
4 Challenges of Distributed Systems - And Possible Solutions
Things to keep in mind...

Distributed systems are at the heart of modern technology, powering everything from internet services like Google to online banking platforms and multiplayer gaming networks.
They enable applications to scale, improve fault tolerance, and enhance system performance by leveraging multiple computers (nodes) working together.
However, designing and maintaining distributed systems comes with significant challenges. Let’s look at the major challenges and their possible solutions.
1 - Communication Challenges
Communication between nodes in a distributed system is inherently unreliable due to network failures, latency issues, and security vulnerabilities. When a system relies on multiple servers to work together, ensuring consistent, secure, and reliable communication is crucial.
Key Issues:
Packet Loss: Messages may be dropped due to network failures.
Out-of-Order Delivery: Messages may arrive at different times or out of sequence.
Security Risks: Data transmitted between nodes can be intercepted if not secured.
Techniques to Handle Communication Challenges:
a) Using TCP (Transmission Control Protocol)
Unlike UDP, TCP ensures message reliability by handling lost packets, retransmissions, and ordering.
TCP guarantees that messages arrive in sequence and without loss.

b) Securing Communication with TLS (Transport Layer Security)
Encrypting messages using TLS ensures that communication between nodes is secure and prevents data interception.
TLS-based encryption is used in HTTPS, banking transactions, and secure APIs.
c) Service Discovery with DNS
In dynamic environments (e.g., cloud-based applications, microservices), service discovery helps locate nodes without hardcoding IP addresses.
DNS-based service discovery (e.g., AWS Route 53, Kubernetes Service Discovery) ensures dynamic routing of requests to available nodes.

