
15 Must-Know Elements of System Design
Key Lego Blocks...

A well-designed system incorporates multiple architectural elements to handle distributed systems, scalability, service management, networking, data storage, and observability.
Think of these elements as Lego blocks that can help you achieve a particular task. Here are 15 system design elements divided across different areas:
1 - Distributed Systems
Distributed Systems involve breaking a system into multiple services that run across different servers or regions. This approach helps improve scalability, fault tolerance, and overall performance.
Key Components:
a) Distributed Message Queues
Message queues enable asynchronous communication between services by acting as an intermediary that stores and forwards messages.
Producers send messages to the queue, and consumers process them at their own pace.
It helps decouples microservices, allowing independent scaling. Examples include Apache Kafka, RabbitMQ, and AWS SQS.
b) Distributed Caching
Caching stores frequently accessed data in in-memory databases to improve response times.
Instead of querying a database repeatedly, applications retrieve cached data, reducing latency. This speeds up reads and reduces database load. Some examples of distributed caches are Redis and Memcached.

c) Distributed Task Scheduler
Task schedulers coordinate batch jobs and background tasks in distributed environments.
Used to execute scheduled or event-driven tasks across multiple nodes. This ensures reliable execution of critical jobs like database cleanup or email notifications. Examples include tools like Apache Airflow and Kubernetes CronJobs.
2 - Scalability and Performance
Scalability ensures a system can handle increased demand, while performance optimizations reduce latency.
Key Components:
a) Scaling Services
Scaling enables applications to adjust resources dynamically based on traffic patterns.

Types of Scaling:
Vertical Scaling: Upgrading existing servers (more CPU, RAM).
Horizontal Scaling: Adding more servers to distribute load.
Why It’s Important: Ensures smooth performance during peak loads.
Examples: Kubernetes AutoScaler, AWS Auto Scaling.
b) Content Delivery Networks (CDNs)
CDNs store cached copies of static and dynamic content in geographically distributed servers.
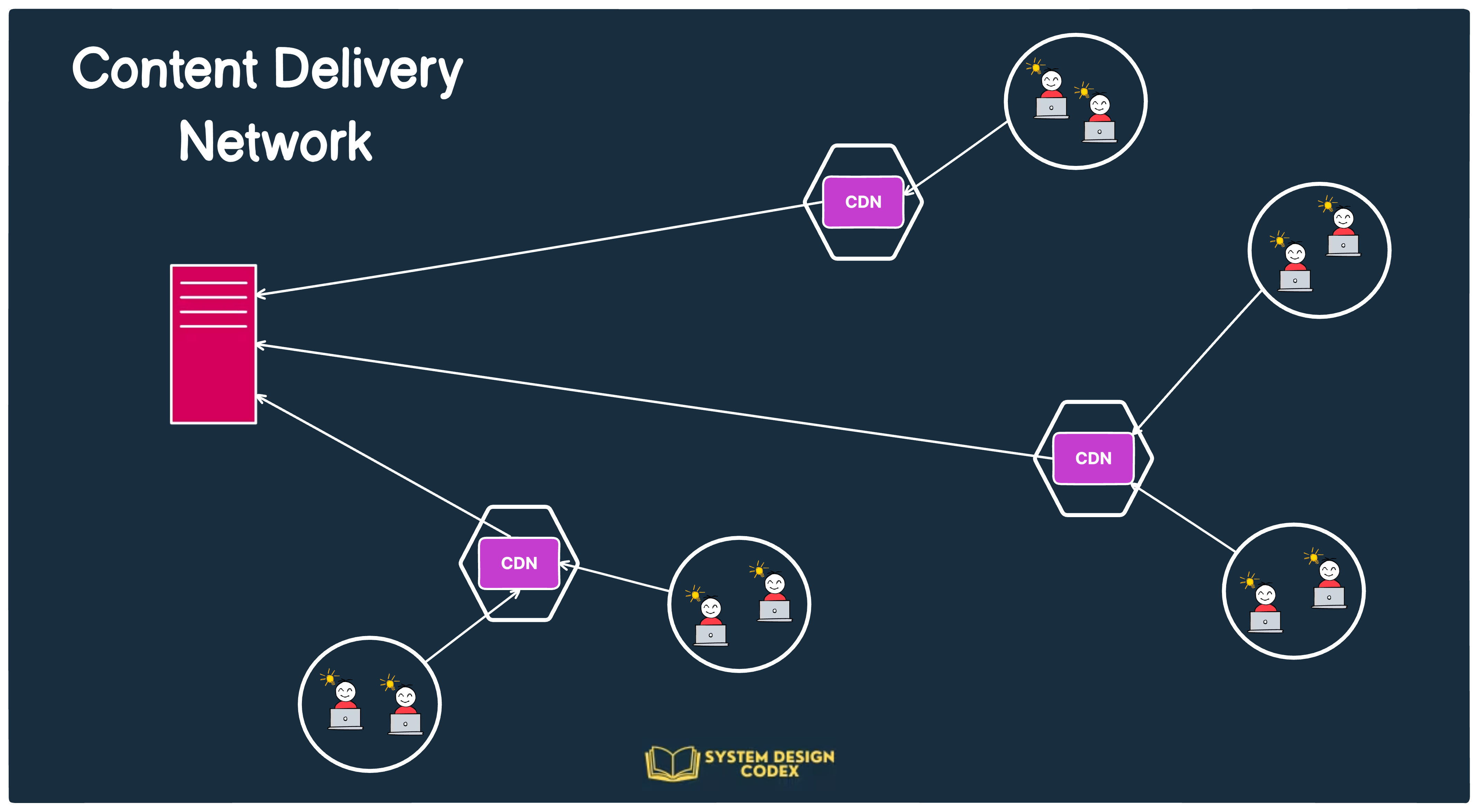
Users receive content from the nearest CDN server, reducing latency. This helps speed up page loads and reduce bandwidth costs.
Examples include Cloudflare and AWS CloudFront.
c) Consistent Hashing
Consistent hashing distributes data evenly across nodes while minimizing key remapping when nodes join or leave.

