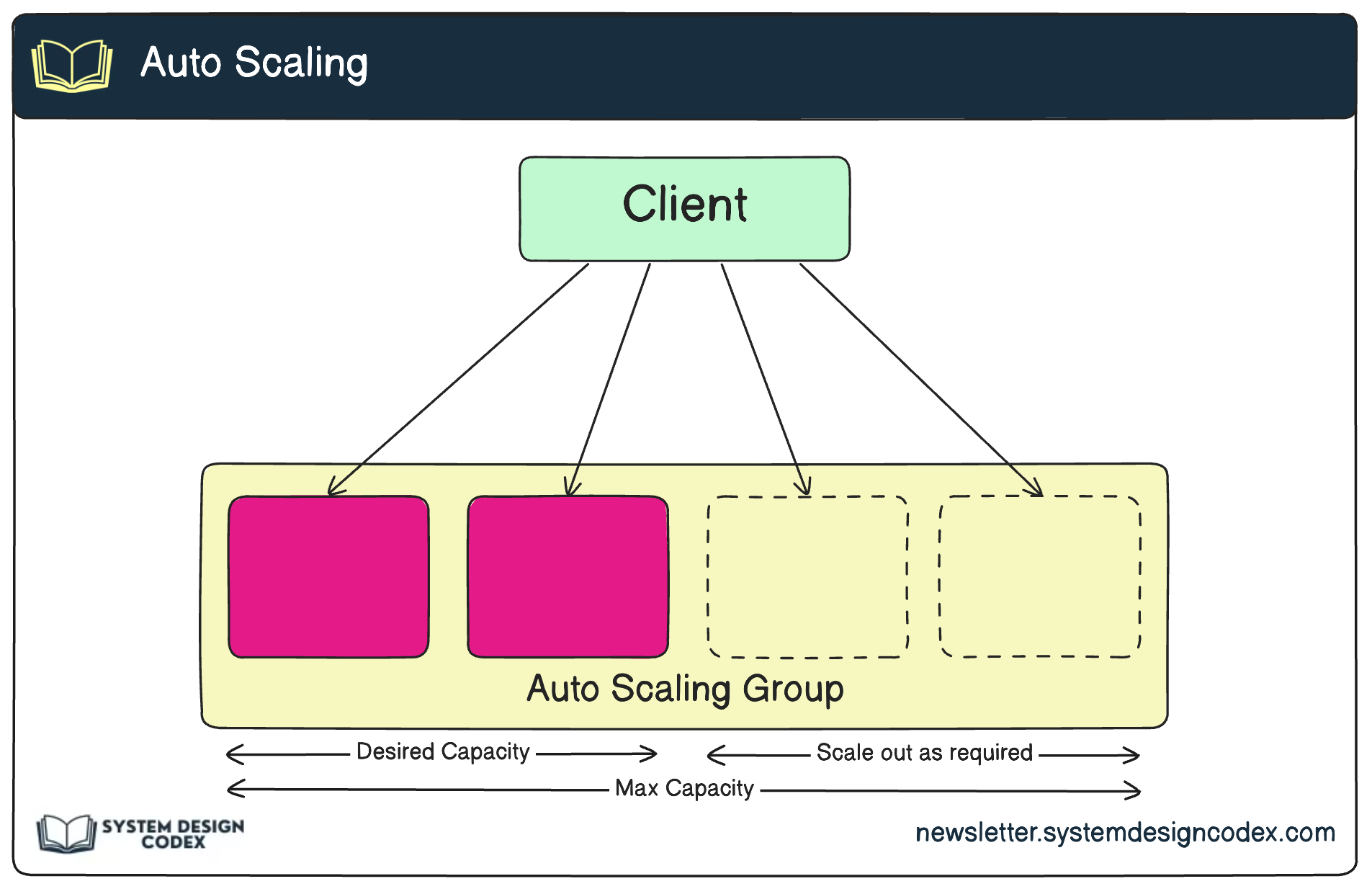
4 - Auto Scaling
When it comes to high availability, auto-scaling may sound a lot like a powerful fighter aircraft that can adjust its thrust based on the current requirements of the combat scenario.
In system design, this strategy involves dynamically allocating or deallocating computing resources (such as virtual machines, containers, or serverless functions) based on the current load and usage patterns.
Auto-scaling can be triggered by metrics like CPU utilization, memory usage, or incoming request rates, and is often implemented using cloud platform services or custom-built scaling algorithms.
As user traffic fluctuates, auto-scaling ensures your systems always have the necessary capacity to handle the load, preventing performance degradation or outages.
5 - Rate Limiting
Imagine that the runway in your super busy airport can only handle 2 landings every 15 minutes.
If you try to squeeze in any more landings, you run the risk of causing an accident and completely rendering the runway useless. Not to mention the danger to the lives of passengers.
In this case, the air traffic controller also acts as a rate limiter by coordinating the incoming airplanes in such a way that only 2 are allowed to land every 15 minutes.
The same concept applies to your application when it comes to user requests.
This strategy involves imposing a limit on the number of requests a user or a system can make within a given time frame, such as a fixed number of requests per second or per minute.
Rate limiting can be implemented at various layers, such as at the load balancer, web server, or application level.
By preventing any single user or system from using all the resources, rate limiting ensures fair and reliable service for all, and protects your system from being overwhelmed by sudden spikes in traffic.

So - have you used any other strategies to improve your application’s availability?
Eraser Free 1-Month Trial (Affiliate)
As you all know, I use the Eraser for drawing all the diagrams in this newsletter.
Eraser is a fantastic tool that you can use as an all-in-one markdown editor, collaborative canvas, and diagram-as-code builder.
And now you can get one month free on their Professional Plan or a $12 discount if you go for the annual plan. The Professional Plan contains some amazing features like unlimited AI diagrams, unlimited files, PDF exports, and many more.
Head over to Eraser and at the time of checkout, use the promo code “CODEX” to get this offer now.
Shoutout
Here are some interesting articles I read this week:
That’s it for today! ☀️
Enjoyed this issue of the newsletter?
Share with your friends and colleagues.
See you later with another value-packed edition — Saurabh.
Nicely put. Thanks Saurabh!!
Thanks for the shoutout, Saurabh. I liked this overview of the most common strategies. I haven't had (yet) the chance to work on a high-availability system, but I've implemented load balancing and rate-limiting even in smaller apps. I also did autoscaling, but not manually, but as part of AWS.