Example Use Case:
A microservices-based e-commerce platform needs to ensure that communication between the Order Service, Payment Service, and Inventory Service is secure, reliable, and properly sequenced. Using TCP for reliability, TLS for encryption, and DNS for service discovery ensures smooth communication.
2 - Coordination Challenges
Coordination among nodes is challenging due to:
Network Failures: Some nodes may go offline unpredictably.
Lack of a Global Clock: There’s no universal time across all servers.
Race Conditions: Multiple nodes modifying shared resources can lead to inconsistent states.
Techniques to Handle Coordination Challenges:
a) Failure Detection
Detecting node failures is critical for maintaining system reliability.
Heartbeat Mechanisms (nodes send periodic "I’m alive" signals).
Leader Election Algorithms (e.g., Raft, Paxos) select a leader to manage coordination.
b) Logical and Vector Clocks
Since nodes don’t share a global clock, they use logical timestamps (e.g., Lamport Timestamps) to track event order.
Vector Clocks help determine causal relationships between events.
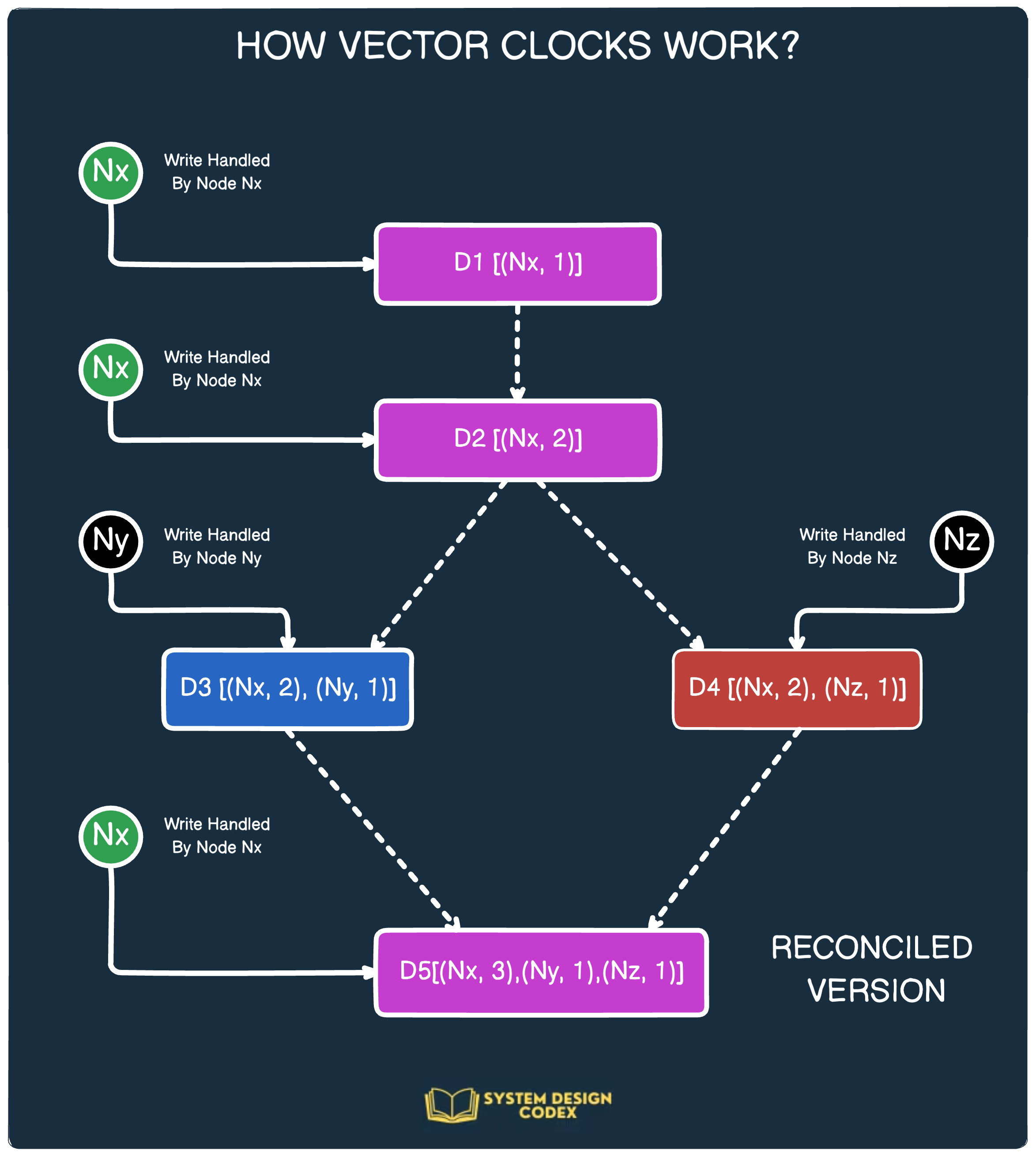
c) Consensus Algorithms
When nodes must agree on a decision (e.g., database writes, leader election), consensus algorithms help.
Paxos and Raft are used to ensure distributed consensus.
d) Data Replication
Primary-Replica Model: One primary node accepts writes, and multiple replicas serve reads.
Multi-Leader Replication: Used in high-availability scenarios where multiple leaders accept writes.
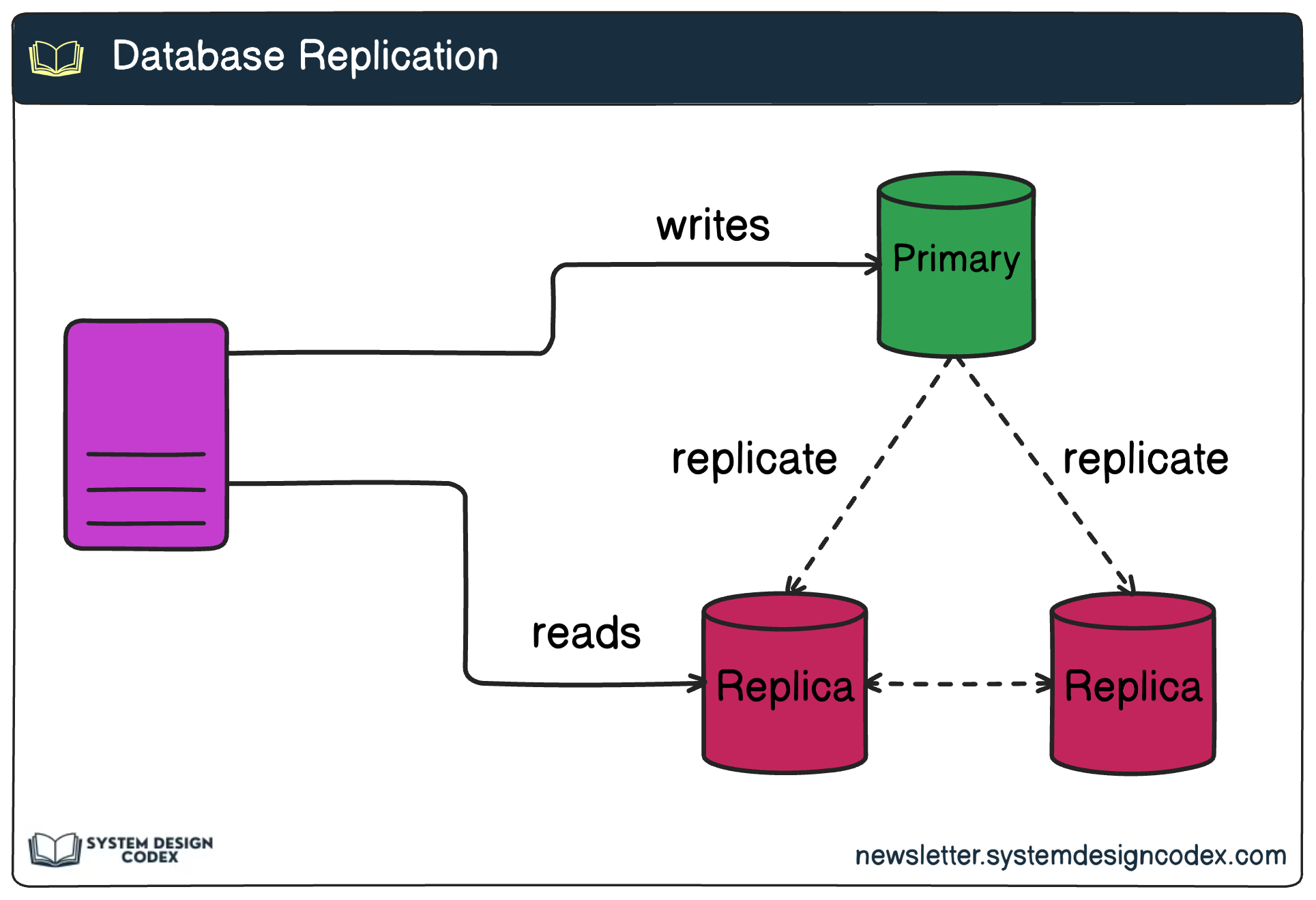
Example Use Case:
A distributed database needs to ensure that transactions are synchronized across multiple data centers. Using Raft for consensus, vector clocks for event ordering, and failure detection to handle server crashes ensures consistent coordination.
3 - Scalability Challenges
Scalability is a major advantage of distributed systems, allowing them to handle increasing workloads by adding more nodes. However, choosing the right scalability pattern is essential for performance and efficiency.
Key Scalability Patterns:
a) Microservices Behind a Gateway
Breaking a monolithic system into microservices allows independent scaling.
An API Gateway routes requests to the correct microservice.
b) Load Balancers
Distributes requests across multiple servers, preventing overload.
Types:
Round Robin: Assigns requests sequentially.
Least Connections: Routes traffic to the least busy server.
Geographical Load Balancing: Routes users to the nearest data center.