Instead of remapping all keys, only a fraction of the data needs redistribution. This helps efficiently scale distributed databases and caches. Some database that utilize Consistent Hashing are Amazon DynamoDB, Cassandra, etc.
3 - Service Management
Service management ensures smooth communication between microservices in a distributed system. One of the key system design elements involved is service discovery.

Service discovery enables microservices to find and communicate with each other dynamically.
Services register themselves and lookup happens dynamically. This eliminates hard-coded IPs, improving flexibility. Examples are Consul, Eureka, and Kubernetes Service Discovery.
4 - Networking and Communication
Networking components manage traffic routing and load distribution for better efficiency.
Key Components:
a) DNS (Domain Name System)
DNS translates human-readable domain names into IP addresses, ensuring efficient domain resolution for web applications.
Some examples are AWS Route 53 and Google Cloud DNS.

b) Load Balancer
Load balancers distribute incoming network requests across multiple backend servers.

They use algorithms like round-robin, least connections, or weighted distribution. This helps prevent overloading a single server, ensuring high availability. Some examples are NGINX and AWS Elastic Load Balancer.
c) API Gateway
An API gateway acts as a single entry point for microservices. It routes, authenticates, and rate-limits API requests.
API gateways simplify security, monitoring, and request management. Examples include Kong and AWS API Gateway.
5 - Data Storage and Management
Data storage solutions ensure efficient and scalable data persistence.
Key Components:
a) Databases
Databases manage structured or semi-structured data.
Types of Databases:
Relational (SQL): MySQL, PostgreSQL (ACID compliance, complex queries).
NoSQL: MongoDB, Cassandra (scales horizontally, flexible schema).
Why It’s Important: Choosing the right database impacts scalability and performance.
b) Object Storage
Object storage holds unstructured data like images, videos, and documents. They support high durability and availability.
Examples are Amazon S3 and Google Cloud Storage.
c) Sharding
Sharding partitions a large database into smaller, distributed shards. It helps divide data based on a key (e.g., user ID, geographic region), thereby improving horizontal scalability.
Examples of databases that support sharding are MongoDB, MySQL sharding, etc.
d) Replication
Replication creates multiple copies of a database to improve availability and fault tolerance.

Types of Replication:
Leader-Follower Reads from replicas, and writes to the primary. Critical reads can also go to the primary.
Multi-Leader: Allows writes to multiple nodes.
Why It’s Important: Ensures high availability and disaster recovery.
Examples: PostgreSQL replication, MySQL replication.
6 - Observability and Resiliency
Observability ensures visibility into system health, while resiliency mechanisms ensure the system recovers from failures.
Monitoring tools collect real-time metrics, logs, and traces to diagnose issues. This helps detect performance bottlenecks and improve debugging.
Examples include tools like Prometheus (metrics), ELK Stack (logging), and Jaeger (tracing).
👉 So - will you add any other key element to the list?
Shoutout
Here are some interesting articles I’ve read recently:
Lifelong Learning: 88+ Resources I Don't Regret as a Senior Software Engineer by Petar Ivanov
Every Backend Engineer needs to know how to deal with payments by Raul Junco
How TOP engineers structure their day to maximize their productivity without burnout by Fran Soto
That’s it for today! ☀️
Enjoyed this issue of the newsletter?
Share with your friends and colleagues.
Much needed one to save and refer whenever required. Thanks. Pls don't put this one behind subscription in future.
When we think somethings is a great resource and come back later they become subscription material. 😂
That's an awesome compilation, Saurabh!