c) Functional Decomposition with CQRS
CQRS (Command Query Responsibility Segregation) separates read and write operations into different services.
Read-heavy workloads use denormalized views, and write-heavy workloads optimize for consistency.

Example Use Case:
A social media platform with millions of users must scale user profile reads differently from post creation. CQRS ensures that reads scale independently using a read-optimized database, while writes go to a separate system.
4 - Resiliency Challenges
Resiliency refers to the system's ability to recover from failures and continue functioning. Failures in distributed systems are inevitable, so designing for graceful degradation is critical.
Resiliency Techniques:
Timeouts: Prevents waiting indefinitely for slow responses.
Retries: Retries failed requests with exponential backoff to avoid overwhelming services.
Circuit Breakers: Stops sending requests to a failing service until it recovers.
Load Shedding: Drops low-priority requests when overloaded.
Rate Limiting: Restricts API calls per second to prevent abuse.
Bulkheads: Isolate failure-prone components so they don’t crash the whole system.
Health Checks: Automatically detects and removes failing nodes.
Example Use Case:
A video streaming service must handle sudden traffic spikes during a major event. Using rate limiting to manage incoming requests, CDNs to distribute content, and health checks to remove failing servers ensures the system remains available.
👉 So - how do you handle challenges with distributed systems?
Shoutout
Here are some interesting articles I’ve read recently:
What works in a Monolith can break a microservice by Raul Junco
How Did SoundCloud Scale Its Architecture Using BFF, Microservices & DDD? by Petar Ivanov
From Parent’s Idea to Working App in 90 Minutes - The New Reality of Development by Akos Komuves
Mentoring doesn't solve all problems. The 4 people every software engineer needs to grow fast without burnout by Fran Soto
That’s it for today! ☀️
Enjoyed this issue of the newsletter?
Share with your friends and colleagues.
Understanding the challenges of distributed systems is crucial for software engineers
Thanks for the mention, Saurabh!
Amazing overview! When you break these down, I always feel I'm working on some trivial apps. 😅 Thanks for the shout-out!